一、boosting算法
boosting是一种集成学习算法,由一系列基本分类器按照不同的权重组合成为一个强分类器,这些基本分类器之间有依赖关系。包括Adaboost算法、提升树、GBDT算法

一、Adaboost算法
AdaBoost方法的自适应在于:前一个分类器分错的样本会被用来训练下一个分类器。AdaBoost方法是一种迭代算法,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率。每一个训练样本都被赋予一个权重,表明它被某个分类器选入训练集的概率。如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它被选中的概率就被降低;相反,如果某个样本点没有被准确地分类,那么它的权重就得到提高。通过这样的方式,AdaBoost方法能“聚焦于”那些较难分(更富信息)的样本上。虽然AdaBoost方法对于噪声数据和异常数据很敏感。但相对于大多数其它学习算法而言,却又不会很容易出现过拟合现象
算法原理
(1)初始化训练数据(每个样本)的权值分布:如果有N个样本,则每一个训练的样本点最开始时都被赋予相同的权重:1/N。
(2)训练弱分类器。具体训练过程中,如果某个样本已经被准确地分类,那么在构造下一个训练集中,它的权重就被降低;相反,如果某个样本点没有被准确地分类,那么它的权重就得到提高。同时,得到弱分类器对应的话语权。然后,更新权值后的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
(3)将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,分类误差率小的弱分类器的话语权较大,其在最终的分类函数中起着较大的决定作用,而分类误差率大的弱分类器的话语权较小,其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的比例较大,反之较小
AdaBoost的具体步骤如下:
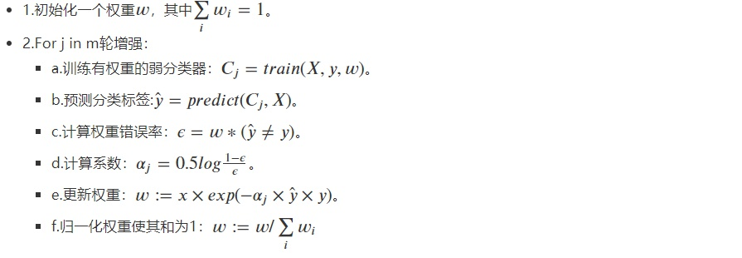
3.迭代完成后,组合弱分类器
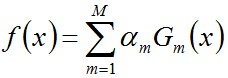
其中

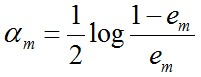
然后,加个sign函数,该函数用于求数值的正负。数值大于0,为1。小于0,为-1.等于0,为0.得到最终的强分类器


那么这个更新后的权重怎么得来的
首先错误率e=0.1*3=0.3
系数aj=0.5log(0.7/0.3)=0.42364893019360184
分别计算分类错误和分类正确的权重,由上面可知分类正确与否的权重其实只与e上面的指数的正负有关,分错的是e**aj,分对的是e**-aj,他们分别等于1.5275252316519468,0.6546536707079771
最后再归一化,比如1.5275252316519468/(1.5275252316519468*3+0.6546536707079771*7)=0.16666666666666666
Adaboost是一种比较有特点的算法,可以总结如下:
1)每次迭代改变的是样本的分布,而不是重复采样(reweight);
2)样本分布的改变取决于样本是否被正确分类,总是分类正确的样本权值低,总是分类错误的样本权值高(通常是边界附近的样本);
3)最终的结果是弱分类器的加权组合,权值表示该弱分类器的性能
Adaboost有很多优点:
1)adaboost是一种有很高精度的分类器
2)可以使用各种方法构建子分类器,adaboost算法提供的是框架
3)当使用简单分类器时,计算出的结果是可以理解的。而且弱分类器构造极其简单
4)简单,不用做特征筛选
5)不用担心overfitting!
实际应用
(1)用于二分类或多分类
(2)特征选择
(3)分类人物的baseline
1.Adaboost用于分类
函数解析
class sklearn.ensemble.AdaBoostClassifier(base_estimator=None, n_estimators=50,learning_rate=1.0, algorithm=’SAMME.R’,random_state=None)
参数解析:
1.1 base_estimator: 可选参数,默认为DecisionTreeClassifier。理论上可以选择任何一个分类或者回归学习器,不过需要支持样本权重。我们常用的一般是CART决策树或者神经网络MLP。默认是决策树,即AdaBoostClassifier默认使用CART分类树DecisionTreeClassifier,另外有一个要注意的点是,如果我们选择的AdaBoostClassifier算法是SAMME.R,则我们的弱分类学习器还需要支持概率预测,也就是在scikit-learn中弱分类学习器对应的预测方法除了predict还需要有predict_proba
1.2 n_estimators: 整数型,可选参数,默认为50。弱学习器的最大迭代次数,或者说最大的弱学习器的个数。一般来说n_estimators太小,容易欠拟合,n_estimators太大,又容易过拟合,一般选择一个适中的数值。默认是50。在实际调参的过程中,我们常常将n_estimators和下面介绍的参数learning_rate一起考虑
1.3 learning_rate: 学习率,表示梯度收敛速度,默认为1,如果过大,容易错过最优值,如果过小,则收敛速度会很慢;该值需要和n_estimators进行一个权衡,当分类器迭代次数较少时,学习率可以小一些,当迭代次数较多时,学习率可以适当放大。每个弱学习器的权重缩减系数
1.4 algorithm: 可选参数,默认为SAMME.R。boosting算法,也就是模型提升准则,scikit-learn实现了两种Adaboost分类算法,SAMME和SAMME.R。两者的主要区别是弱学习器权重的度量,SAMME使用对样本集分类效果作为弱学习器权重,而SAMME.R使用了对样本集分类的预测概率大小来作为弱学习器权重。由于SAMME.R使用了概率度量的连续值,迭代一般比SAMME快,因此AdaBoostClassifier的默认算法algorithm的值也是SAMME.R。我们一般使用默认的SAMME.R就够了,但是要注意的是使用了SAMME.R, 则弱分类学习器参数base_estimator必须限制使用支持概率预测的分类器。SAMME算法则没有这个限制
1.5 random_state: 整数型,可选参数,默认为None。如果RandomState的实例,random_state是随机数生成器; 如果None,则随机数生成器是由np.random使用的RandomState实例
Adaboost-对象
- estimators_:以列表的形式返回所有的分类器。
- classes_:类别标签。
- estimator_weights_:每个分类器权重。
- estimator_errors_:每个分类器的错分率,与分类器权重相对应。
- feature_importances_:特征重要性,这个参数使用前提是基分类器也支持这个属性。
Adaboost-方法
- decision_function(X):返回决策函数值(比如svm中的决策距离)。
- fit(X,Y):在数据集(X,Y)上训练模型。
- get_parms():获取模型参数。
- predict(X):预测数据集X的结果。
- predict_log_proba(X):预测数据集X的对数概率。
- predict_proba(X):预测数据集X的概率值。
- score(X,Y):输出数据集(X,Y)在模型上的准确率。
- staged_decision_function(X):返回每个基分类器的决策函数值。
- staged_predict(X):返回每个基分类器的预测数据集X的结果。
- staged_predict_proba(X):返回每个基分类器的预测数据集X的概率结果。
- staged_score(X, Y):返回每个基分类器的预测准确率
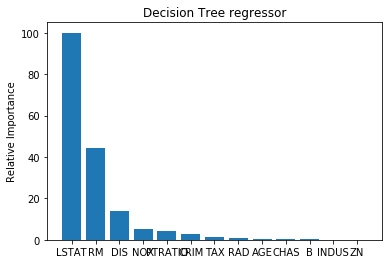
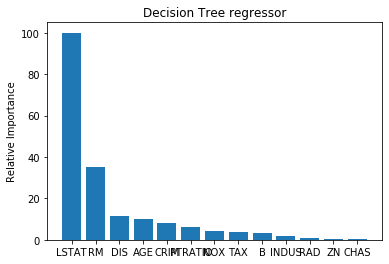
# -*- coding: utf-8 -*- """ Created on Tue Aug 11 10:12:48 2020 """ from sklearn.ensemble import AdaBoostClassifier ,AdaBoostRegressor from sklearn.datasets import load_iris x_data=load_iris().data y_data=load_iris().target from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test = train_test_split(x_data,y_data,test_size=0.3,random_state=1,stratify=y_data) #单个决策树模型 from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score tree = DecisionTreeClassifier(criterion='gini',max_depth=4,random_state=1) tree.fit(X_train,y_train) y_train_pred = tree.predict(X_train) y_test_pred = tree.predict(X_test) tree_train = accuracy_score(y_train,y_train_pred) tree_test = accuracy_score(y_test,y_test_pred) print('Decision tree train/test accuracies %.3f/%.3f' % (tree_train,tree_test)) #Decision tree train/test accuracies 0.971/0.978 ## 我们使用Adaboost集成建模: ada = AdaBoostClassifier(base_estimator=tree,n_estimators=200,learning_rate=0.2,random_state=1) ada = ada.fit(X_train,y_train) y_train_pred = ada.predict(X_train) y_test_pred = ada.predict(X_test) ada_train = accuracy_score(y_train,y_train_pred) ada_test = accuracy_score(y_test,y_test_pred) print('Adaboost train/test accuracies %.3f/%.3f' % (ada_train,ada_test)) #Adaboost train/test accuracies 1.000/0.978
2.Adaboost用于回归
参数基本一样,唯一的区别是用于回归时有loss参数,参数说明如下:

# -*- coding: utf-8 -*- """ Created on Tue Aug 11 10:12:48 2020 """ from sklearn.ensemble import AdaBoostClassifier ,AdaBoostRegressor from sklearn.datasets import load_boston x_data=load_boston().data y_data=load_boston().target from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test = train_test_split(x_data,y_data,test_size=0.3,random_state=1) #数据标准化 # 从 sklearn.preprocessing 导入数据标准化模块。 from sklearn.preprocessing import StandardScaler # 分别初始化对特征和目标值的标准化器。 ss_X = StandardScaler() ss_y = StandardScaler() # 分别对训练和测试数据的特征以及目标值进行标准化处理。 X_train = ss_X.fit_transform(X_train) X_test = ss_X.transform(X_test) y_train = ss_y.fit_transform(y_train.reshape(-1,1)) y_test = ss_y.transform(y_test.reshape(-1,1)) import numpy as np import matplotlib.pyplot as plt def plot_feature_importances(feature_importances, title, feature_names): # Normalize the importance values feature_importances = 100.0 * (feature_importances / max(feature_importances)) # Sort the values and flip them index_sorted = np.flipud(np.argsort(feature_importances)) # Arrange the X ticks pos = np.arange(index_sorted.shape[0]) + 0.5 # Plot the bar graph plt.figure() plt.bar(pos, feature_importances[index_sorted], align='center') plt.xticks(pos, feature_names[index_sorted]) plt.ylabel('Relative Importance') plt.title(title) plt.show() #单个决策树模型 from sklearn.tree import DecisionTreeRegressor from sklearn.metrics import r2_score, mean_squared_error tree = DecisionTreeRegressor(max_depth=6,random_state=1) tree.fit(X_train,y_train) y_train_pred = tree.predict(X_train) y_test_pred = tree.predict(X_test) tree.score(X_test, y_test) #0.8427465276357865 r2_score(y_train,y_train_pred) #0.9485651664023145 r2_score(y_test,y_test_pred) #0.8427465276357866 mean_squared_error(y_train,y_train_pred) #0.05143483359768557 mean_squared_error(y_test,y_test_pred) #0.17752374245868488 tree.feature_importances_ plot_feature_importances(tree.feature_importances_, 'Decision Tree regressor', load_boston().feature_names) ## 我们使用Adaboost集成建模: ada = AdaBoostRegressor(base_estimator=tree,n_estimators=200,learning_rate=0.2,random_state=1) ada = ada.fit(X_train,y_train) y_train_pred = ada.predict(X_train) y_test_pred = ada.predict(X_test) ada.score(X_test, y_test) # 0.8781684126580823 r2_score(y_train,y_train_pred) #0.9829984375151436 r2_score(y_test,y_test_pred) #0.8781684126580824 mean_squared_error(y_train,y_train_pred) #0.017001562484856434 mean_squared_error(y_test,y_test_pred) #0.13753590944260316 tree.feature_importances_ plot_feature_importances(ada.feature_importances_, 'Decision Tree regressor', load_boston().feature_names)