把有合并单元格的信息读取出来,输出所在层数与位置
我要操作的Excel是这样的
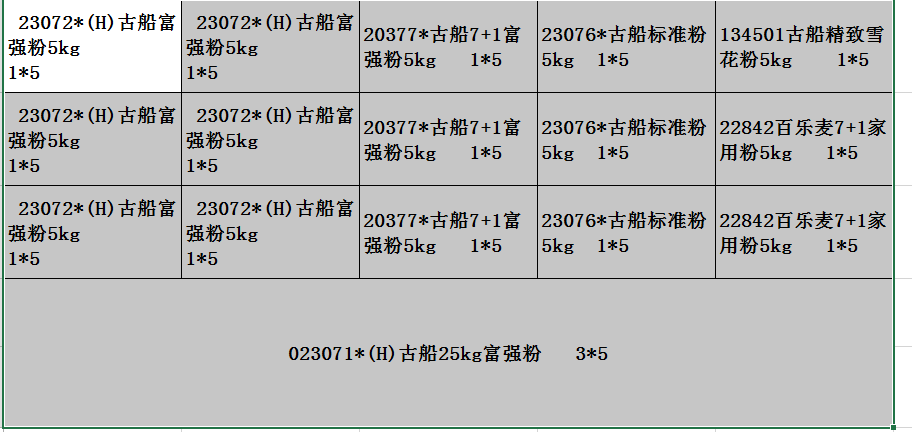
要的到的是这样的效果

# -*- coding: utf-8 -*-
import xlrd
import xlwt
r=1
# shxrange = range(bk.nsheets)
wb = xlwt.Workbook(encoding='utf-8')#创建工作簿,设置字符编码
ws = wb.add_sheet('A TEST Sheet')#创建sheet
goods = xlrd.open_workbook('test3.xlsx')#打开文件
index = 0
for sheet_index in range(goods.nsheets):
sh = goods.sheet_by_index(sheet_index)#返回第几页的对象
#添加内容到row_list当中
row_list = []
for rx in range(sh.nrows):
if sh.row(rx)[0].ctype:
print sh.row(rx)
row_list.append(sh.row_values(rx))
# 取出有多少行
row = len(row_list)
# print row
for r in range(row):
weizhi =1
for c in range(len(row_list[r])):
if row_list[r][c]:
ws.write(index, 0, row_list[r][c])
ws.write(index,3,row)
ws.write(index,4,weizhi)
index = index + 1
row =row-1
wb.save('example3.xls')
需要这样操作的数据有很多,就要分为多个sheet页,每个sheet页包含一个要操作的数据,这样的话就可以把每个sheet页重新数层数,如果不需要也可以写在一个sheet页当中,要批量处理就分多个sheet页
要处理的数据和上面差不多,不过稍微麻烦一点
要处理的数据分为两个sheet页
sheet页1
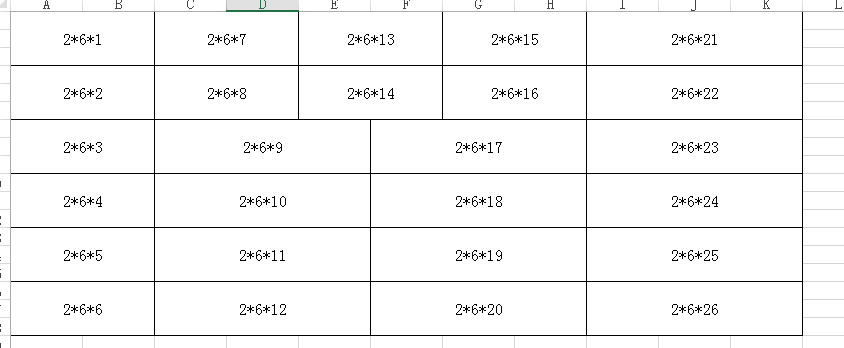
sheet页2
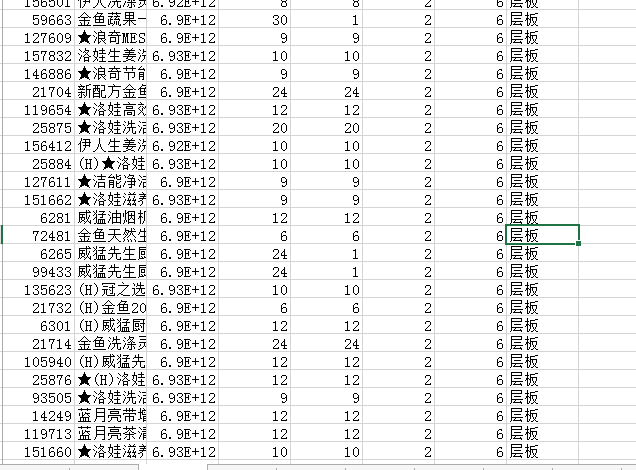
要处理的数据是通过sheet1页每个单元格数据*前面的第一个数字找到sheet2页对应的行号,这样的数据太难看了,想要得到这样的数据
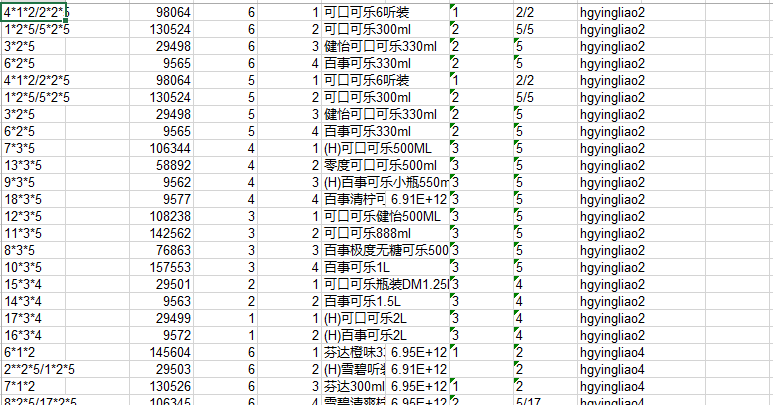
# -*- coding: utf-8 -*-
import xlrd
import xlwt
r=1
# shxrange = range(bk.nsheets)
wb = xlwt.Workbook(encoding='utf-8')#创建工作簿,设置字符编码
ws = wb.add_sheet('A TEST Sheet')#创建sheet
goods = xlrd.open_workbook('test10.xlsx')#打开文件
index = 0
sheet = 0
for sheet_index in range(goods.nsheets/2):
sh = goods.sheet_by_index(sheet)#返回第1页的对象
print sheet
#添加内容到row_list当中
row_list = []
for rx in range(sh.nrows):
#第一行为当前页的分类
if sh.row(rx)[0].ctype:
# print sh.row(rx)
row_list.append(sh.row_values(rx))
else:
# print r
r +=1
# 取出有多少行
row = len(row_list)
sheet = sheet+1
print sheet
#将第二页的内容添加到con_list当中
con_list = []
sh = goods.sheet_by_index(sheet)#返回第几页的对象
for rx in range(sh.nrows):
#第一行为当前页的分类
# if rx ==0:
# fenglei = sh.row_values(rx)
# else:
if sh.row(rx)[0].ctype:
# print sh.row(rx)
con_list.append(sh.row_values(rx))
else:
print r
r +=1
sheet=sheet+1
# print row
for r in range(row):
weizhi = 1
for c in range(len(row_list[r])):
if row_list[r][c]:
ws.write(index, 0, row_list[r][c])
# ws.write(index,10,fenglei)
ws.write(index,3,row)
ws.write(index,4,weizhi)
try:
ws.write(index,2,con_list[int(row_list[r][c].split("*")[0])-1][0])
try:
ws.write(index,5,con_list[int(row_list[r][c].split("*")[0])-1][1])
except:
ws.write(index,5,500)
try:
ws.write(index,6,con_list[int(row_list[r][c].split("*")[0])-1][2])
except:
ws.write(index,6,500)
ws.write(index,7,row_list[r][c].split("*")[1])
ws.write(index,8,row_list[r][c].split("*")[2])
ws.write(index,9,'hgyingliao'+str(sheet))
except:
ws.write(index,5,500)
ws.write(index,6,500)
ws.write(index,7,500)
ws.write(index,8,500)
ws.write(index,9,'hgyingliao'+str(sheet))
weizhi =weizhi+1
index = index + 1
row =row-1
wb.save('example3.xls')
每两个sheet页为单位进行处理