一、es数据存储简单介绍
1. 概念解释
Index:索引,它是单个数据库的同义词。
Type:索引类型,它是单个数据表的同义词。
Document:文档,它是单条数据记录的同义词。
mapping:映射,相当于数据库的表结构。
理论上一个Index可以包含多个Type,但是在实际应用中一般一个Index只包含一个Type,若包含多个Type,容易造成数据干扰等问题,有百害而无一利。
一般情况下我们是先往es中插入数据,es会自动识别各个字段类型,创建索引,然后我们再查询mapping,将mapping改成我们想要的索引结构,删除原有索引结构,手动创建索引结构。
2. es索引基本原理
es默认会为文档的所有字段建立倒排索引。
es对单个字段的值的内容进行分词,分词汇总称为Term Dictionary,Term Dictionary中各个分词都对应一个文档ID数组(Posting List),Term Dictionary是有序的,查询时可使用二分查找,查找到Term即可根据对应的文档ID数组读取文档内容了。
Posting List也是有序的,使用增量编码压缩,将大数变小数按字节存储。这样的存储方式不仅能节省存储空间,也方便多字段联合查询时多个Posting List之间进行并集操作,将各个字段查询到的Term对应的Posting List做按位与运算,即可得到最终的文档ID数组。
当数据量很大时,Term Dictionary也是很庞大的,无法全部存在内存中,所以es又加多了一层Term Index,只存储部分词的前缀,以FST的形式保存在内存中(FST以字节的方式存储了所有的Term),节省内存,检索很快。
所以es搜索数据时,先在内存中Term Index查询到对应的Term Dictionary的block位置,再去磁盘上查找Term,找到Term以后再根据对应的文档ID数组去读取文档数据。
二. es简单操作入门
注:以下操作皆是在kibana上进行的,Index为“school”,Type为“student”。
1. 插入文档
PUT /school/student/1
{
"name": "JetWu",
"age": 18,
"city": "Jieyang",
"interests": ["basketball", "badminton", "mountain climbing"],
"introduction": "I am from Jieyang. I love my hometown"
}
PUT /school/student/2
{
"name": "是啊俊",
"age": 18,
"city": "揭阳",
"interests": ["篮球", "羽毛球", "爬山"],
"introduction": "我来自揭阳,我爱我的家乡"
}
PUT /school/student/3
{
"name": "疯一样的狼人",
"age": 25,
"city": "深圳",
"interests": ["basketball", "羽毛球", "骑行"],
"introduction": "大家好,我是疯一样的狼人,我现在在深圳,大家有空可以来找我玩。"
}
2. 更新文档
PUT /school/student/1
{
"name": "JetWu",
"age": 28,
"city": "Jieyang",
"interests": ["basketball", "badminton", "mountain climbing"],
"introduction": "I am from Jieyang. I love my hometown"
}
3. 删除
(1)删除某个文档:
DELETE /school/student/1
(2)删除整个索引:
DELETE /school
4. 搜索
(1)按文档ID搜索:
GET /school/student/1
(2)搜索所有文档:
GET /school/student/_search
(3)全文搜索:
GEt /school/student/_search
{
"query": {
"match": {
"interests": "羽毛球"
}
},
"size": 2,//指定返回文档数量
"from": 0//指定位移
}
查询结果:

其中“_score”是评分,表示匹配度,从高到低排序。
(4)精确匹配:
GEt /school/student/_search
{
"query":{
"term":{
"age": 18
}
}
}
GEt /school/student/_search
{
"query": {
"terms": {
"age": [18, 28]
}
}
}
(5)范围搜索:
GEt /school/student/_search
{
"query":{
"range":{
"age": {"gt": 20}
}
}
}
(6)取消评分排序,提高性能:
GEt /school/student/_search
{
"query":{
"constant_score": {
"filter":{
"range": {
"age": {"gt": 20}
}
}
}
}
}
(7)or条件查询:
GEt /school/student/_search
{
"query": {
"match": {
"interests": "骑行 篮球"
}
}
}
搜索多个关键字的时候,es默认它们是or的关系,若想表示and关系,需借助bool和must查询。
(8)更复杂的搜索:
GET /school/student/_search
{
"query": {
"bool": {
"must": [
{"match": {
"interests": "羽毛球"
}},
{"match": {
"city" : "深圳"
}}
],
"filter": {
"range": {
"age": {
"gte": 20,
"lte": 30
}
}
}
}
}
}
bool表示搜索条件组合,可以嵌套,其语法格式如下:
{
"bool":{
"must":[],//与
"should":[],//或 满足多个,评分更高,排列靠前
"must_not":[]//否
}
}
“must”、“should”、“must_not”都可以包含多个查询条件,分别是与、或、否的关系,而这三个整体则是与的关系。
“filter”子句允许使用查询来限制将由其他子句匹配的文档,而不改变计算分数的方式。
5. 操作映射
(1)查看映射:
GEt /school/student/_mapping

插入数据时,若对应索引不存在,es会自动识别各个字段的数据类型,创建索引。
(2)设置映射:
如果es自动生成的映射不符合我们的需求,我们可以对它进行修改,删除并重新创建索引。例如:
PUT /school
{
"settings": {
"number_of_shards": 1,//分片数
"number_of_replicas": 0//复制节点数
},
"mappings": {
"student" : {
"properties" : {
"age" : {
"type" : "long"
},
"name" : {
"type" : "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"city" : {
"type" : "text",
"analyzer": "ik_max_word",//使用中文分词
"search_analyzer": "ik_max_word"
},
"interests" : {
"type" : "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"introduction" : {
"type" : "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
}
}
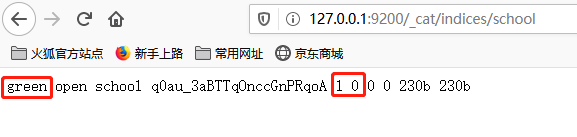
es默认的索引的分片数和复制节点数设置分别是5和1,与实际情况不符时,索引状态是“yellow”。
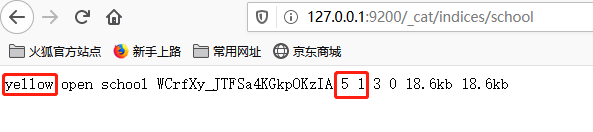
修改mapping设置,与实际情况相符以后,索引状态变成“green”。