首先为什么取这个名字呢,因为我主要是想整合几篇关于映射集合的内容,从上往下,有浅至深的讲述这个知识点
First one : Map 没有继承Collection 还是不是集合?
Map interface 是 属于集合,但此集合非彼集合,因为我所说的是,Map是一种可以储存一系列有相同定义的值,那就是集合,也就是定义集合的关键,Map具备,只不过,Map 更侧重于值之间的映射,这也是为什么他要单独出来自创天下的原因,区别于Collection下继承类储存值得方式。
Second one : Map 中常见的几个Map,及其区别?
Map 中我们常常见到主要是 HashMap , Hashtable, ConcurrentHashMap, synchronizedMap
这几个我在这里面主要写HashMap 在java中的实现,因为他的实现思想就是其他的Map实现思想精髓,其他的只是在他的基础上添加了一些自己独有的东西,来优化,提供不同业务下的多样选择性
Second one_1 HashMap 实现 +源码
用过HashMap<k, v> 都知道,浅层次的理解就是,一个k对应一个v,但是除了可以有这样一个可以储存映射关系的好处外,从结构上我们也可以挖掘一些他的优势:
1 /** 2 * The default initial capacity - MUST be a power of two. 3 */ 4 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认16 5 6 /** 7 * The maximum capacity, used if a higher value is implicitly specified 8 * by either of the constructors with arguments. 9 * MUST be a power of two <= 1<<30. 10 */ 11 static final int MAXIMUM_CAPACITY = 1 << 30; 12 13 /** 14 * The load factor used when none specified in constructor. 15 */ 16 static final float DEFAULT_LOAD_FACTOR = 0.75f; // 实际的储存空间能力 17 18 /** 19 * The table, resized as necessary. Length MUST Always be a power of two. 20 */ 21 transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE; 22 23 /** 24 * The number of key-value mappings contained in this map. 25 */ 26 transient int size; 27 28 /** 29 * The next size value at which to resize (capacity * load factor). 30 * @serial 31 */ 32 // If table == EMPTY_TABLE then this is the initial capacity at which the 33 // table will be created when inflated. 34 int threshold; 35 36 /** 37 * The load factor for the hash table. 38 * 39 * @serial 40 */ 41 final float loadFactor; 42 43 /** 44 * The number of times this HashMap has been structurally modified 45 * Structural modifications are those that change the number of mappings in 46 * the HashMap or otherwise modify its internal structure (e.g., 47 * rehash). This field is used to make iterators on Collection-views of 48 * the HashMap fail-fast. (See ConcurrentModificationException). 49 */ 50 transient int modCount;
解释一下 :
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE; 这是一个链表数组,也就是说,其实Map的结构就是一个数组,只不过这个数组的每一个值有点特殊,是一个链表形式的。
附图:
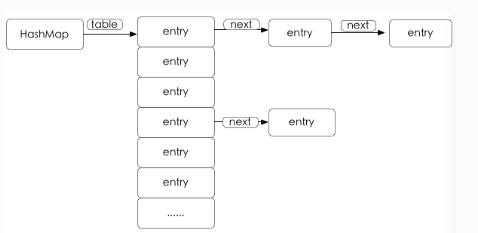
所以这个结构也是显而易见的, 再来看看其他几个属性 : (看看大神都是用的位运算来优化速度的。。。牛逼)
DEFAULT_INITIAL_CAPACITY = 1 << 4 --> 默认entry初始的个数就是16, 且一定要是2的次方数(这个原因后面讲),下面简称cap
static final float DEFAULT_LOAD_FACTOR = 0.75f; -->实际的存放数的能力,这里举个例子 : cap = 16, 这里值是0.75, 那么可以存放的size - cap * 0.75 = 12,当大于12, 那map就会执行resize(),进行2倍的扩容
transient int modCount; // 来监测fail-fast的,这个跟List里面的增删的modConut有异曲同工之处,一旦不一致,则抛出异常
然后来讲一讲map映射原理 : 为什么大多数情况下可以做到一一对应起来:
还是一样, 源码上起来 :
1 public V put(K key, V value) { 2 if (table == EMPTY_TABLE) { 3 inflateTable(threshold); 4 } 5 if (key == null) 6 return putForNullKey(value); // 允许有空值,并且将key=null的value放入table[0]中 7 int hash = hash(key); 8 int i = indexFor(hash, table.length); 9 for (Entry<K,V> e = table[i]; e != null; e = e.next) { 10 Object k; 11 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { 12 V oldValue = e.value; 13 e.value = value; 14 e.recordAccess(this); 15 return oldValue; 16 } 17 } 18 19 modCount++; 20 addEntry(hash, key, value, i); 21 return null; 22 }
final int hash(Object k) { int h = hashSeed; if (0 != h && k instanceof String) { return sun.misc.Hashing.stringHash32((String) k); } h ^= k.hashCode(); // This function ensures that hashCodes that differ only by // constant multiples at each bit position have a bounded // number of collisions (approximately 8 at default load factor). h ^= (h >>> 20) ^ (h >>> 12); // 再次hash了一遍 return h ^ (h >>> 7) ^ (h >>> 4); } /** * Returns index for hash code h. */ static int indexFor(int h, int length) { // assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2"; return h & (length-1); }
首先算出key 的hash值,通过算hash的方式,而且源码中,除了正常的hashCode以外还进行了位运算算了hash值,至于原理是什么我也不太清楚,但目的应该就是尽量减小碰撞,(碰撞就是,不同的对象算出来的hashCode一样,那就必须添加链表了),其次indexFor就是通过算出来的hash来确定在table数组中的下标位置,还是位运算,但是这个位运算其实很有意思,就是一种巧妙地取余操作, eg : h = 14, length = 16, length-1 = 15,那 进行h & (length-1) [假设8位]--> 0000 1110 & 0000 1111 = 0000 1110, 还是14 ,或者 h = 18 --> 0001 0010 & 0000 1111 = 0000 0010 为 2 ,也是余数,很神奇对吧, 其实原理就是,16 是 2^n , n = 4, 也就是二进制中会有 4个0,而它再减一,则会得到离它最近的二进制中1最多的情况,也就是15会有4个1,这是一种很特殊的情况,因为对于与操作来说,只有都是1的情况才会是1, 则这极大程度上把决定结果数字的权利交给其余的数字, 这也是这个式子的奇妙之处(清楚了是不是感觉就很简单),所以这也解释了上面的cap为什么一定会是2的次方的原因
这里补充一点 : hash相同的,但是不一定equals,equals 就是一定hash一样
差不多原理就是这样的,现在我们再来看看HashMap经常我们会说到它的线程不安全性,这是为什么?
当然单线程条件下,对于数据来说是没有任何影响,都是JVM按照Class文件中的一步一步来嘛
但是再多线程的条件下,就要考虑一下操作是不是符合ACID原则了,A 原子性, C一致性 I不可分割 D隔离性
所以一般对于HashMap来说两种方式来考虑线程不安全:
第一种 : 两个线程同时进行put 操作, 前面已经给出了put的源码 ,可以看见关键性的一句 :
addEntry(hash, key, value, i);
这句没有进行任何的上锁操作, 所以情况是两个线程,刚刚好同时有hash算出来一致的值,那很有可能会出现遗漏的情况,要不是显线程一的那个value没有插入,要么可能就是线程2的。
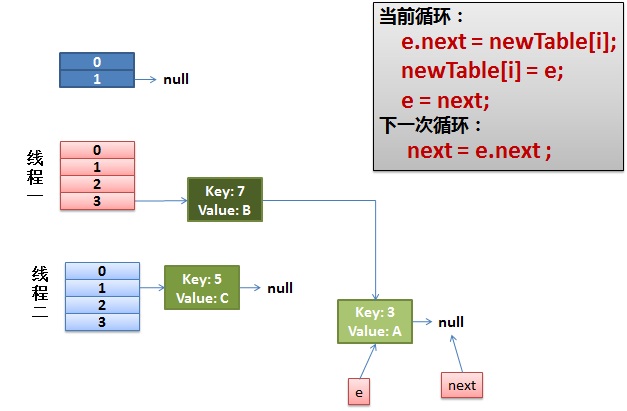
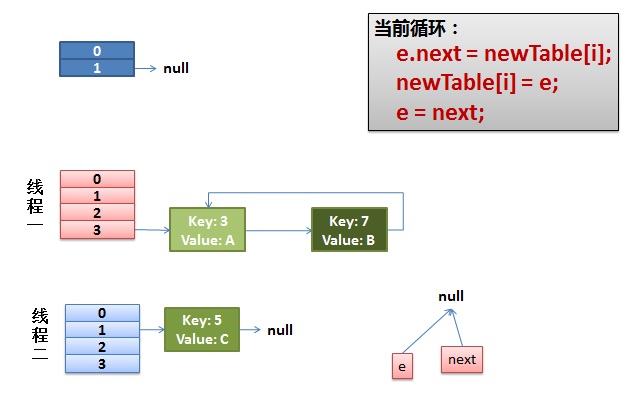
第二种 : 主要是发生在size需要扩容的情况下,会产生死循环的情况:(主要源码)
void resize(int newCapacity) { Entry[] oldTable = table; int oldCapacity = oldTable.length; if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } Entry[] newTable = new Entry[newCapacity]; transfer(newTable, initHashSeedAsNeeded(newCapacity)); table = newTable; threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); } /** * Transfers all entries from current table to newTable. */ void transfer(Entry[] newTable, boolean rehash) { int newCapacity = newTable.length; for (Entry<K,V> e : table) { while(null != e) { Entry<K,V> next = e.next; if (rehash) { e.hash = null == e.key ? 0 : hash(e.key); } int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; newTable[i] = e; e = next; } } }
在resize()操作中,有一个过渡的函数transfer ;其实会出现死循环的主要原因就在这里面,这个函数,主要是做对entry进行新的indexFor的修改索引的值,然后找到了新的容量下的table的相应的index之后,现在要移位置了,这里是关键,他是用的头节点插入链接法来链接移位的,下图所示
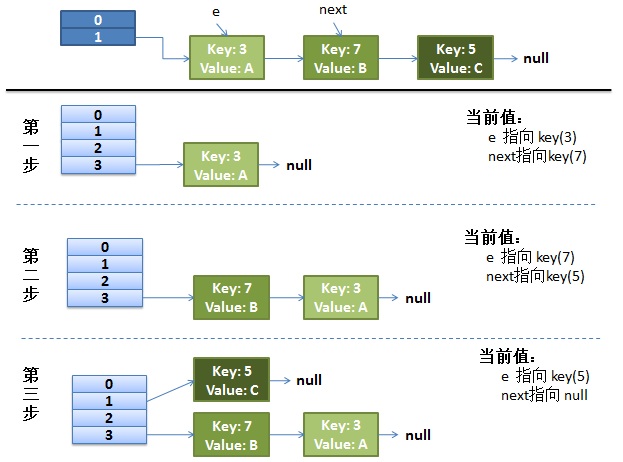
以前的3->7 现在变成了7->3
所以这样的操作很容易在多线程的情况下,出现环形连接,一个线程由3->7然后,挂起, 另外一个线程已经做完transfer操作,由7->3,这样就会形成环形连接,之后,永远get下一个值得情况,就出现异常
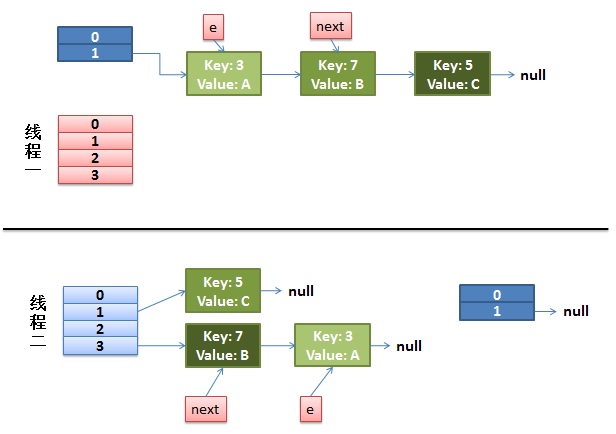
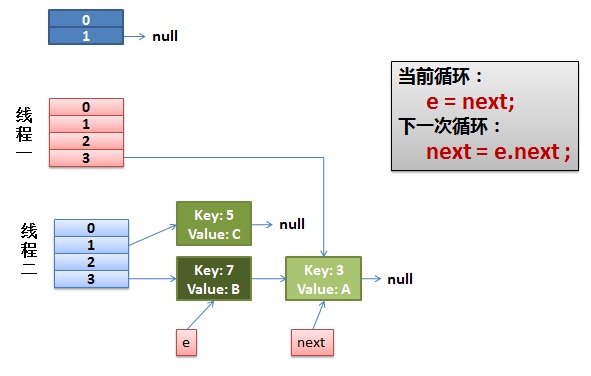
所以有这样的不足,就会有弥补的方式,有一个Hashtable和synchronizedMap 我觉得他们俩的效率都一样不是很高,因为他们都是对整张table进行的加锁 ,Hashtable的加锁对所以方法加锁 ,synchronizedMap是对Map中的一个对象进行加锁,简单展示一下:
final Object mutex; // Object on which to synchronize public int size() { synchronized (mutex) {return m.size();} } public boolean isEmpty() { synchronized (mutex) {return m.isEmpty();} } public boolean containsKey(Object key) { synchronized (mutex) {return m.containsKey(key);} } public boolean containsValue(Object value) { synchronized (mutex) {return m.containsValue(value);} } public V get(Object key) { synchronized (mutex) {return m.get(key);} } public V put(K key, V value) { synchronized (mutex) {return m.put(key, value);} } public V remove(Object key) { synchronized (mutex) {return m.remove(key);} }
所以这种效率不高,相当于同步操作了
因而 , 在current并发包中一个奇妙的优化currentHashMap就诞生了,详解可以看我的另外一篇文章,因为讲起来还是有点多,这篇已经写得挺多的了。。。