通过了解socket(int domain, int type, int protocol)接口,我们知道利用socket的AF_PACKET
或者PF_PACKET域,和类型SOCK_RAW再加上协议就可以监听获得指定协议的以太帧。
1.获得各个协议的头部
以太协议类型有很多,仅贴上一部分,如下图:
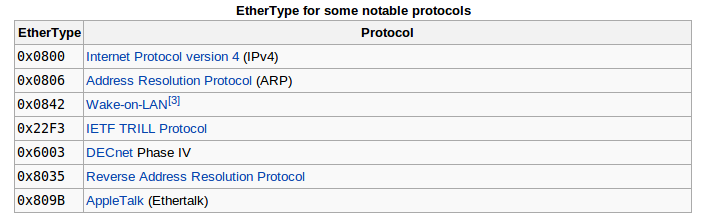
图一
更多以太类型见:http://en.wikipedia.org/wiki/EtherType
本文仅介绍0x0800(IPV4)的监听与拆分。现在我们就可以利用:
s=socket.socket(socket.PF_PACKET,socket.SOCK_RAW,socket.htons(0x0800))
获得ipv4协议的以太帧。然后就是接收,并根据协议格式拆分了。先看以太帧格式部分,如下:

图二
我们接收的数据没有Preamble部分,此部分被以太网硬件过滤掉了。这里说一下,上图Type/Length
部分是Ethernet-II才有的type,在原始的IEEE 802.3帧此部分是负载的数据长度,怎样区分的呢,数值小于
1500表示帧负载数据长度,而>=1536(十六进制0x0600)表示Ethernet-II的type(见图一ethertype的值)。
另外提一下vlan类型大小是0x8100,此类型的协议现在使用比较广泛,格式如下:

图三
vlan tag中有12bit用来表示vlan id的。此处和本文没有多少关系,主要是应用广泛介绍一下。继续正文。
我们用pkt表示接受的数据,pkt为str类型,通过图二可知用pkt[:14]包含了目的mac(6 bytes)、
源mac(6 bytes)和Type(2 bytes)。ipv4数据包封装在以太帧中,下一步看ipv4头格式:
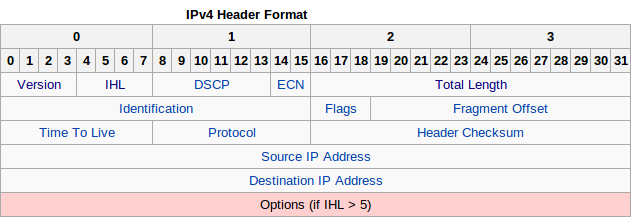
图四
了解更详细IPv4:http://en.wikipedia.org/wiki/IPv4
从图四可以知道ipv4最小长度20bytes(每行四字节,共5行),所以通过pkt[14:34]得到其头部。
由于ipv4之上有Tcp、UDP等协议,这里介绍获取的TCP数据,在ipv4头部的protocol为6时即是tcp包。
TCP header如下:

图五
Tcp头部最小也是20bytes,所以tcp_header=pkt[34:54]。
2.获得每个协议的每个字段
在此之前,要说一个问题。比如要把4存进int型的低8位,在python中这个还好说,再去取来也
没什么难度。但是如果把4存进2bytes的数中或者从保存4的2bytes str类型中获得4,就没有c等语言
简单。这里介绍struct模块,有了它,一切就简单了!我们通过如下:
tcp_h=struct.unpack("<HHIIbbHHH", tcp_header)
此方法就得到了tcp头部的个部分信息。
首先"<HHIIbbHHH"中的'<'表示开始部分,还可以是 '>'、'!' 或者 '='。H表示无符号16位,
I表示unsigned int,b表示signed char。所以HHII分别是source port(16bits)、Destination port(16bits)、
Sequence number(32bits)、Ack number(32bits)(看图五),bbHHH同理。
根据你设置的格式化字符串unpack()返回对应长度的数组,比如上面的“HHIIbbHHH”(9个字符)
就会返回长度为9的数组,并且每个元素都是int型。
同理,对于以太帧头部和ipv4头部处理与tcp header类似。
更详细的格式化字符对照如下:

3.代码实现
通过上面讲述实现主体代码如下:
1 ipv4=0x0800 2 udptype=0x11 3 tcptype=0x06 4 bufsize=1500 5 s=socket.socket(socket.PF_PACKET,socket.SOCK_RAW,socket.htons(ipv4)) 6 7 while True: 8 pkt=s.recv(bufsize) 9 if len(pkt)<=0: 10 break 11 elif len(pkt)>54: 12 ether_header = pkt[0:14] 13 ip_header = pkt[14:34] 14 ether_h = struct.unpack("!6s6s2s",ether_header) 15 ip_h = struct.unpack("<bbHHHbbHII",ip_header) 16 ip = IPv4Parser(ip_h) #做位运算等处理 17 if ip.protocol==tcptype: #判断是否为tcp包 18 tcp_header = pkt[34:54] 19 tcp_h = struct.unpack("<HHIIbbHHH", tcp_header) 20 tcp = TCPParser(tcp_h) 21 print ip.sourceip()+':'+str(tcp.sport)+'-->'+ip.destinationip()+ 22 ':'+str(tcp.dport)
16、17行用了两个类对ip和tcp头部解析,如下:
1 import os,socket 2 import struct 3 class IPv4Parser: 4 def __init__(self,ip): 5 self.ip=ip 6 @property 7 def version(self): 8 v=self.ip[0]>>4 9 return v 10 @property 11 def headerLen(self): 12 l=(self.ip[0]&0x000f)*4 13 return l
@property
def protocol(self):
return self.ip[6] 14 def sourceip(self): 15 sip=self.__getstrip(self.ip[8]) 16 return sip 17 def destinationip(self): 18 dip=self.__getstrip(self.ip[9]) 19 return dip 20 def totalLen(self): 21 return ((self.ip[2]&0xff)<<8)|((self.ip[2]>>8)&0xff)
22 def checksum(self): 23 pass 24 def __getstrip(self,intip): 25 strip=str(intip&0xff)+'.'+str((intip>>8)&0xff)+'.'+ 26 str((intip>>16)&0xff)+'.'+str((intip>>24)&0xff) 27 return strip 28 class TCPParser: 29 def __init__(self,tcp): 30 self.tcp=tcp 31 @property 32 def sport(self): 33 sp=self.tcp[0] 34 return ((sp&0xff)<<8)|(sp>>8) 35 @property 36 def dport(self): 37 return ((self.tcp[1]&0xff)<<8)|(self.tcp[1]>>8)
38 @property 39 def headerLen(self): 40 return ((self.tcp[4]>>4)&0x0f)*4
上面并没有解析ip和tcp header的所有部分,当然你可以补全,解析头部注意字节序。
把上面两处代码放在一个文件中没意外就可以运行了,注意需要root权限。运行输出的
信息如下,当然也可以输出更详细的信息。
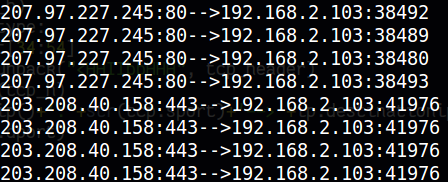
我们完全可以更进一步,对于tcp上层的协议比如http继续解包。