博客开头给出了个人信息:
- 学号2018*****7124
- 姓名:武超
博客开头给出了代码仓库的地址:
https://gitee.com/wuchao124/team-6-1566462
给出你的各项任务完成时间估算与实际消耗时间表。
|
PSP个人流程 |
我的估计 |
实际情况 |
|
• 代码规范 |
10分钟 |
15分钟 |
|
• 代码 |
2天 |
3天 |
|
• 测试(包括自测,修改代码,提交修改) |
4小时 |
3小时 |
|
记录用时 |
10分钟 |
10分钟 |
|
时间总结 |
2天4小时20分钟 |
3天3小时25分钟 |
设计程序的思路。
- 统计文件有多少个字符,包括空格制表符换行符等。
- 统计文件的有效行数,含非空白字符的行的数量,也就是跳过 空行 的行数。
- 统计单词的总数,本题中“单词”的定义是:
- 以4个英文字母 A-Z,a-z 开头,后续可以是字母和数字A-Z, a-z,0-9。good123是一个单词,123good不是一个单词。(换言之,如果有一行内容是123good,那么“单词”是good。)
- 分割符是非字母数字符号,空格。
- 不区分大小写,例如file和FILE是同一个单词。
- 统计文件中各单词的出现次数,然后输出频率最高的10个,单词定义同上,按照如下格式输出:频率相同的单词,优先输出字典序靠前的单词。
统计文件的字符数:难度系数较低,在不考虑汉字的情况下,只需要记录读入字符的数量即可。
-** 统计文件的有效行数:**初步设想有效行只需判断该行有非空字符,且以换行符结尾或者文件结尾。
统计文件的单词总数:
- 要求单词至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。只需要连续确定4个英文字符后,再遇上分割符确定一个单词,然后记录即可。
- 分割符的定义是非字母数字符号,例如!@#¥%……&*还有空格、转义字符、换行符。
统计文件中各单词的出现次数:把每个单词记录下来,出现相同单词的时候对应的值增加1。并且由于单词不区分大小写,在记录单词前必须将其转换成小写字母(输出的单词统一为小写格式)。由于采用map容器,输出即可按照字典序。
单元测试的思路。
生成测试类
断点检查错误
单行运行断点
检查bug
回归测试
给出你的效能分析报告。
- 统计概要

2.CPU运行曲线:
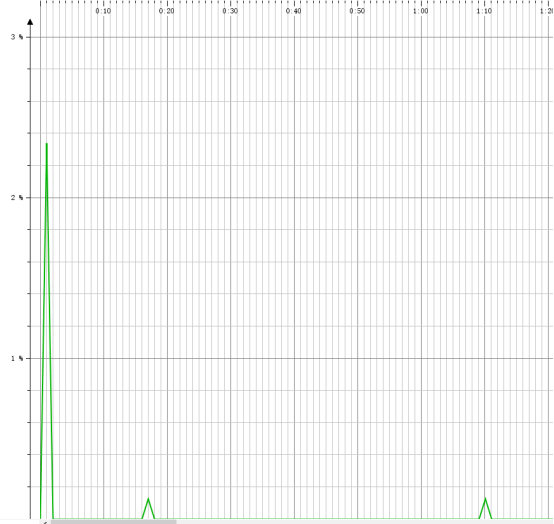
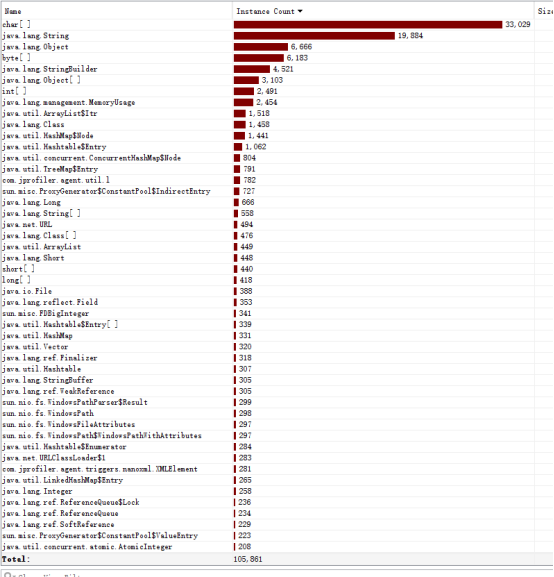
3.内存占用情况:char数组占用较大,其原因也是读入文件进行处理必须的。String和lang.Object,lang.Sting等也是创建了比较多的实例,如果可以的话可以尝试减少实例化数量
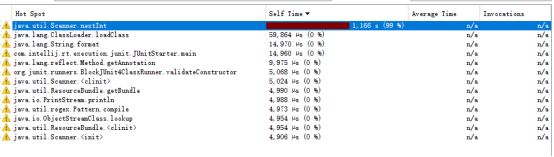
4.函数运行时间和调用次数统计.
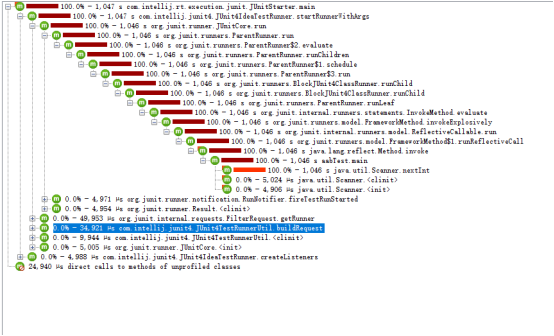
5.详细一些的高占比时间的函数运行统计排序,其他高占比函数也包括字符串处理函数。
代码片段

