2.3激活函数
sigmoid函数
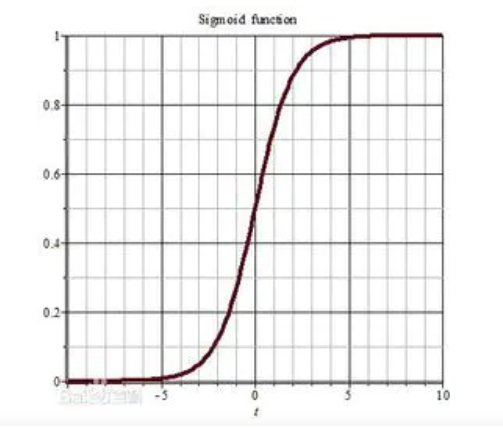
f(x)= 1/(1 + e^-x)
tf.nn.sigmoid(x)
特点:(1)求导后的数值在0-0.25之间,链式相乘之后容易使得值趋近于0,形成梯度消失
(2)输出非0均值。收敛慢
(3)幂运算复杂,训练时间长
tanh函数
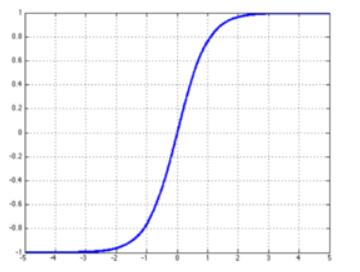
f(x)=(1-e^-2x)/(1+e^-2x)
tf.math.tanh(x)
特点:(1)输出是0均值
(2)导数值在0-1之间,容易造成梯度消失
(3)幂运算复杂,训练时间长
relu函数
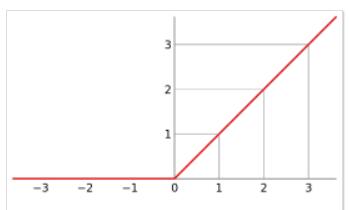
f(x) = max(x,0) = {0,x<0
{x,x>0
tf.nn.relu(x)
优点:
(1)解决了梯度消失的问题(在正区间内)
(2)只需判断是否大于0,计算速度快
(3)收敛速度远远快于以上两个函数
缺点:
(1)输出非0均值。收敛慢
(2)Dead Relu问题,某些神经元永远不会被激活,导致相应的参数不被更新
建议:
首选relu
学习率设置较小值
输入特征标准化,即输入特征满足以0为均值,1为标准差的正态分布
初始参数中心化,即让随机生成的参数满足以0为均值,sqart(2/当前层输入特征个数)为标准差的正态分布