一、简述:
1、不设置
如果不设置-m,--memory和--memory-swap,容器默认可以用完宿舍机的所有内存和 swap 分区。不过注意,如果容器占用宿主机的所有内存和 swap 分区超过一段时间后,会被宿主机系统杀死
2、设置-m,--memory,不设置--memory-swap
如果在容器中运行一个一直不停申请内存的程序,你会观察到该程序最终能占用的内存大小为 2a。
比如$ docker run -m 1G ubuntu:16.04,该容器能使用的内存大小为 1G,能使用的 swap 分区大小也为 1G。容器内的进程能申请到的总内存大小为 2G。
3、Memory reservation
这种 memory reservation 机制不知道怎么翻译比较形象。Memory reservation 是一种软性限制,用于节制容器内存使用。给--memory-reservation设置一个比-m小的值后,虽然容器最多可以使用-m使用的内存大小,但在宿主机内存资源紧张时,在系统的下次内存回收时,系统会回收容器的部分内存页,强迫容器的内存占用回到--memory-reservation设置的值大小。
docker run -it -m 500M --memory-reservation 200M ubuntu:16.04 /bin/bash
如果容器使用了大于 200M 但小于 500M 内存时,下次系统的内存回收会尝试将容器的内存锁紧到 200M 以下。
4、OOM killer
默认情况下,在出现 out-of-memory(OOM) 错误时,系统会杀死容器内的进程来获取更多空闲内存。这个杀死进程来节省内存的进程,我们姑且叫它 OOM killer。我们可以通过设置--oom-kill-disable选项来禁止 OOM killer 杀死容器内进程。但请确保只有在使用了-m/--memory选项时才使用--oom-kill-disable禁用 OOM killer。如果没有设置-m选项,却禁用了 OOM-killer,可能会造成出现 out-of-memory 错误时,系统通过杀死宿主机进程或获取更改内存。
下面的例子限制了容器的内存为 100M 并禁止了 OOM killer:
$ docker run -it -m 100M --oom-kill-disable ubuntu:16.04 /bin/bash
二、案例
OOM排查
背景:
微服务架构,几百个服务,运行在不同的容器上,总是莫名的同时出现十几个服务不可用,伴随着各个容器的状态异常,无法ping通,无法ssh上去,大量告警。。。总是莫名的有物理机宕机,每次查的时候总是无疾而终
1、大量的容器无法ping通,登录上主机,查看资源抢占情况*(示例图):
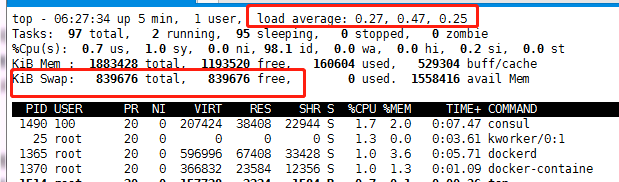
在以上的图中,主要看四个指标,一个是load,Emmm,假设CPU是56个,实际的load值达到了3K,那么这个时候,系统已经不堪重负了;
一个是Tasks,主要看任务的运行数量,在图中,才2个在运行,实际也就几百个,但是sleeping状态的有几万个,而zombie状态的有300多个;
一个就是内存的使用量,在实际情况中,内存基本使用完毕;最后一个就是使用交换空间,图中的未使用,实际上已经全部使用完毕
CPU的load太高,那么说起来其实也就两个队列,一个是运行的队列,一个block的队列,从而需要收集相关的进程信息,从而可以使用ps来查看进程的状态信息
1、查看R状态,D状态和Z状态的进程
ps h -eo pid,state,ucmd,start | awk '{if ($2=="D"||$2=="R"){print $0}}' | grep -v ps| sort | uniq -c |sort -nr -k1
2、查看所有R状态,D状态的线程
ps -eL h o pid,state,ucmd | awk '{if ($2=="D"||$2=="R"){print $0}}' | grep -v ps| sort | uniq -c |sort -nr -k1
-e 查看所有进程,等价于-A
-o 自定义输出格式
-f 全部列出,列出每个进程更详细的信息
-L 显示线程


以上主要是为了统计:一个是进程的数量,一个是线程的数量。。。(需要多次执行,从而进行对比,可以知道哪些进程造成了相关的阻塞,数量庞大的必有蹊跷。。),统计的结果是大量状态为D的进程。。。在线程多的结果中,可以看到相关的PID,从而可以知道是哪个进程产生了大量的阻塞
统计容器的数量,从容器的内存限制来查看是否容器的内存都达到了限制

排查相关的日志:
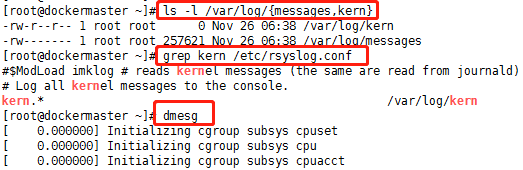
在日志里面查看到大量的OOM信息,也就可以看到相关的进程被杀死,从而可以找到是哪些进程导致了内存泄漏,从而进行整改。。。在kern日志中可以看到被杀死的进程名,在dmesg中可以看到OOM,在message中,能追查到相关的容器id
总结:
排查思路:根据load值偏高,查询进程的数量和线程的数量,从而从增加的数量查看到是什么样的进程阻塞了CPU的调度,查看系统日志,主要查看oom,从而对比两者的结果进程是否一致,从而看哪个进程OOM需要整改。。
疑问:
在以上的问题追踪中,可以产生两个疑点:第一既然oom都杀死了进程,为什么内存还会溢出,杀死了进程应该已经将相关的内存进行回收了;第二:是什么导致了那么高的load值
回答第一个问题就是:在oom killer进行杀死进程的时候,使用的是kill -9 ,从而能强行杀死进程,但是在进行oom的时候,oom的分值是给占用内存大的进程,而这个进程在等待IO,也就是等待分配内存,Emm。。。读取内存也是一种IO,所谓的缺页中断。。。在杀死这个进程的时候,这个进程的状态为D,也就是表示这个进程是不可中断睡眠,在等待分配内存。。。从而杀死这个进程可能根本就无法杀死。。。
还有一种情况是,进程已经变成了僵尸进程,从而在oom killer在进行杀死进程的时候,根据当前的进程号id杀,而僵尸进程要想杀死,必须杀掉其父进程,而当僵尸进程的父进程为1的时候,这个时候就相当于服务器重启了