《深入理解Java虚拟机》第十二章
物理机硬件的效率与一致性
处理器、高速缓存、主内存关系:为解决存储设备IO与处理器运算速度的巨大差距,增加了一个高速缓存,每个处理器都有自己的高速缓存,所有处理器共用一个主内存,
导致的问题:多个处理器运算任务涉及到同一块主内存区域时,将可能导致各自缓存数据不一致,同步到主存就会导致数据错误,所以处理器运算涉及到同一块主存区域时要遵守一些协议。

另,除了高速缓存,为了处理器内部运算单元能尽量被充分利用,处理器可能会对输入代码进行乱序执行优化,然后对结果重组保证与最终结果一致。Java中即时编译器中也有类似的指令重排序优化。
Java内存模型
Java定义了一种Java内存模型(虚拟机)来屏蔽掉不同物理机硬件和操作系统内存的访问差异。(移植性)
实现:定义了一系列在虚拟机中将变量存储到内存,内存中取出变量的的规则(这里的变量不包含线程私有的内存:局部变量+方法参数)
主内存:所有变量存储到主内存(可以物理机的主内存类比,但此处仅是虚拟机内存的一部分)
工作内存:每个线程都有自己的工作内存(可以与物理机中高速缓存相比,即:工作内存缓存了被当前线程使用到的变量的主内存,注意:缓存的是对象的引用或者对象中某个在线程中访问到的变量,不会有虚拟机把整个对象缓存一次)。

主内存和工作内存与Java堆、虚拟机栈、方法区不是同一个层次上的划分。
主内存:Java堆中对象实例数据部分。
工作内存:虚拟机栈中的部分区域。
主内存对应于物理机物理硬件的内存,虚拟机可能会让工作内存优先存储于寄存器和高速缓存中。程序运行时主要访问读写时工作内存。
主内存与工作内存的交互协议
虚拟机保证了以下每种操作的原子性。
lock:作用于主内存的变量,线程独占。
unlock:作用于主内存的变量,接触线程独占。
read:作用于主内存的变量,从主内存中读取数据。
load:作用于工作内存的变量,载入上面从主内存中读取到的数据。
use:作用于工作内存的变量,将变量处理给执行引擎(虚拟机执行需要使用到变量的字节码指令时将会执行此操作)
assign:作用于工作内存的变量,将执行引擎的操作后的值赋值给工作内存中的变量(虚拟机执行需要给变量赋值的字节码指令时将会执行此操作)
store:作用于工作内存的变量,将工作内存的变量存储(读取)到主内存
write::作用于主内存的变量,将store中得到的工作内存变量放入主内存变量中。
上面操作按顺序执行但不保证连续执行,readA readB loadA loadB,另外,Java内存模型还定义了8中基本操作必须满足的规则
1.read/load及store/write各自需要成对出现。
2.不允许线程丢弃最近的assign操作,必须同步回主内存
3.没有assign操作时,不允许线程store,write操作,即不允许无原因的同步工作内存到主内存
4.一个新的变量只能在主内存中诞生,不允许在工作内存中直接使用一个未被初始化(load或assign)的变量,一个线程对变量实施use、store操作之前,必须先执行过load或assign操作。
5.一个变量同一时刻只允许一个线程对其执行lock操作,可以被这个线程lock多次,此时,lock次数=unlock次数,变量才会解锁。
6.对一个变量执行lock操作,会清空工作内存中此变量的值,即一个线程执行lock操作,所有线程的工作内存中会删除缓存。
7.线程不允许对没有lock操作的变量执行unlock操作,也不允许unlock一个被其他线程lock的变量
8.对一个变量unlock操作之前,线程必须把此变量同步(write)回主线程
volatile关键字
两种特性:
1、保证此变量对所有线程可见性:一条线程修改了变量的值,新值对于其他线程来说是可以立即得知的。线程-回写->主内存-更新到->其他线程
可见性不能保证并发下的安全:(没有更新到执行引擎)
例:线程A把一个变量写到执行引擎(操作数栈?)后,某线程B修改了这个变量,会通知到线程A,线程A的工作内存会更新,但是执行引擎不会更新,导致做运算的值是旧值,线程不安全。
所以使用volatile要达到线程安全还需要满足:(不入执行引擎,或者入了执行引擎后得出变量对线程无用)
- 运算结果并不依赖变量的当前值,或者能够确保只有单一的线程修改了变量的值。
- 变量不需要与其他状态变量共同参与不变约束。
2、禁止指令重排序优化
多了volatile汇编会多一句lock add1 $0x0,(%esp),lock前缀导致可见性,后面指令把修改同步到内存相当于一个内存屏障,保证指令之前所有操作都已经执行完毕。
volatile变量需要满足的规则:
- use前必须read+load
- store前必须assign
- 线程V对变量V 执行A:use或assign F:load或store Pread或write,线程T对变量W 执行B:use或assign G:load或store Q read或write,如果A先与B,P先于Q
long和double是64位,内存中的操作不是原子性的,但允许并强烈建议虚拟机实现时将它们实现为原子操作。
- 原子性:8种基本操作,不可再分的
- 可见性:一个线程修改变量对其他线程可见
- 有序性:禁止指令重排序
lock/unlock-->monitorenter/monitorexit-->synchronized
线程实现
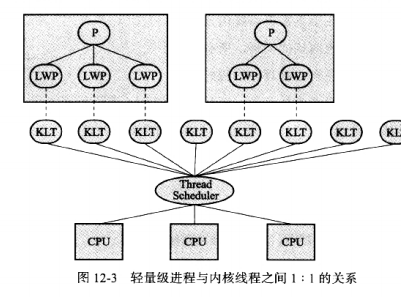
内核线程:
CPU:CPU内核
ThreadScheduler:线程调度器
KLT:内核线程
LWP:轻量级进程
P:用户态
用户线程:
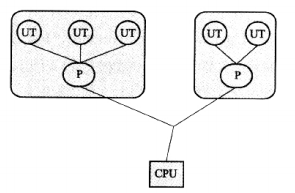
UT:用户线程
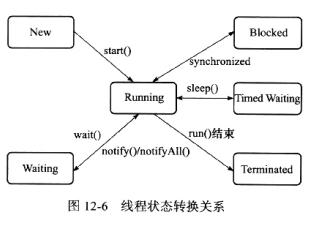
线程状态转换: