emm~ 写这篇博客只是手痒,因为开发环境用单节点就够了,生产环境肯定是真实集群,所以这个伪分布式纯属娱乐而已。
配置HDFS
1. 安装好一台hadoop,可以参考这篇博客。
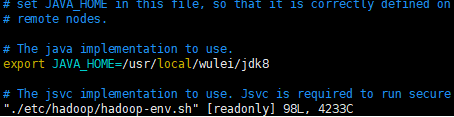
2. 在hadoop目录下编辑文件指定java环境变量 vim ./etc/hadoop/hadoop-env.sh
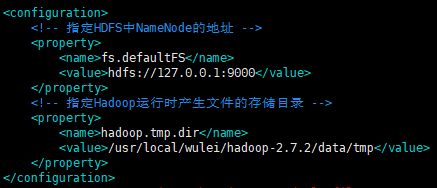
3.指定hdfs存储位置和地址 vim etc/hadoop/core-site.xml


<configuration> <!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://127.0.0.1:9000</value> </property> <!-- 指定Hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/wulei/hadoop-2.7.2/data/tmp</value> </property> </configuration>
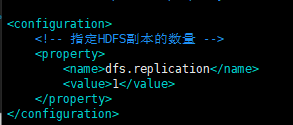
4. 指定hdsf副本数量 vim etc/hadoop/hdfs-site.xml
<configuration> <!-- 指定HDFS副本的数量 --> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
启动集群
(a)格式化NameNode(第一次启动时格式化会生成刚刚指定的data目录,以后就不要总格式化。格式化会让集群找不到已往数据datanode启动失败,所以一定要先删除data文件夹和log文件夹,然后再格式化)
[root@node1 hadoop-2.7.2]# bin/hdfs namenode -format
(b)启动NameNode
[root@node1 hadoop-2.7.2]# sbin/hadoop-daemon.sh start namenode
(c)启动DataNode
[root@node1 hadoop-2.7.2]# sbin/hadoop-daemon.sh start datanode
jps查看节点启动状态
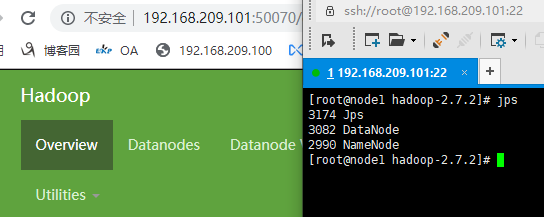
配置YARN
1.指定环境变量 vim etc/hadoop/yarn-env.sh

2.配置环境变量 vim etc/hadoop/mapred-env.sh

3.配置(node1是当前主机名,可以 vim /etc/hosts 指定) vim etc/hadoop/yarn-site.xml
<!-- Reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>node1</value> </property>
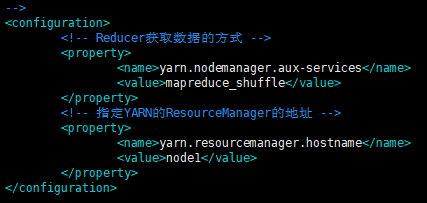
4.将mapred-site.xml.template重新命名为 mapred-site.xml
[wulei@node1 hadoop-2.7.2]$ sudo cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml [wulei@node1 hadoop-2.7.2]$ sudo vim etc/hadoop/mapred-site.xml <configuration> <!-- 指定MR运行在YARN上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>

启动集群
1. 启动前必须保证NameNode和DataNode已经启动
[root@node1 hadoop-2.7.2]# jps
12133 NameNode
12203 DataNode
12303 Jps
2. 启动ResourceManager
[root@node1 hadoop-2.7.2]# sbin/yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /usr/local/wulei/hadoop-2.7.2/logs/yarn-root-resourcemanager-node1.out
3. 启动NodeManager
[root@node1 hadoop-2.7.2]# sbin/yarn-daemon.sh start nodemanager
starting nodemanager, logging to /usr/local/wulei/hadoop-2.7.2/logs/yarn-root-nodemanager-node1.out
[root@node1 hadoop-2.7.2]# jps
12609 NodeManager
12371 ResourceManager
12133 NameNode
12203 DataNode
12750 Jps
[root@node1 hadoop-2.7.2]#