在R中,summary()是一个基础包中的重要统计描述函数,同样的在dplyr中summarise()函数也可以对数据进行统计描述。
不同的是summarise()更加的灵活多变,下面来看下summarise这个函数
summarise(.data, ...)
其灵活性和其他dplyr函数一样,主要在于条件的使用上
下面看些具体的例子
library(dplyr)
x<-data.frame(id=1:6,
name=c("wang","zhang","li","chen","zhao","song"),
shuxue=c(89,85,68,79,96,53),
yuwen=c(77,68,86,87,92,63))
x

summarise(x,sum(shuxue))

可以很好的配合聚合函数一起使用
summarise(group_by(x,name),sum(shuxue))

这里由于每个name对应的shuxue只有一个参数,所以sum的结果没变化。
summarise(group_by(x,name),sum(shuxue,yuwen))

可以看出shuxue和yuwen求和后的数据。
arrange(summarise(group_by(x,name),qiuhe=sum(shuxue,yuwen)),desc(qiuhe))

配合上前面的函数,就可以对求和后的数据进行排序,当然上面数据的可读性较低。
把他分为两个步骤,理解起来可能会相对比较容易。
y<-summarise(group_by(x,name),qiuhe=sum(shuxue,yuwen)) 求和过程
arrange(y,desc(qiuhe)) 排序过程
summarise(x,mean(shuxue),sd(shuxue))

求均值和方差
summarise(group_by(x,name),a=n(),b=a+2)

配合你n()可以对每个因子的出现次数进行统计。
summarise_all(group_by(x,name),mean)

对所有列按照name分组后求平均值
summarise_if(x,is.numeric,mean)

对所有是数值的列求平均值
summarise_at(x,c(3,4),mean)

对特定的列求平均值
类似结果的表达方式有:
summarise_at(x,vars(shuxue,yuwen),mean)
summarise_at(x,c("shuxue","yuwen"),mean)
summarise_all(select(x,c(1,3,4)),funs(min,max,mean,sum,sd))
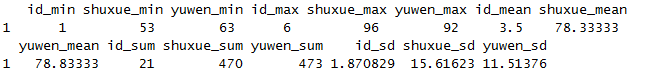
使用funs,对数据进行多重聚合统计。
summarise_each(x[c(1,3,4)],funs(mean,sum))
summarise_each也可以达到类似的效果。