1.Stack
1051 Pop Sequence (25分)
简答的栈模拟题,只要把过程想清楚就能做出来。
扫描到某个元素时候,假如比栈顶元素还大,说明包括其本身的在内的数字都应该入栈。将栈顶元素和序列比对即可,相同则弹栈,继续扫描;否则无法生成满足条件的序列。注意栈满时不能入栈


#include <cstdio> #include <cstring> #include <algorithm> using namespace std; const int maxn = 1e3+100; int m, n, q, a[maxn], sta[maxn]; bool flag; int main(){ scanf("%d%d%d", &m, &n, &q); while(q--){ for(int i = 1; i <= n; i++) scanf("%d", &a[i]); int k = 1, max_num = 0, t = 0; flag = true; while(k<=n){ while(max_num<a[k]&&t<m) sta[++t] = ++max_num; if(sta[t]==a[k]) t--, k++; else{ flag = false; break; } } if(flag) printf("YES "); else printf("NO "); } }
2.Queue
1056 Mice and Rice (25分)
这题意我看了很久都没明白,后来看到别的博客才知道是什么意思,才开始动手写
题目的要求是让你模拟一场比赛,n个参赛选手,k人一组,最后的不足k人也视为一组。然后每轮比赛决出一个冠军,进入下一组,直到最后只剩下一个人。所有在同一轮比赛中输掉的人排名相同。
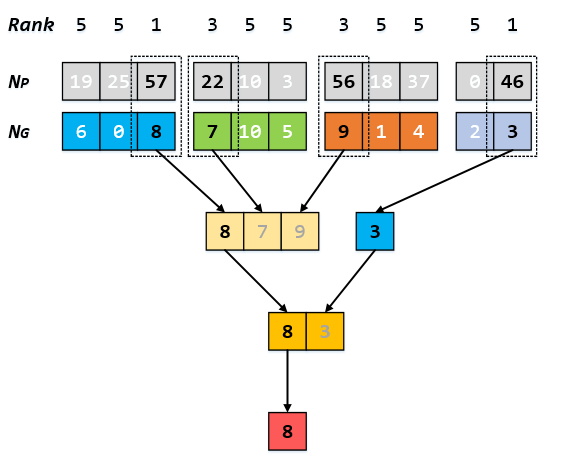
我的思路是将参赛者排入优先队列,得出每场比赛优胜者继续分入优先队列,重复上述过程得出冠军,中途记录每个人所处的轮次。之后可以根据每个人所处的轮次得到他的排名。能解决上述的两个小点这题就搞定了,但是我还是卡了很久,调试的时候有点粗心。
#include <cstdio> #include <cstring> #include <string> #include <algorithm> #include <iostream> #include <map> #include <queue> #include <cmath> #define ll long long #define inf 0x3f3f3f #define pii pair<int, int> using namespace std; const int maxn = 1e3+100; priority_queue<pii, vector<pii>, less<pii> >que[maxn]; int n, m, a[maxn]; int id, rnd[maxn], cnt[maxn]; int main(){ scanf("%d%d", &n, &m); for(int i = 0; i <= n-1; i++) scanf("%d", &a[i]); for(int i = 0; i <= n-1; i++){ scanf("%d", &id); que[i/m].push({a[id], id}), rnd[id]++; } int l = 0, r = (n-1)/m; while(l<r){ //cout << l << " " << r << endl; for(int i = l; i <= r; i++){ pii P = que[i].top(); que[(i-l)/m + r+1].push(P), rnd[P.second]++; // cout << P.second << " "; } // cout << endl; int tmp = (r-l)/m; l = r + 1, r = tmp + l; } int maxRound = ++rnd[que[r].top().second]; for(int i = 0; i <= n-1; i++) cnt[rnd[i]]++; for(int i = maxRound-1; i >= 1; i--) cnt[i] += cnt[i+1]; for(int i = 0; i <= n-1; i++) printf("%d ", cnt[rnd[i]+1]+1); }
reference:
https://blog.csdn.net/CV_Jason/article/details/85238006
https://www.nowcoder.com/questionTerminal/667e3c519c30492fbb007fbb42f44bff
3.String
1060 Are They Equal (25分)
这题有点把我恶心到了,得分确实不是很难,但是要把分拿全还是有很多地方需要去考虑的。按照算法笔记的样例测试下自己的代码,后来改了很久才过了,这本书确实还挺那不错的,给了很多指导。之后有空的话,可以根据书中的知识点稍作总结。
题目大意是说将两个数改写成科学计数法的形式,然后判断他们是否相等。根据科学计数法的定义,只需要判断本体部分和指数是否相等即可。这样一来问题就转化成如何求给定浮点数的本体部分和指数。本体部分自然是要去掉前导0,这是关键。指数部分的话需要分三种情况,一种是0.0001345这种,指数为负数;一种是1234.678,指数为正数,一种是0.0000,指数为0;需要细心对这几种情况进行处理。
#include <cstdio> #include <cstring> #include <string> #include <algorithm> #include <iostream> #include <map> #include <queue> #include <cmath> #define ll long long #define inf 0x3f3f3f #define pii pair<int, int> using namespace std; const int maxn = 1e3+100; int n, num1, num2; string s1, s2; int main(){ cin >> n >> s1 >> s2; int len1 = s1.length(), len2 = s2.length(), p1 = s1.find('.'), p2 = s2.find('.'); if(p1==-1) num1 = s1.length(); else num1 = p1, s1.erase(p1, 1); if(p2==-1) num2 = s2.length(); else num2 = p2, s2.erase(p2, 1); int tmp1 = n - num1, tmp2 = n - num2; while(tmp1>0) s1.insert(s1.end(), '0'), tmp1--; while(tmp2>0) s2.insert(s2.end(), '0'), tmp2--; //cout << s1 << " " << s2; if(s1.substr(0, n)==s2.substr(0, n)) cout << "YES 0." << s1.substr(0, n) << "*10^" << num1 << endl; else cout << "NO 0." << s1.substr(0, n) << "*10^" << num1 << " 0." << s2.substr(0, n) << "*10^" << num2; }
#include <cstdio> #include <cstring> #include <string> #include <algorithm> #include <iostream> #include <map> #include <queue> #include <cmath> #define ll long long #define inf 0x3f3f3f #define pii pair<int, int> using namespace std; int n, e1, e2; string s1, s2, s3, s4; string deal(string s, int &e){ //cout << s << " "; while(s[0]=='0') s.erase(s.begin()); if(s[0]=='.'){ s.erase(s.begin()); while(s[0]=='0') s.erase(s.begin()), e--; if(s.length()==0) e = 0; } else { e = s.find('.'); if(e==-1) e = s.length(); else s.erase(e, 1); } int tmp = n - e; while(tmp>0) s.insert(s.end(), '0'), tmp--; //cout << s << endl; return s.substr(0, n); } int main(){ cin >> n >> s1 >> s2; s3 = deal(s1, e1); s4 = deal(s2, e2); //cout << s3 << " " << s4; if(s3==s4&&e1==e2) cout << "YES 0." << s3 << "*10^" << e1 << endl; else cout << "NO 0." << s3 << "*10^" << e1 << " 0." << s4 << "*10^" << e2; }
4.Vector
1039 Course List for Student (25分)
map和vector的基本使用,最后记得对vector进行排序就可以了
#include <cstdio> #include <cstring> #include <string> #include <algorithm> #include <iostream> #include <map> #include <queue> #include <vector> #include <cmath> #define ll long long #define inf 0x3f3f3f #define pii pair<int, int> #define pb push_back using namespace std; const int maxn = 3e3+100; map<string, vector<int> > mp; string s; int n, m, id, q; int main(){ scanf("%d%d", &n, &m); while(m--){ scanf("%d%d", &id, &q); while(q--){ cin >> s; mp[s].pb(id); } } while(n--){ cin >> s; int len = mp[s].size(); cout << s << " " << len; sort(mp[s].begin(), mp[s].end()); for(int i = 0; i < len; i++) cout << " " << mp[s][i]; cout << endl; } }
1047. Student List for Course
vector的基本用法,但是最后一个测试点我超时了,原因是大量使用cout。这样一来解决方案有两种,一种是开始存储的时候就使用char*,另外一种为了方便起见,存储使用string,最后用string.to_str()转化使用printf输出,不过要注意to_str()的用法
#include <cstdio> #include <cstring> #include <string> #include <algorithm> #include <iostream> #include <map> #include <queue> #include <vector> #include <cmath> #define ll long long #define inf 0x3f3f3f #define pii pair<int, int> #define pb push_back using namespace std; const int maxn = 3e3+100; vector<string> g[maxn]; string s; int n, m, id, q; int main(){ scanf("%d%d", &n, &m); while(n--){ cin >> s >> q; while(q--){ cin >> id; g[id].pb(s); } } for(int i = 1; i <= m; i++){ cout << i << " " << g[i].size() << endl; sort(g[i].begin(), g[i].end()); int len = g[i].size(); for(int j = 0; j < len; j++) printf("%s ", g[i][j].c_str()); } }
reference:
https://www.liuchuo.net/archives/2147
https://www.xingmal.com/article/article/1234485790168453120
https://blog.csdn.net/wangshubo1989/article/details/49872717
https://www.cnblogs.com/newzol/p/8686076.html
5.Map
1071 Speech Patterns (25分)
理解错题目意思了,题干还带干扰,导致后来WA后都不知道什么原因,发现自己连题目对单词的定义都没看清楚,当时觉得这句话太长了,就跳过了
题目意思很简单,统计一句话中出现次数最多的单词的个数。这里的单词定义为被非数字、字母分割的连续数字、字母序列(e.g. aaa***aaaa需要进行分割):
Here a "word" is defined as a continuous sequence of alphanumerical characters separated by non-alphanumerical characters or the line beginning/end.
剩下的就是直接统计了,不过需要注意读取字符的方式,这里可以使用getline(cin, str) 读入一整行
#include <cstdio> #include <cstring> #include <string> #include <algorithm> #include <iostream> #include <map> #include <queue> #include <vector> #include <cmath> #define ll long long #define inf 0x3f3f3f #define pii pair<int, int> #define pb push_back using namespace std; const int maxn = 1e8+100; string str, id; int t, res; char ch; map<string, int> mp; bool check(char ch){ if(ch>='a'&&ch<='z') return true; else if(ch>='A'&&ch<='Z') return true; else if(ch>='0'&&ch<='9') return true; else return false; } int main(){ getline(cin, str); while(str[t]){ string word; while(check(ch=str[t++])){ if((ch>='a'&&ch<='z')||(ch>='0'&&ch<='9')) word += ch; else if(ch>='A'&&ch<='Z') word += ch-'A'+'a'; else if(word!="") word.clear(); } if(word!="") { // cout << word << " "; if(++mp[word]>=res) id = word , res = mp[id]; else if(mp[word]==res) id = id=="" ? word : min(id, word); } } cout << id << " " << res; }
Reference:
https://blog.csdn.net/a3192048/article/details/80303547
https://blog.csdn.net/qq_41325698/article/details/103424661
1100 Mars Numbers (20分)
map的基本使用,不难但是这种字符串的题目处理起来有点小麻烦。
还有两点需要注意:
- tret字符串长度为4啊,不要默认它长度为3
- 火星文进位没有0,比如26 输入的是 hel 而不是hel tret(题目中并没有指明)
#include <cstdio> #include <cstring> #include <string> #include <algorithm> #include <iostream> #include <map> #include <queue> #include <vector> #include <cmath> #define ll long long #define inf 0x3f3f3f #define pii pair<int, int> #define pb push_back using namespace std; const int maxn = 1e8+100; int t; string str; map<string, int> num; string low[13] = {"tret", "jan", "feb", "mar", "apr", "may", "jun", "jly", "aug", "sep", "oct", "nov", "dec" }; string high[13] = {"tret","tam", "hel", "maa", "huh", "tou", "kes", "hei", "elo", "syy", "lok","mer", "jou" }; int main(){ for(int i = 0; i < 13; i++) num[low[i]] = i, num[high[i]] = 13*i; scanf("%d", &t); getchar(); while(t--){ getline(cin, str); int len = str.length(); if(str[0]>='0'&&str[0]<='9') { int sum = 0; for(int i = 0; i < len; i++) sum += (str[i]-'0')*pow(10, len-1-i); if(sum<13) cout << low[sum] << endl; else { cout << high[sum/13]; if(sum%13!=0) cout << " " << low[sum%13]; cout << endl; } } else if(len<=4) cout << num[str] << endl; else cout << num[str.substr(0, 3)]+num[str.substr(4, 3)] << endl; } }
Reference:
https://blog.csdn.net/qq_26398495/article/details/79159381
1022 Digital Library (30分)
map的基本使用,需要注意两点:
- getline的使用,详细见Refernce
- 记录id的时候最好使用string而不是int,可能会碰到0000111的格式,或者输出时限制格式也可
#include <cstdio> #include <cstring> #include <string> #include <algorithm> #include <iostream> #include <map> #include <queue> #include <vector> #include <cmath> #define ll long long #define inf 0x3f3f3f #define pii pair<int, int> #define pb push_back using namespace std; const int maxn = 1e8+100; map<string, vector<string> >mp; string id, title, author, keyword, publisher, date, query; int t, q; int main(){ scanf("%d", &t); while(t--){ cin >> id, getchar(); getline(cin, title), getline(cin, author); // cout << id << " " << title << " " << author << endl; mp[title].pb(id), mp[author].pb(id); while(cin>>keyword){ mp[keyword].pb(id); if(getchar()==' ') break; } getline(cin, publisher); cin >> date; mp[publisher].pb(id), mp[date].pb(id); } cin >> q, getchar(); while(q--){ getline(cin, query); cout << query << endl; string tmp = query.erase(0, 3); int len = mp[tmp].size(); if(len!=0){ sort(mp[tmp].begin(), mp[tmp].end()); for(int i = 0; i < len; i++) cout << mp[tmp][i] << endl; } else cout << "Not Found" << endl; // cout << query << endl; } }
Reference:
https://www.cnblogs.com/zzzlight/p/12541729.html
6.Set
1063 Set Similarity (25分)
这题就是set的基本使用,最开始做的时候由于把查询的两个数据集结果用set再保存一遍,发现测试点4会超时。
为了降低复杂度,策略改成找两个数据集相同的部分。可以分别使用两个指针指向数据集去判断,不过使用find足以过题,就没有再优化了
#include <cstdio> #include <cstring> #include <string> #include <algorithm> #include <iostream> #include <cmath> #include <map> #include <queue> #include <vector> #include <set> #define ll long long #define inf 0x3f3f3f #define pii pair<int, int> #define pb push_back using namespace std; const int maxn = 1e8+100; set<int> s[100]; int n, m, num, q; int main(){ scanf("%d", &n); for(int i = 1; i <= n; i++){ scanf("%d", &m); while(m--){ scanf("%d", &num); s[i].insert(num); } } scanf("%d", &q); while(q--){ int a, b, tot = 0; scanf("%d%d", &a, &b); int lena = s[a].size(), lenb = s[b].size(); set<int>::iterator it; for(it = s[a].begin(); it != s[a].end(); it++) { if(s[b].find(*it)!=s[b].end()) tot++; } // cout << lena << " " << lenb << " " << s[n+1].size() << endl; printf("%.1f% ", 100.0*tot/(lena+lenb-tot)); } }