通过javap命令查看class文件的字节码内容
写一个java程序
public class JvmTest
{
public static void main( String[] args )
{
int a = 2;
int b = 5;
int c = b-a;
System.out.println(c);
}
}
然后进行编译

通过javap命令查看class文件中的字节码内容
javap用法: javap <options> <classes>

javap命令中,可能的选项包括
- ‐help ‐‐help ‐? 输出此用法消息
- ‐version 版本信息
- ‐v ‐verbose 输出附加信息
- ‐l 输出行号和本地变量表
- ‐public 仅显示公共类和成员
- ‐protected 显示受保护的/公共类和成员
- ‐package 显示程序包/受保护的/公共类和成员 (默认)
- ‐p ‐private 显示所有类和成员
- ‐c 对代码进行反汇编
- ‐s 输出内部类型签名
- ‐sysinfo 显示正在处理的类的系统信息 (路径, 大小, 日期, MD5 散列)
- ‐constants 显示最终常量
- ‐classpath <path> 指定查找用户类文件的位置
- ‐cp <path> 指定查找用户类文件的位置
- ‐bootclasspath <path> 覆盖引导类文件的位置
查看生成的test.txt文件内容大致分为4个部分:
第一部分:显示了生成这个class的java源文件、版本信息、生成时间等。
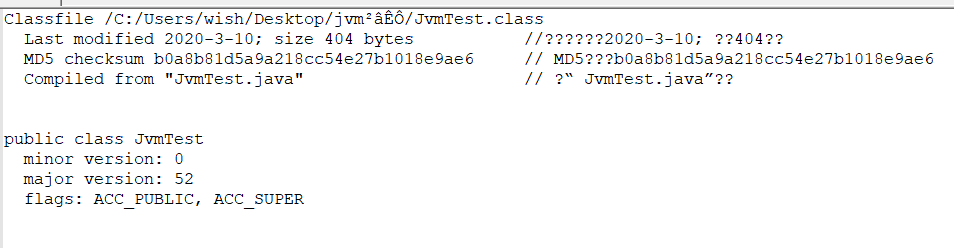
第二部分:显示了该类中所涉及到常量池,共26个常量。
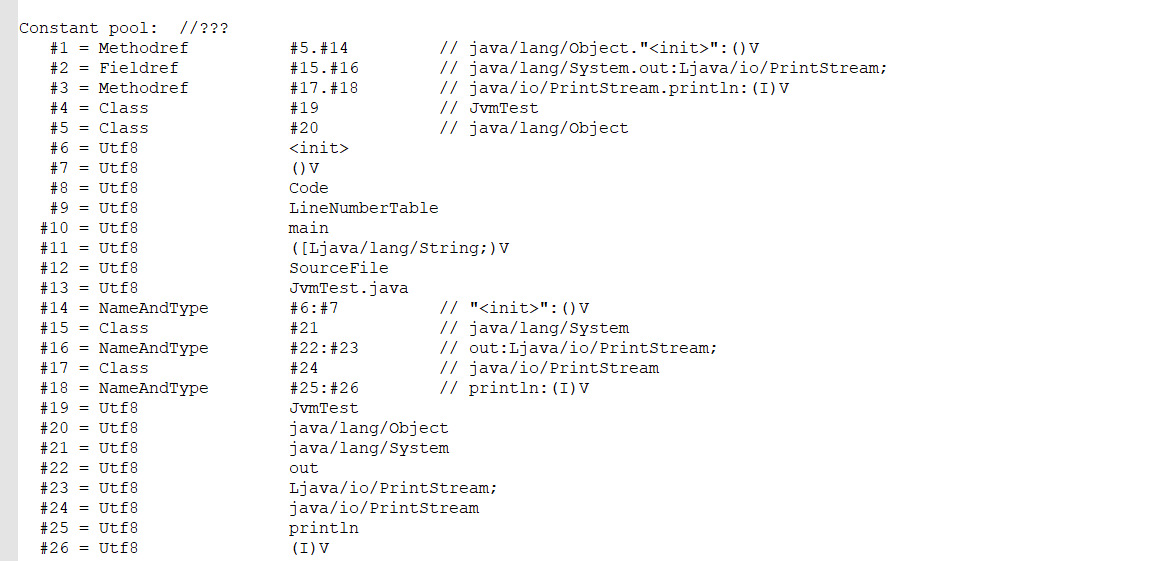
第三部分:显示该类的构造器,编译器自动插入的。

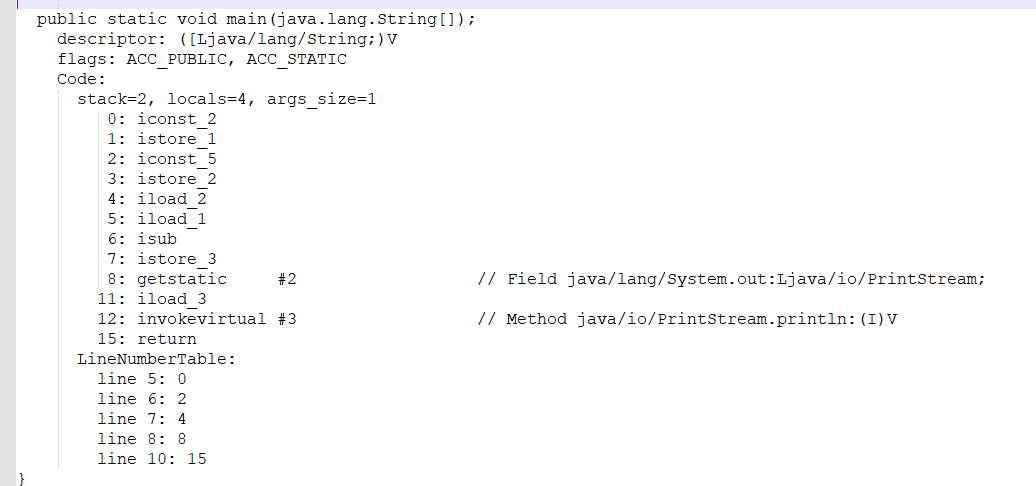
第四部分:显示了main方的信息。(这个是需要我们重点关注的)
常量池
官网文档:https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-4.html#jvms-4.4-140
constant_pool表中的每个项目都 必须以一个1字节的标签开头,指示cp_info条目的类型。
info数组的内容随的值而变化tag。有效标签及其值在表中列出。
每个标签字节后必须跟两个或多个字节,以提供有关特定常数的信息。
附加信息的格式随标签值的不同而不同。
| Constant Type(常量类型) | Value(值) | 说明 |
| CONSTANT_Class | 7 | 类或接口的符号引用 |
| CONSTANT_Fieldref | 9 | 字段的符号引用 |
| CONSTANT_Methodref | 10 | 类中方法的符号引用 |
| CONSTANT_InterfaceMethodref | 11 | 接口中方法的符号引用 |
| CONSTANT_String | 8 | 字符串类型常量 |
| CONSTANT_Integer | 3 | 整型常量 |
| CONSTANT_Float | 4 | 浮点型常量 |
| CONSTANT_Long | 5 | 长整型常量 |
| CONSTANT_Double | 6 | 双精度浮点型常量 |
| CONSTANT_NameAndType | 12 | 字段或方法的符号引用 |
| CONSTANT_Utf8 | 1 | UTF-8编码的字符串 |
| CONSTANT_MethodHandle | 15 | 表示方法句柄 |
| CONSTANT_MethodType | 16 | 标志方法类型 |
| CONSTANT_InvokeDynamic | 18 | 表示一个动态方法调用点 |
描述符
1.字段描述符
官网:https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-4.html#jvms-4.3.2
字段描述符表示类,实例或局部变量的类型。
基本类型中,L和; 的对象类型,和[ 的数组类型都是ASCII字符。
ClassName表示以内部形式编码的二进制类或接口名称。
表中显示了字段描述符作为类型的解释。
表示数组类型的字段描述符只有在表示维数小于等于255的类型时才有效。
| FieldType term(FieldType术语) | Type(类型) | Interpretation(解释) |
| B | byte | 有符号字节 |
| C | char | 基本多语言平面中的Unicode字符代码点,使用UTF-16编码 |
| D | double | 双精度浮点值 |
| F | float | 单精度浮点值 |
| I | int | 整数 |
| J | long | 长整数 |
L ClassName ; |
reference | 类ClassName的一个实例 |
| S | short | 短类型 |
| Z | boolean | true 要么 false |
| [ | reference | 一维数组 |
- 类型的实例变量的描述符字段
int是根本I。 - 类型的实例变量的字段描述符
Object为L java/lang/Object;。请注意,Object使用了类的二进制名称的内部形式。 - 多维数组类型的实例变量的字段描述符
double[][][]为[[[D。
2.方法描述符
官网:https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-4.html#jvms-4.3.3
方法描述符中包含零点或多个参数的描述符,表示该类型的参数,该方法需要和返回的描述符,表示该值的类型(如果有的话),该方法返回
字符V表示该方法不返回任何值(其结果为void)。
示例:
方法的方法描述符:
object m(int i, double d, Thread t) {...}
在字节码文件中
(IDLjava/lang/Thread;)Ljava/lang/Objec
需要注意的是的二进制名称的内部形式 Thread和Object使用。
- 一种方法,描述符是有效的,只有当它表示具有255或更低的总长度,其中该长度包括在实例或接口方法调用的情况下,这种情况的贡献方法参数。
- 通过将各个参数的贡献相加来计算总长度,其中long或double类型的参数对长度贡献两个单位,而其他类型的参数则贡献一个单位。
- 无论方法描述器是类方法还是实例方法,方法描述符都是相同的。
- 尽管为此传递了实例方法,但对引用对象的引用除了其预期的参数外,该事实并未反映在方法描述符中。
- 对此的引用由调用实例方法的Java虚拟机指令隐式传递。
解读方法字节码
主要关注的第四部分
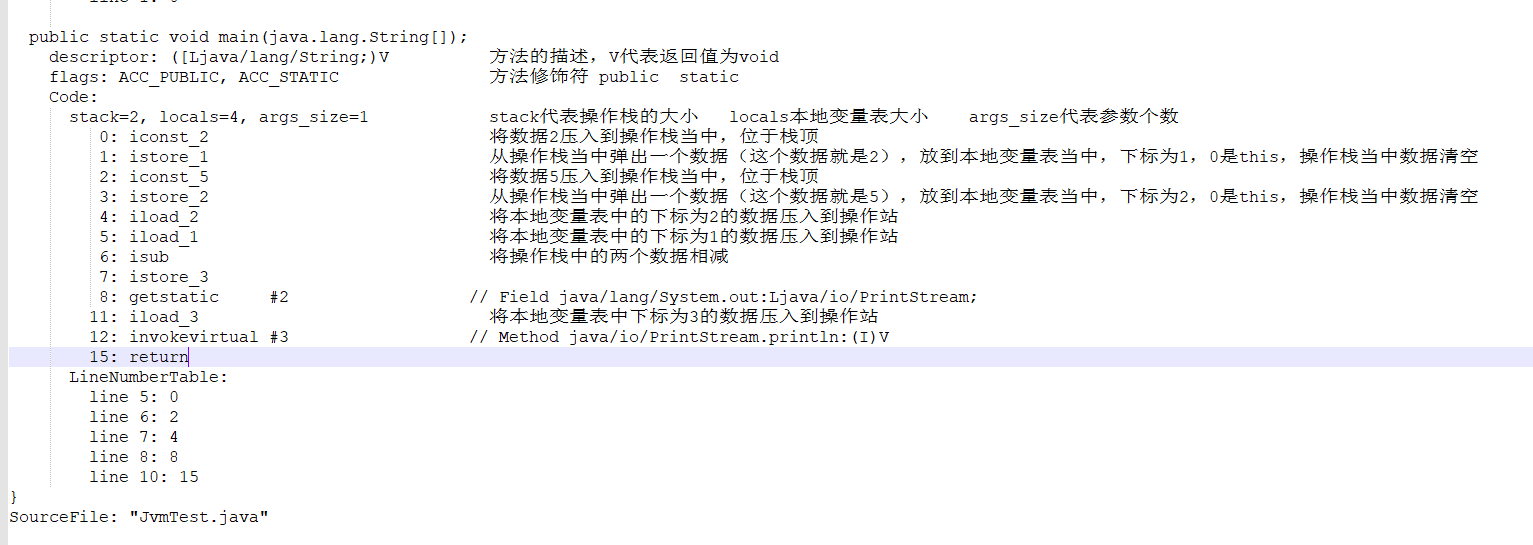
图解
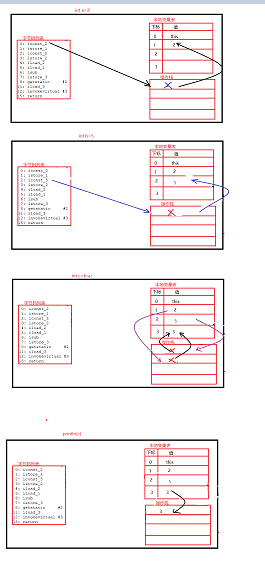
研究 i++ 与 ++i 的不同
i++表示,先返回再+1,++i表示,先+1再返回。
编写测试代码:
public class Test2 {
public static void main(String[] args) {
new Test2().method1();
new Test2().method2();
}
public void method1(){
int i = 1;
int a = i++;
System.out.println(a); //打印1
}
public void method2(){
int i = 1;
int a = ++i;
System.out.println(a);//打印2
}
}
字节码文件
我们主要看的是method1和method2两个方法的字节码


图解对比
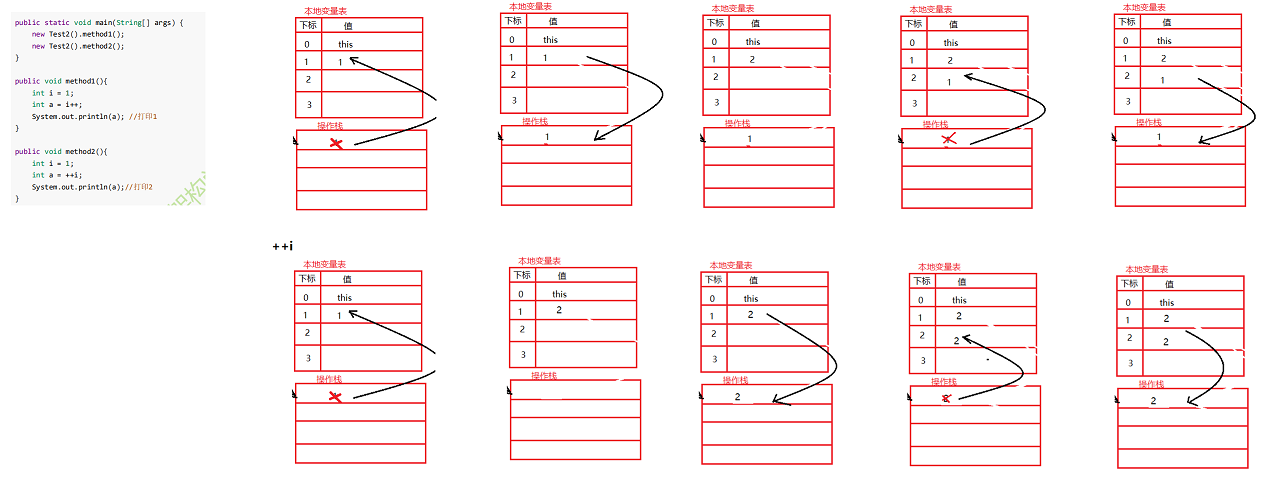
由上图,可以看见i++与++i 在第二步和第三步的时候是颠倒过来的
区别:
- i++
- 只是在本地变量中对数字做了相加,并没有将数据压入到操作栈
- 将前面拿到的数字1,再次从操作栈中拿到,压入到本地变量中
- ++i
- 将本地变量中的数字做了相加,并且将数据压入到操作栈
- 将操作栈中的数据,再次压入到本地变量中
字符串拼接
字符串的拼接在开发过程中使用是非常频繁的,常用的方式有三种:
- +号拼接: str+"456"
- StringBuilder拼接
- StringBuffer拼接
StringBuffer是保证线程安全的,效率是比较低的,我们更多的是使用场景是不会涉及到线程安全的问题的,所以更多的时候会选择StringBuilder,效率会高一些
比较+号拼接与StringBuilder那个效率高
代码
package cn.itcast.jvm;
public class Test3 {
public static void main(String[] args) {
new Test3().m1();
new Test3().m2();
}
public void m1(){
String s1 = "123";
String s2 = "456";
String s3 = s1 + s2;
System.out.println(s3);
}
public void m2(){
String s1 = "123";
String s2 = "456";
StringBuilder sb = new StringBuilder();
sb.append(s1);
sb.append(s2);
String s3 = sb.toString();
System.out.println(s3);
}
}
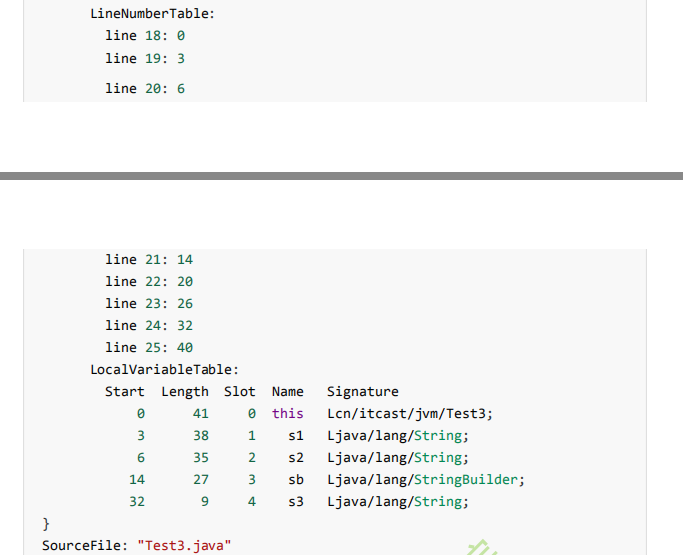
字节码
m1的字节码

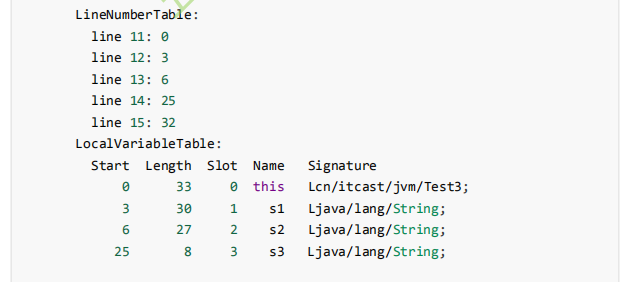
m2

从解字节码中可以看出,m1()方法源码中是使用+号拼接,但是在字节码中也被编译成了StringBuilder方式。
所以,可以得出结论,字符串拼接,+号和StringBuilder是相等的,效率一样。
比较使用+号循环拼接和使用StringBuilder.append()方法循环拼接那个效率高
代码
package cn.itcast.jvm;
public class Test4 {
public static void main(String[] args) {
new Test4().m1();
new Test4().m2();
}
public void m1(){
String str = "";
for (int i = 0; i < 5; i++) {
str = str + i;
}
System.out.println(str);
}
public void m2(){
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 5; i++) {
sb.append(i);
}
System.out.println(sb.toString());
}
}
字节码
m1

m2

可以看到,m1()方法中的循环体内,每一次循环都会创建StringBuilder对象,效率低于m2()方法。