一:概念:
又称单词查找树,Trie树,是一种树形结构,典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
利用公共前缀,减少比较,节省空间。
二:图示:
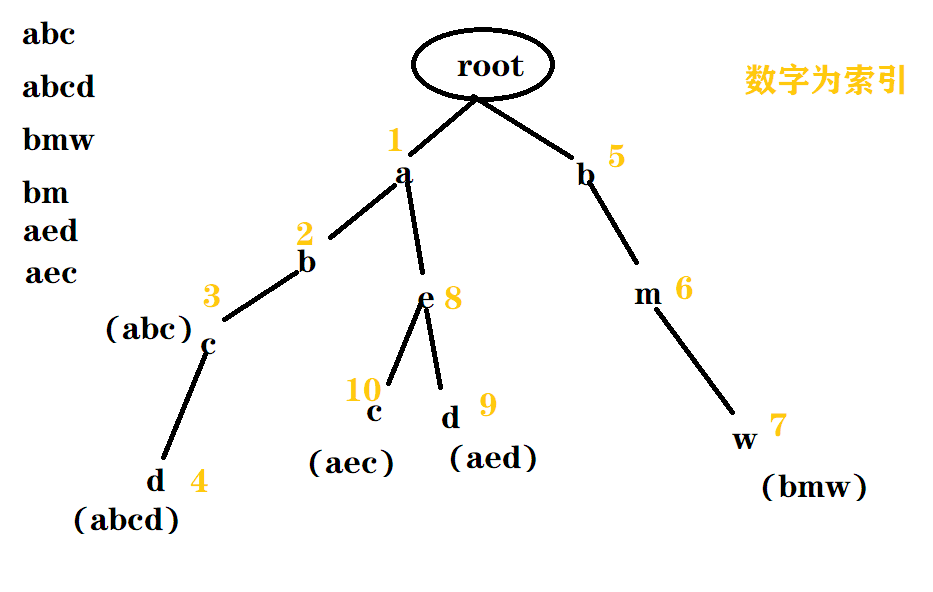
可以发现,建立过程是,对于当前字母,有路,就走过去,否则,建一个新节点。
三:在数组中的建立过程图示
引入:mp[][26],cnt[]
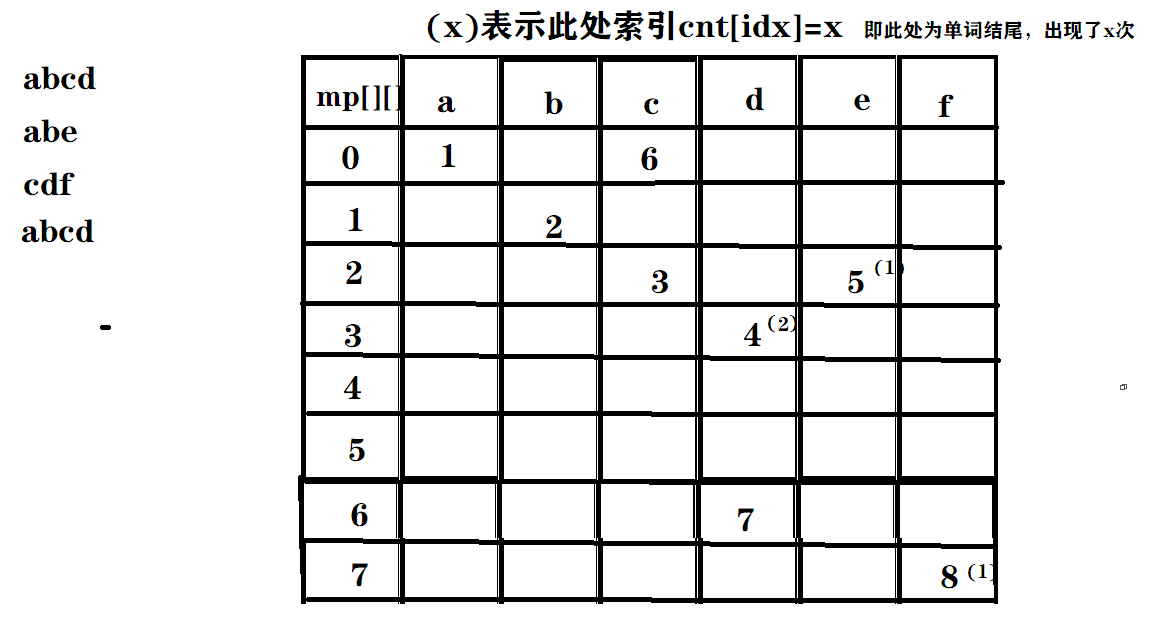
画的不好~~
idx,以索引来记录每个字符的位置
可以发现,每一个mp[p][字母],都是本字母的下一个字母的索引位置:
比如上图的cdf,mp[0][c]==6,接下来找mp[6][d]是否存在,存在,是7,那么找mp[7][f]是否存在,发现存在,而且cnt[8]==1,则cdf为一个单词。这就是查找的过程。
同理,建树也是一样,mp[][]不存在,就新建一个结点++idx。
四:板子代码:
以上图为例:

#include<iostream> #include<cstring> #include<algorithm> #include<cmath> using namespace std; typedef long long ll; const int maxn = 1e5+10; char s[maxn]; int mp[maxn][29],cnt[maxn]; int idx=0; void insert() { int p = 0; for(int i=0;s[i];i++) { int u=s[i]-'a'; if(!mp[p][u]) //没有字母,所以新建。否则顺着走过去,跳到p=mp[p][u] mp[p][u]=++idx; p=mp[p][u]; } cnt[p]++; //p处即为一个单词,++ } int query() { int p = 0; for(int i=0;s[i];i++) { int u = s[i] - 'a'; if(!mp[p][u]) //没路,说明没这个单词,直接结束 return 0; p=mp[p][u]; } return cnt[p]; //返回此单词出现次数。 } int main() { int n; scanf("%d",&n); while(n--) { char op[4]; scanf("%s%s",op,s); if(op[0]=='I') insert(); else cout<<query()<<endl; } return 0; }