Spark的体系结构如下图。基本认知入门。
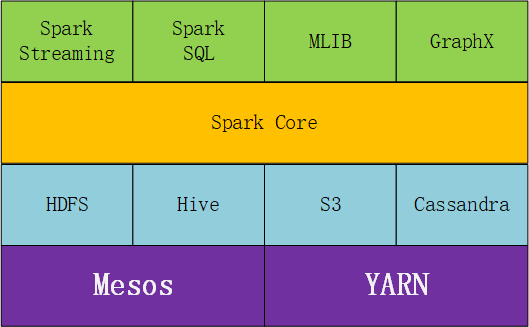
数据接口访问层是第一层绿色部分,包含Spark Streming、Spark SQL、MLIB和GraphX。
数据核心处理是第二层橙色,主要包含Spark Core。
数据的存储集中在第三层天蓝色,以HDFS、Hive、S3等为主。
任务调度则集中在第四层紫色,以YARN和Mesos为常用。
1 、数据访问皆苦层
1.1 Spark Streaming
是一种准实时的流式处理框架。其要义是将数据按照时间窗口大小分解成小批次数据,每个小批次数据都可以基于RDD处理。
支持多种数据源,Kafka、Flume、TCP等。
详情参考:http://spark.apache.org/docs/2.4.6/streaming-programming-guide.html
1.2 Spark SQL
用于结构化数据处理,简化了开发人员对RDD的操作。
Spark SQL基于Catalyst优化器,Catalyst优化器不仅有基于规则的优化也有基于成本的优化。
更多参考:http://spark.apache.org/docs/2.4.6/sql-getting-started.html、
1.3 MLIB
机器学习库,提供了常用机器学习算法的实现,如聚类、分类、回归、协同过滤等。
参考:http://spark.apache.org/docs/2.4.6/ml-guide.html
1.4 GraphX
图计算库,可认为是Pregel在Spark上的重写及优化。
参考:http://spark.apache.org/docs/2.4.6/graphx-programming-guide.html
2、Spark Core
此包含Spark的基础和核心功能,建立在RDD上,任务调度、数据计算、存储管理、故障恢复、部署方式等。