1. 编码:
1.字符编码
定义:就是存储了信息的东西
2. 编码的历史
发明国家:美国
第一种编码语言:ACILL
但是随着世界各国的发展,计算机的使用逐渐增加,但是各国之间的编码不一致,便会出现乱码的现象
所以就有了新的编码
Unicode:是一种可以识别各个国家万国编码,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
自此,世界上的计算机可以相互看编辑的文字,不会再出现乱码的情况。
3. 编码和解码
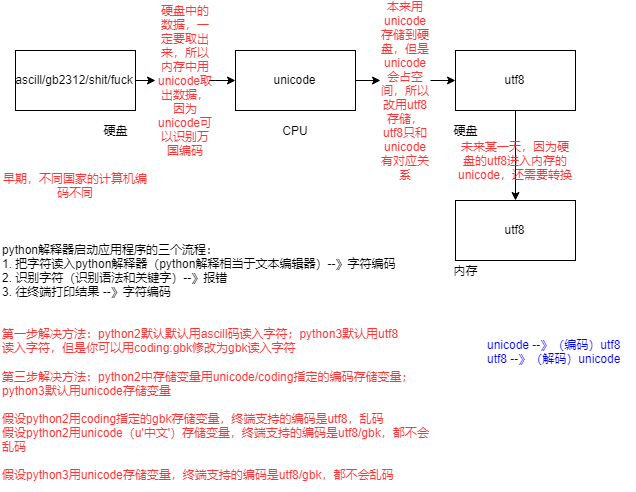
但是随着 Unicode 加入的语言越来越多,编码所需的字节越来越多(4个字节),有时候一篇英文文献本来用 ASCII 存只需要1k,但是用 Unicode 的话,就会增加到4k,这样在网络上传输造成很大的资源浪费,因此本着节约的精神出现了可变长的 UTF-8 编码,它即兼容 ASCII 和其他语言,也不会造成太多的空间浪费。
现在存储的时候一般都会把文本保存成UTF-8的形式存储下来(因为这样比较省空间),但是在计算机内存中,也还是统一使用 Unicode 编码,因为 Unicode 为定长编码,对于定长编码 CPU 的处理效率更高。即计算机从硬盘读取文本,并将其编码格式 (UTF-8) 转换成 Unicode 到 CPU 进行处理,等到处理完毕之后,再将内存里面 Unicode 编码的文本转换成 UTF-8 存到硬盘中。
2. python解释器 解释代码的流程
1. 读取文本到解释器
python2默认是使用ASCII编码读取
python3默认使用 utf8编码读取
(当有coding头时,他们都使用coding中设定的编码进行读取)
2. 识别代码(检查语法问题)
3. 往终端打印
存储变量:
- python2中存储变量用Unicode/coding指定的编码存储变量
print u'中国' #表示用unicode存储变量
- python3中默认使用Unicode存储变量
假设1:python2用coding指定的gbk存储变量,终端支持的编码是utf8,打印结果:乱码
假设2:python2用Unicode(u'中文')来存储变量,终端支持的编码是utf8/gbk,打印结果:都不会乱码
假设3:python3用Unicode存储变量,终端支持的编码是utf8/gbk,打印结果:都不会乱码