第二章 k近邻
2.1 算法描述
(1)采用测量不同特征值之间的距离进行分类
优点:对异常点不敏感,精度高,无数据输入设定
缺点:空间,计算复杂度高
适合数据:标称与数值
(2)算法的工作原理:
基于已有的带有标签的训练数据,计算出需要预测的数据与每个训练数据之间的距离,找到其中距离最近的k个数据,根据这k数据中数量最多的类来决定测试数据的类别
(3)算法的类别
该算法属于有监督学习,用于分类,因此它的目标变量是离散的
(4)算法的一般流程:
1.收集数据
2.准备数据
3.分析数据
4.测试算法
5.使用算法
2.2算法实现过程
(1)获取数据
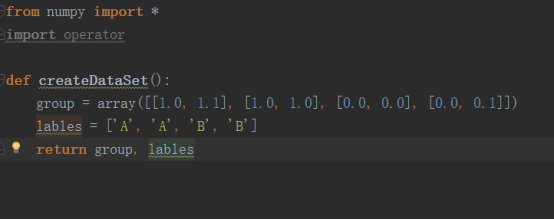
(2)KNN算法
from numpy import * import operator # this KNN matrix col is 3 # in order to create data def createDataSet(): group = array([[1.0, 1.1], [1.0, 1.0], [0.0, 0.0], [0.0, 0.1]]) lables = ['A', 'A', 'B', 'B'] return group, lables # main algorithm def classify0(inx, dataSet, lables, k): datasetSize = dataSet.shape[0] diffmat = tile(inx, (datasetSize, 1)) - dataSet sqdiffmat = diffmat**2 sqDistance = sqdiffmat.sum(axis=1) distance = sqDistance**0.5 sortedDistance = distance.argsort() classcount = {} for i in range(k): votelabel = lables[sortedDistance[i]] classcount[votelabel] = classcount.get(votelabel, 0) + 1 sortedclasscount = sorted(classcount.iteritems(), key=operator.itemgetter(1), reverse=True) return sortedclasscount[0][0] # read the txt data file def file2matrix(filename): fr = open(filename) arraylines = fr.readlines() numberoflines = len(arraylines) returnmatrix = zeros((numberoflines, 3)) # you can change the col clasavector = [] index = 0 for line in arraylines: line = line.strip() listformline = line.split(' ') returnmatrix[index, :] = listformline[0:3] # you should change the col clasavector.append(int(listformline[-1])) index += 1 return returnmatrix, clasavector # normalize the data def autonorm(dataset): minval = dataset.min(0) maxval = dataset.max(0) ranges = maxval - minval datasetsize = dataset.shape[0] normdataset = dataset - tile(minval, (datasetsize, 1)) normdataset = normdataset/tile(ranges, (datasetsize, 1)) return normdataset, ranges, minval def datingclasstest(filename): horatio = 0.1 dataset, lableset = file2matrix(filename) noramdataset, ranges, minval = autonorm(dataset) col = dataset.shape[0] test = int(col*horatio) errorcount = 0.0 for i in range(col): classlable = classify0(noramdataset[i, :], noramdataset[test:col, :], lableset[test:col], 3) if classlable != lableset[i]: errorcount += 1 error = errorcount / float(col) print error
(3)dating应用程序
import KNN from numpy import * def classifyperson(): returnlist = ['not at all', 'in small doses', 'in large doses'] game = float(raw_input("the percentage of playing video game")) fly = float(raw_input("the num of the flier mail")) icecream = float(raw_input("the num of icecream every weak")) person = array([game, fly, icecream]) dataset,datalable = KNN.file2matrix("F:data/machinelearninginaction/Ch02/datingTestSet2.txt") normdataset, ranges, minval=KNN.autonorm(dataset) classifierresult =KNN.classify0((person - minval)/ranges, normdataset, datalable, 3) print "you will like him %s" % returnlist[classifierresult-1]
(4)手写识别程序
import KNN from os import listdir from numpy import * # change the 32*32 to vector def image2vertor(filename): fr = open(filename) imagevertor = zeros((1, 1024)) for i in range(32): line = fr.readline() for j in range(32): imagevertor[0, i*32+j] = int(line[j]) return imagevertor testvector = image2vertor("F:data/machinelearninginaction/Ch02/digits/testDigits/0_13.txt") def handwritingtest(): hwlables = [] # record the lable filename = listdir("F:data/machinelearninginaction/Ch02/digits/trainingDigits/") filenum = len(filename) dataset = zeros((filenum, 1024)) for i in range(filenum): filenamestr = filename[i].split(".")[0] filelable = int(filenamestr.split('_')[0]) hwlables.append(filelable) filepath = "F:data/machinelearninginaction/Ch02/digits/trainingDigits/" + filename[i] data = image2vertor(filepath) dataset[i, :] = data testfile = listdir("F:data/machinelearninginaction/Ch02/digits/testDigits/") testfilenum = len(testfile) for j in range(testfilenum): testfilestr = testfile[j].split('.')[0] testfilelable =int(testfilestr.split('_')[0]) testdilepath = "F:data/machinelearninginaction/Ch02/digits/testDigits/" + testfile[j] testdata = image2vertor(testdilepath) classname = KNN.classify0(testdata, dataset, hwlables, 3) error = 0.0 if classname == testfilelable: error += 1 print "we think it is %d, the real is %d" % (classname, testfilelable) print "the num of error is %d " % error print "the error rate is %f" % (error/float(testfilenum)) handwritingtest()