分词器概念介绍:
Analyzer类(分词器)就是把一段文本中的词按某些规则取出,提供和以后查询时使用的工具类,注意在创建索引时会用到分词器,在使用字符串搜索时也会用到分词器,这两个地方要使用同一个分词器,否则可能会搜索不出结果
分词器工作流程:
1, 切分关键词
2, 去除停用词
3, 对于英文单词,把所有字母转为小写(搜索时不区分大小写)
停用词:
有些词在文本中出现的频率非常高,但是对文本所携带的信息基本不产生影响,例如英文的“a、an、the、of”,或中文的“的、了、着、是”,以及各种标点符号等。文本经过分词之后,停用词通常被过滤掉,不会被进行索引,这样的词称为停用词(stop word)。在检索的时候,用户的查询中如果含有停用词,检索系统也会将其过滤掉(因为用户输入的查询字符串也要进行分词处理)。排除停用词可以加快建立索引的速度,减小索引库文件的大小。
常用的中文分词器
中文的分词比较复杂,因为不是一个字就是一个词,而且一个词在另外一个地方就可能不是一个词,如在“帽子和服装”中,“和服”就不是一个词。对于中文分词,通常有三种方式:单字分词、二分法分词、词典分词。
单字分词:就是按照中文一个字一个字地进行分词。如:“我们是中国人”,
效果:“我”、“们”、“是”、“中”、“国”、“人”。(StandardAnalyzer就是这样)。
二分法分词:按两个字进行切分。如:“我们是中国人”,效果:“我们”、“们是”、“是中”、“中国”、“国人”。(CJKAnalyzer就是这样)。
词库分词:按某种算法构造词,然后去匹配已建好的词库集合,如果匹配到就切分出来成为词语。通常词库分词被认为是最理想的中文分词算法。如:“我们是中国人”,效果为:“我们”、“中国人”。(使用极易分词的MMAnalyzer。可以使用“极易分词”,或者是“庖丁分词”分词器、IKAnalyzer)。
中文分词器使用IKAnalyzer,主页:http://www.oschina.net/p/ikanalyzer。
实现了以词典为基础的正反向全切分,以及正反向最大匹配切分两种方法。IKAnalyzer是第三方实现的分词器,继承自Lucene的Analyzer类,针对中文文本进行处理。具体的使用方式参见其文档。
注意:扩展的词库与停止词文件要是UTF-8的编码,并且在要文件头部加一空行。
各种分词器测试
需要添加 lucene-analyzers-3.0.0.jar
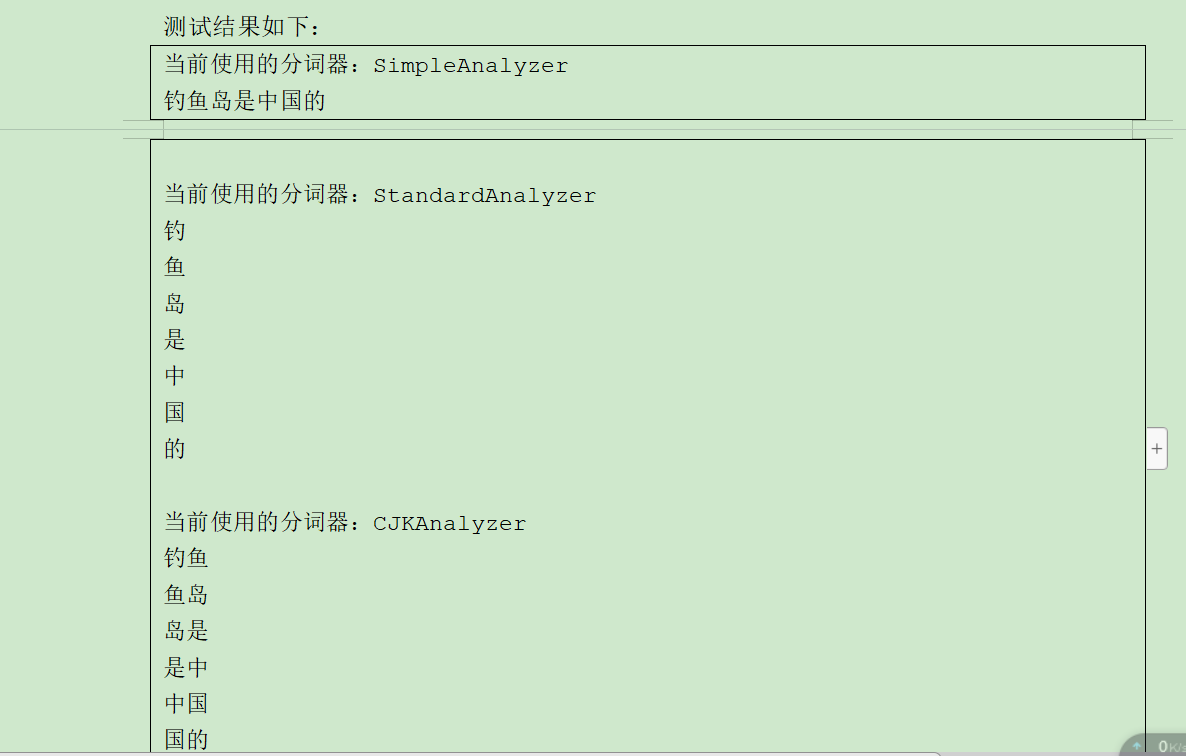
// 不同的分词器,中文代码测试 public void testAnalyzer(Analyzer analyzer, String text) throws Exception { System.out.println("当前使用的分词器:" + analyzer.getClass().getSimpleName()); TokenStream tokenStream = analyzer.tokenStream("content", new StringReader(text)); tokenStream.addAttribute(TermAttribute.class); while (tokenStream.incrementToken()) { TermAttribute termAttribute = tokenStream.getAttribute(TermAttribute.class); System.out.println(termAttribute.term()); } System.out.println(); } 测试代码如下: @Test public void testAnalyzer()throws Exception{ helloWorld.testAnalyzer(new SimpleAnalyzer(),"钓鱼岛是中国的"); helloWorld.testAnalyzer(new StandardAnalyzer(Version.LUCENE_30),"钓鱼岛是中国的"); helloWorld.testAnalyzer(new CJKAnalyzer(Version.LUCENE_30),"钓鱼岛是中国的"); }
测试结果
IK Analyzer 3.X介绍
IK Analyzer 是一个开源的,基于 java诧言开发的轻量级的中文分词工具包。从 2006年 12 月推出 1.0 版开始, IKAnalyzer 已经推出了 3 个大版本。最初,它是以开源项目Luence 为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的 IK Analyzer 3.X 则发展为面吐 Java 的公用分词组件,独立于 Lucene 项目,同时提供了对Lucene的默认优化实现。
GoogleCode开源项目 :http://code.google.com/p/ik-analyzer/
GoogleCode SVN下载:http://ik-analyzer.googlecode.com/svn/trunk/
IK Analyzer 3.X的使用
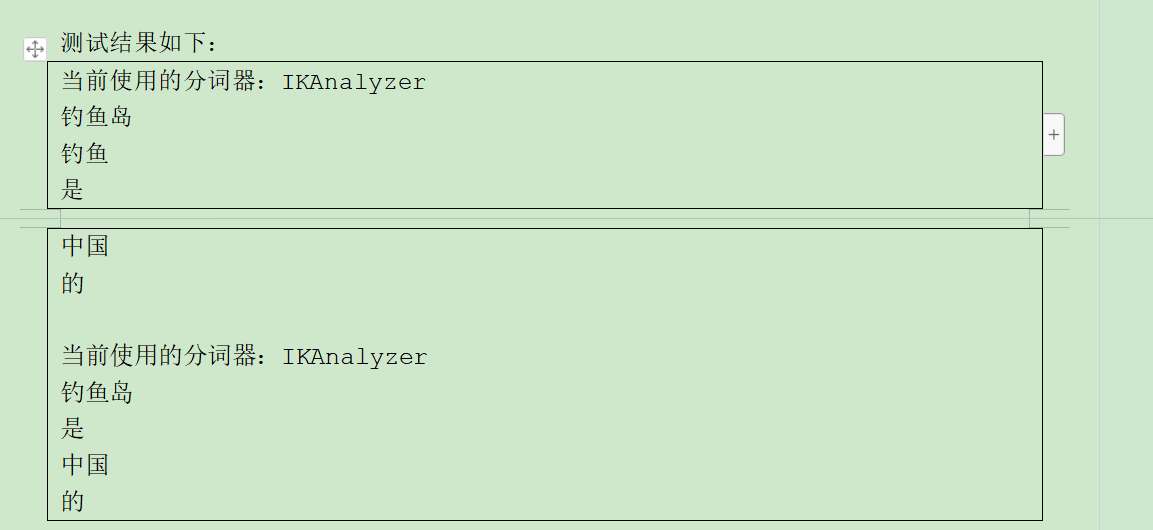
@Test public void testAnalyzer()throws Exception{ // false 细粒度切分 helloWorld.testAnalyzer(new IKAnalyzer(false),"钓鱼岛是中国的"); // true 最大词长切分 helloWorld.testAnalyzer(new IKAnalyzer(true),"钓鱼岛是中国的"); }
基于配置的词典扩充
1. IK 分词器还支持通过配置 IKAnalyzer.cfg.xml 文件来扩充您的与有词典以及停止词典(过滤词典) UTF-8格式
2. 部署IKAnalyzer.cfg.xml ,IKAnalyzer.cfg.xml 部 署 在 代 码 根 目 录 下 ( 对 于 web 项 目,通 常 是WEB-INF/classes 目录)同 hibernate、log4j 等配置文件相同。
3. IKAnalyzer.cfg.xml配置如下:
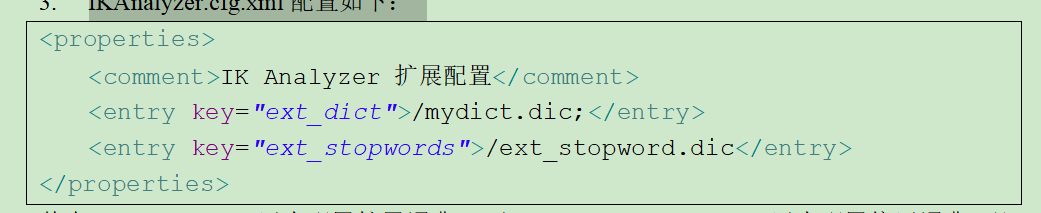
其中/mydict.dic用来配置扩展词典, 而/ext_stopword.dic 用来配置停用词典,配置后细粒度和最大词拆分如下:

排序:
1. 相关度得分是在查询时根据查询条件实进计算出来的
2. 设置按指定的字段排序.(注意,如果设置了指定的字段排序. 相关度排序则无效)
如果需要配置文件或者 代码jar包的可以留言 我发给大家