论文信息:论文,代码,Knowledge-Based Systems 2018.
概述
传统的情感分析方法主要用于对文本的情感极性(例如,积极,消极和中立)或情感类别(例如,喜怒哀乐)进行分类。但是,这些方法都是粗粒度的,可能会忽略不同文本之间的细微情感差异。为了解决这个问题,研究者们提出了维度情感分析(DSA),从文本中挖掘细粒度的情感信息。
尽管有监督的DSA方法目前已经比较成熟了,但是它们需要大量的标注样本训练模型。因此该论文提出了一个基于变分自编码器(VAE)的半监督DSA模型。该模型包含三个模块:编码模块、情感预测模块和解码模块。编码模块通过LSTM将文本编码为向量,情感预测模块从不同维度预测文本情感分值,解码模块构建隐空间并重构文本。
背景知识
变分自编码器的基础知识可以从这里获得。本文对基本变分自编码器和半监督变分自编码器进行了简单讲解,这里给出一个初略的比较图。基本变分自编码器结构如下:
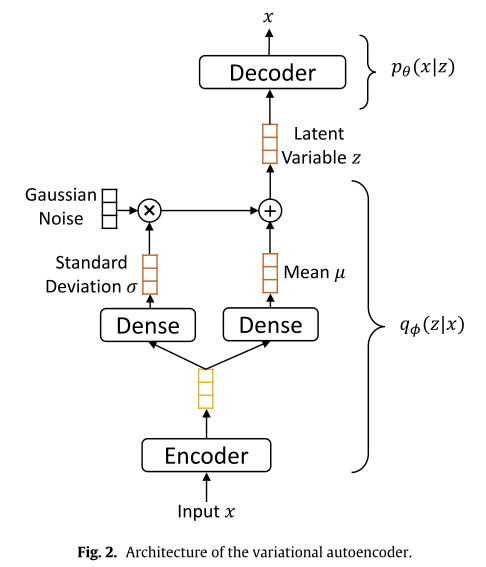
而半监督变分自编码器结构如下图:
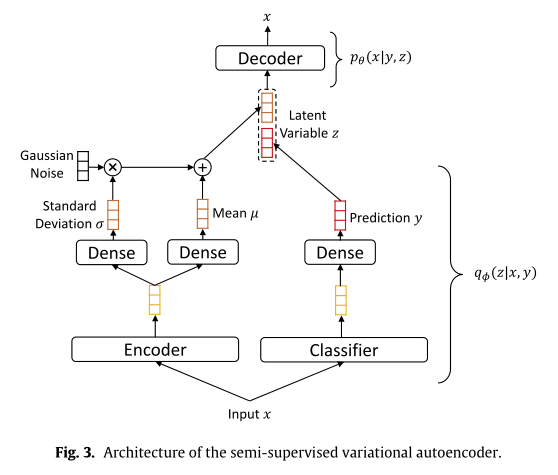
方法
该论文提出的DSA模型主要结构如下图所示:
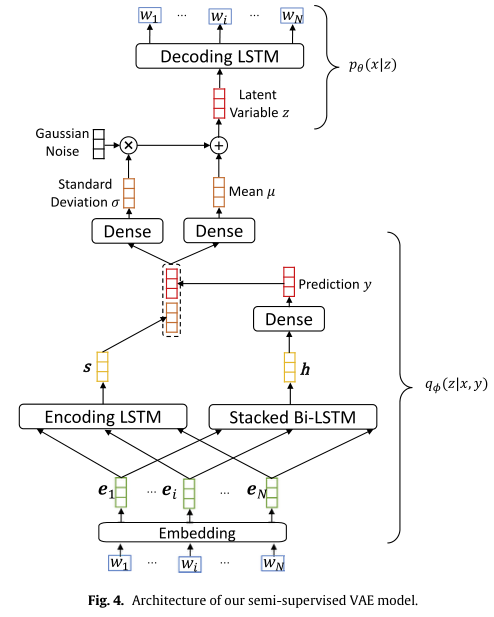
编码模块
假设文本序列为(s=[w_1,w_2,dots,w_N]),(w_i)表示第(i)个单词。编码模块第一层将每个单词(w_i)映射为向量(e)。向量(e)由两部分拼接组成,分别为词向量(e^w)和part-of-speech (POS)向量(e^p)。第一层得到的向量序列([e_1,e_2,dots,e_N])再输入到第二层LSTM中,最终得到文本的隐向量(mathbf{s})。
情感预测模块
情感预测模块也包含两个部分。第一部分是一个两层的Bi-LSTM,以文本向量序列为输入编码得到隐向量(mathbf{h})。第二部分是一个全连接层,用于预测情感分值(mathbf{y})。
解码模块
解码模块用于重建输入文本。该模块包含三个部分。
第一部分是线性变换模块,它由两个全连接层组成,用于学习变分自编码器的均值向量(mu)和标准差向量(sigma)。这部分输入为编码模块和情感预测模块的输出,即([mathbf{y};mathbf{s}])。 因此,(mu)和(sigma)的计算公式为:
第二部分是一个采样模块,它用于从高斯分布(mathcal{N}(mu,diag(sigma^2)))中采样隐变量(z)。这里同样使用的是变分自编码器中的重参数化技巧。
第三部分是一个LSTM,用于重构输入文本(s)。它将隐变量(z)作为原始输入,接下来每一步的输入都是前一步的输出。
和一样,该论文的优化目标可以表示如下:
但是,由于DSA是回归任务,因此项(q_{phi}(y|x))的含义与Kingma et al., (2014)中的分类任务不同,并且难以得出(log p_{ heta}(x))的ELBO。 因此,对于未标注的数据,损失函数(mathcal{L}(x,y))中的情感得分(y)由情感预测模块给出。对于已标注数据,还有一个用于回归损失的项。模型的最终目标函数是:
(alpha)用来衡量回归损失的重要性,(mathcal{F})是回归损失函数,论文中用的是平均绝对误差MAE。
在Kingma et al., (2014)中提出的半监督VAE架构中,标签(y)也被当作隐变量,并与(z)组合以重构输入样本(x)。这篇论文的做法不同,解码模块中的隐变量(z)是通过(x)和(y)获得的。因此,隐变量可以同时对文本的情感和语义信息进行编码,这可能对构建高质量的隐空间有利。另外,根据其他研究者的发现,情绪得分通常是不平衡的,并且不遵循高斯分布,这将导致传统半监督VAE模型出现额外的KL散度。这篇论文认为这种方式生成的隐空间可能会更平滑。
在该模型中,未标注数据的情感分数(y)由情感预测模块预测,并且解码模块依赖于预测的情感分数以及文本编码来重构输入文本。因此,为了更好地重构输入文本,情绪预测模块对标记和未标记的文本会进行更准确的情绪预测。因此,作者认为这种方法可以利用未标注数据中的有用信息来训练DSA模型。
