kafka + sparkStreaming 有什么好处:
1、解耦 2、缓冲 (系统之间解耦合、峰值压力缓冲、异步通信)
kafka消息队列的特点:
可靠性保证: 自己不丢数据,消费者不丢数据
消息系统的特点:生产者消费者模式 ,FIFO
--partition内部是FIFO的,partition之间不是FIFO的,当然我们可以把一个topic设为一个pertition,这样就是严格的FIFO ,
高性能: 单节点支持上千个客户端,百MB/S吞吐
持久性:消息直接持久化到磁盘上且性能好
--直接写到磁盘里面去,就是直接append到磁盘里面去,这样的好处是持久化,数据不会丢失,第二个好处是顺序写,然后消费数据也是顺序读,所以持久化的同时还能保证顺序读写。
分布式: 数据副本冗余,流量负载均衡、可扩展
--分布式,数据副本,也就是一份数据可以到不用的broker上去,也就是当一份数据磁盘坏掉的时候,数据不会丢失,比如3个副本,就是在3个机器磁盘都坏掉的情况下,数据才会丢失
很灵活: 消息长时间持久化 + client 维护消费状态
--消费方式非常的灵活,第一原因是消息持久化的时间跨度长,一天或者一个星期,第二消费者可以自己维护消费到那个地方了,可以自定义消费偏移量
kafka是分布式消息系统,默认直接将数据存储到磁盘,保存7天
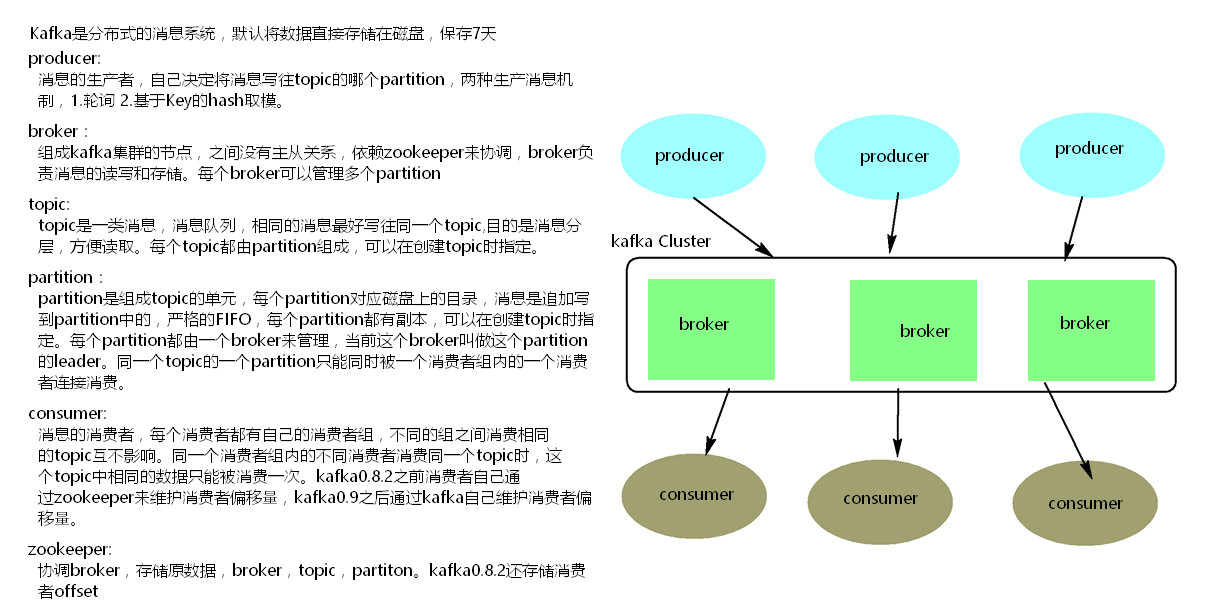
搭建kafak集群:
一、kafka0.8.2版本集群的搭建:
1、上传kafka0.82的安装包
2、解压安装包 tar -zxvf kafka-0.8.2
3、修改配置文件 cd /kafka-0.8.2/config vim servere.properties
配置文件中需要修改的内容:
broker.id = 0 =》 代表第一个broker节点
broker.id = 1 => 代表第二个broker节点
broker.id = 2 = > 代表第三个broker节点
配置通信端口号: port = 9092
log.dirs = /kafka.logs (配置kafka数据存储的文件夹位置)
配置zookeeper :
zookeeper.connect = mynode3:2181,mynode4:2181,mynode5:2181
配置完成之后,对配置文件就行保存
4、上传kafka启动脚本 (启动脚本的作用,在kafka启动之后,保证不会占用通信节点的窗口,让启动信息在窗口后台去运行 )
脚本上传的位置: kafka-0.8.2.2 文件夹的第一级目录之中 ,位置如果放置错误,启动脚本将会失效,需要自己修改脚本中的启动路劲
5、分发文件到其他节点 scp -r ./kafka_2.10.0.8.2.2/ mynode2:`pwd`
6、非脚本命令启动kafka: 进去bin目录 ./kafka-server-start.sh ../config/server.propoerties
kafka创建topic的命令:
./kafka-topics.sh --zookeeper mynode3:2181,mynode4:2181,mynode5:2181 --create --topic topic0627 --partitions 3 --replication-factor 3
kafka删除topic的命令:
./kafka-topics.sh --zookeeper mynode3:2181,mynode4:2181,mynode5:2181 --delete --topic topic0627
执行删除命令之后,topic节点不会被立即的删除,但是会给topic添加一个删除标记,等一周之后再进行删除
如果需要立即对topic节点进行删除,需要在配置文件中配置一个删除参数
在server.properties文件中配置 delete.topic.enable = true 配置成功之后,就能对数据进行删除了
spark1.6+kafka0.8.2
