本文将通过演示告诉你:MySQL中派生表(Derived Table)是什么?以及MySQL对它的优化。
Background
有如下一张表:
mysql> desc city; +------------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +------------+-------------+------+-----+---------+-------+ | country | varchar(40) | YES | | NULL | | | population | int(11) | YES | | NULL | | | city | varchar(40) | YES | | NULL | | +------------+-------------+------+-----+---------+-------+
例如,如果首先考虑选择人口超过10,000人的城市,然后选择那些位于德国的城市,那么可以写这个SQL:
SELECT * FROM (SELECT * FROM city WHERE population > 10*1000) AS big_city WHERE big_city.country='Germany';
使用 EXPLAIN 命令查看执行计划:
mysql> EXPLAIN SELECT * FROM (SELECT * FROM city WHERE population > 1*1000) AS big_city WHERE big_city.country='Germany' ; +----+-------------+------------+------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+------------+------+---------------+------+---------+------+------+-------------+ | 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 4068 | Using where | | 2 | DERIVED | City | ALL | Population | NULL | NULL | NULL | 4079 | Using where | +----+-------------+------------+------+---------------+------+---------+------+------+-------------+ 2 rows in set (0.60 sec)
注意:mysql 5.7 需要设置 derived_merge=off,才会有上面的结果。否则MySQL会把临时表合并到外层查询,具体可参见我的另一篇文章《MySQL中的两种临时表》。
MySQL 的做法是:
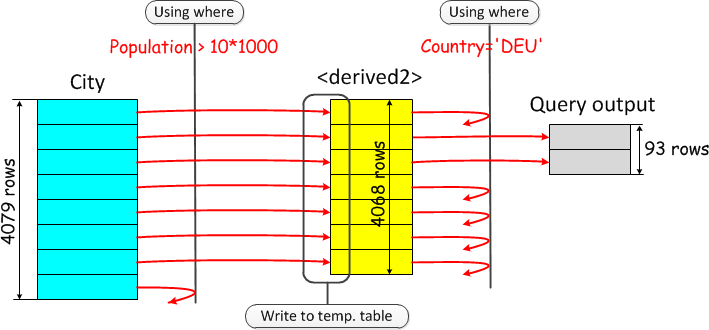
经历如下3个步骤:
- 执行子查询:(SELECT * FROM city WHERE population > 1*1000),正如查询语句中的那样;
- 把子查询的结果写到临时表 big_city ;
- 回读,应用上层SELECT的WHERE条件 big_city.country='Germany' 。
执行这样的子查询是非常低效的,因为扫描基表 city 时没有使用父选择(country ='Germany')的高选择性条件。 我们从City表中读取太多记录,然后我们必须将它们写入一个临时表并再次读取,然后才能过滤掉它们。
Derived table merge in action
如果在MariaDB / MySQL 5.6中运行此查询,则可以得到以下结果:
MariaDB [world]> EXPLAIN SELECT * FROM (SELECT * FROM City WHERE Population > 1*1000) AS big_city WHERE big_city.Country='Germany'; +----+-------------+-------+------+--------------------+---------+---------+-------+------+------------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+--------------------+---------+---------+-------+------+------------------------------------+ | 1 | SIMPLE | City | ref | Population,Country | Country | 3 | const | 90 | Using index condition; Using where | +----+-------------+-------+------+--------------------+---------+---------+-------+------+------------------------------------+ 1 row in set (0.00 sec)
从上面的结果可以看出:
- 只有一行输出,说明子查询已经被合并到上级的 SELECT 语句;
- 通过Country列访问City表,Country='Germany' 用来构建表上的 ref 访问;
- 查询将读取大约90行,这是对于之前的4079行读加上4068行临时表读/写的一个很大的改进。
Factsheet
派生表(FROM子句中的子查询)可以在没有 grouping, aggregates, or ORDER BY ... LIMIT 子句时合并到他们的父查询中。这个优化默认开启,可通过如下关闭:
set @@optimizer_switch='derived_merge=OFF'
不支持该优化的Maria和MySQL版本将执行子查询,这可以导致一个著名的Bug(see e.g. MySQL Bug #44802),从MariaDB 5.3+和MySQL 5.6+ 开始,EXPLAIN命令立即执行,无论 derived_merge 如何设置。
Reference: