计算机内存中的对齐
一、什么是对齐,以及为什么要对齐
⒈现代计算机中内存空间都是按照byte划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定变量的时候经常在特定的内存地址访问,这就需要各类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐。
⒉对齐的作用和原因:各个硬件平台对存储空间的处理上有很大的不同。一些平台对某些特定类型的数据只能从某些特定地址开始存取。其他平台可能没有这种情况, 但是最常见的是如果不按照适合其平台的要求对数据存放进行对齐,会在存取效率上带来损失。比如有些平台每次读都是从偶地址开始,如果一个int型(假设为 32位)如果存放在偶地址开始的地方,那么一个读周期就可以读出,而如果存放在奇地址开始的地方,就可能会需要2个读周期,并对两次读出的结果的高低 字节进行拼凑才能得到该int数据。显然在读取效率上下降很多。这也是空间和时间的博弈。
二、对齐的实现
通常,我们写程序的时候,不需要考虑对齐问题。编译器会替我们选择适合目标平台的对齐策略。当然,我们也可以通知给编译器传递预编译指令而改变对指定数据的对齐方法。
但是,正因为我们一般不需要关心这个问题,所以因为编辑器对数据存放做了对齐,而我们不了解的话,常常会对一些问题感到迷惑。最常见的就是struct数据结构的sizeof结果,出乎意料。为此,我们需要对对齐算法所了解。
对齐的算法:
由于各个平台和编译器的不同,现以本人使用的gcc version 3.2.2编译器(32位x86平台)为例子,来讨论编译器对struct数据结构中的各成员如何进行对齐的。
设结构体如下定义:
struct A {
int a;
char b;
short c;
};
结构体A中包含了4字节长度的int一个,1字节长度的char一个和2字节长度的short型数据一个。所以A用到的空间应该是7字节。但是因为编译器要对数据成员在空间上进行对齐。
所以使用sizeof(strcut A)值为8。
现在把该结构体调整成员变量的顺序。
struct B {
char b;
int a;
short c;
};
这时候同样是总共7个字节的变量,但是sizeof(struct B)的值却是12。
下面我们使用预编译指令#pragma pack (value)来告诉编译器,使用我们指定的对齐值来取代缺省的。
#progma pack ⑵/*指定按2字节对齐*/
struct C {
char b;
int a;
short c;
};
#progma pack () /*取消指定对齐,恢复缺省对齐*/
sizeof(struct C)值是8。
修改对齐值为1:
#progma pack ⑴/*指定按1字节对齐*/
struct D {
char b;
int a;
short c;
};
#progma pack () /*取消指定对齐,恢复缺省对齐*/
sizeof(struct D)值为7。
对于char型数据,其自身对齐值为1,对于short型为2,对于int,float,double类型,其自身对齐值为4,单位字节。
这里面有四个概念值:
1)数据类型自身的对齐值:就是上面交代的基本数据类型的自身对齐值。
2)指定对齐值:#pragma pack (value)时的指定对齐值value。
3)结构体或者类的自身对齐值:其成员中自身对齐值最大的那个值。
4)数据成员、结构体和类的有效对齐值:自身对齐值和指定对齐值中较小的那个值。
有了这些值,我们就可以很方便的来讨论具体数据结构的成员和其自身的对齐方式。有效对齐值N是最终用来决定数据存放地址方式的值,最重要。有效对齐N,就是表示“对齐在N上”,也就是说该数据的"存放起始地址%N=0".而数据结构中的数据变量都是按定义的先后顺序来排放的。第一个数据变量的起始地址就是 数据结构的起始地址。结构体的成员变量要对齐排放,结构体本身也要根据自身的有效对齐值圆整(就是结构体成员变量占用总长度需要是对结构体有效对齐值的整 数倍,结合下面例子理解)。这样就不难理解上面的几个例子的值了。
例子分析:
分析例子B;
struct B {
char b;
int a;
short c;
};
假设B从地址空间0x0000开始排放。该例子中没有定义指定对齐值,在笔者环境下,该值默认为4。第一个成员变量b的自身对齐值是1,比指定或者默认指 定对齐值4小,所以其有效对齐值为1,所以其存放地址0x0000符合0x0000%1=0.第二个成员变量a,其自身对齐值为4,所以有效对齐值也为 4,所以只能存放在起始地址为0x0004到0x0007这四个连续的字节空间中,复核0x0004%4=0,且紧靠第一个变量。第三个变量c,自身对齐 值为2,所以有效对齐值也是2,可以存放在0x0008到0x0009这两个字节空间中,符合0x0008%2=0。所以从0x0000到0x0009存 放的都是B内容。再看数据结构B的自身对齐值为其变量中最大对齐值(这里是b)所以就是4,所以结构体的有效对齐值也是4。根据结构体圆整的要求, 0x0009到0x0000=10字节,(10+2)%4=0。所以0x0000A到0x000B也为结构体B所占用。故B从0x0000到0x000B 共有12个字节,sizeof(struct B)=12。
C++ 类的存储空间大小
上面举的例子都是关于结构体内存的计算,其实类的内存计算方法也是一样,C++中对象占存储区间的主要是非static的数据成员占用内存,成员函数是不占用内存中类的对象的字节。 (注意类本身不占内存,实例化后的对象才占用内存,但都可以用sizeof(类名/对象名)来查看占用内存大小)。为什么只是包含非static数据对象呢?因为static数据并不属于类的任何一个对象,它是类的属性,而不是具体某一个对象的属性,在整个内存区域中只有一个内存区域存储对应的static数据,也就是所有的类对象共享这个数据,所以不能算做具体某一个对象或者类型的内存空间。(我们知道static数据是非对象的属性,而是类的属性,他不能算是某一个对象或者类型的存储空间,在类定义中只能声明,初始化只能在类外执行)
注意:派生类占用内存大小与继承的方式无关,可能只是访问不到而已。
当类中有虚函数时:
在一个类对象存储空间中,第一个位置需要4个字节来存储一个指针。这个指针是指向改类的虚函数表的。也就是这个指针的值就是该类的虚函数表的地址。所以就比上面说的多了4个字节。
例如:
class D
{
public:
virtual void f(){};
double d;
}
D d;
sizeof(d)=16;
派生类内存大小
例如:
class E:D
{
int d0;
char c;
int d1;
};
E e;
sizeof(e)=32;
解释:
基类中有虚函数,所以派生类对象一开始要4个字节存储指向虚函数表的指针。(即使子类也有新的虚函数,但实例中只有一个虚函数表,多了一个4个字节存储的指向虚函数表的指针。新加的虚函数地址加在继承的虚函数表后面。)可参见我的虚函数继承
然后继承D中的数据成员double d;
它要8字节对齐,所以前面空4个字节。
下面就开始存储d0,c,d1.最后类对齐可计算得到32.
因此可以认为派生类对象的存储空间大小为:
基类存储空间 + 派生类特有的非static数据成员的存储空间
继承类中不能再添加虚函数的存储空间(因为所有的虚函数共享一块内存区域),而仅仅需要考虑派生类中心添加进来的非static数据成员的内存空间大小。
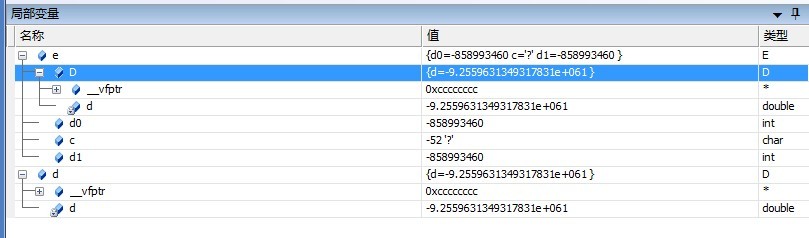
从上图可看出vptr存储在内存开始位置,子类先继承父类内存,后再是自己新加的内存。