最近一段时间在学习spark,以下是学习过程中的一些总结。
1、Q:RDD中的Transformation 和Action操作都有哪些?
A:整理如下:

Transformation 与 Action 的区别还在于,对 RDD 进行 Transformation 并不会触发计算:Transformation 方法所产生的 RDD 对象只会记录住该 RDD 所依赖的 RDD 以及计算产生该 RDD 的数据的方式;只有在用户进行 Action 操作时,Spark 才会调度 RDD 计算任务,依次为各个 RDD 计算数据。
2、Q:spark中采用RDD的优势有哪些?
A:Spark RDD 的亮点在于如下两点:
①:确定且基于血统图的数据恢复重计算过程
②:面向记录集合的转换 API
比起类似于分布式内存数据库的那种分布式共享内存模型,Spark RDD 巧妙地利用了其不可变和血统记录的特性实现了对分布式内存资源的抽象,很好地支持了批处理程序的使用场景,同时大大简化了节点失效后的数据恢复过程。
3、Q:rdd数据本身是如何存储的呢,又是如何调度读取的?
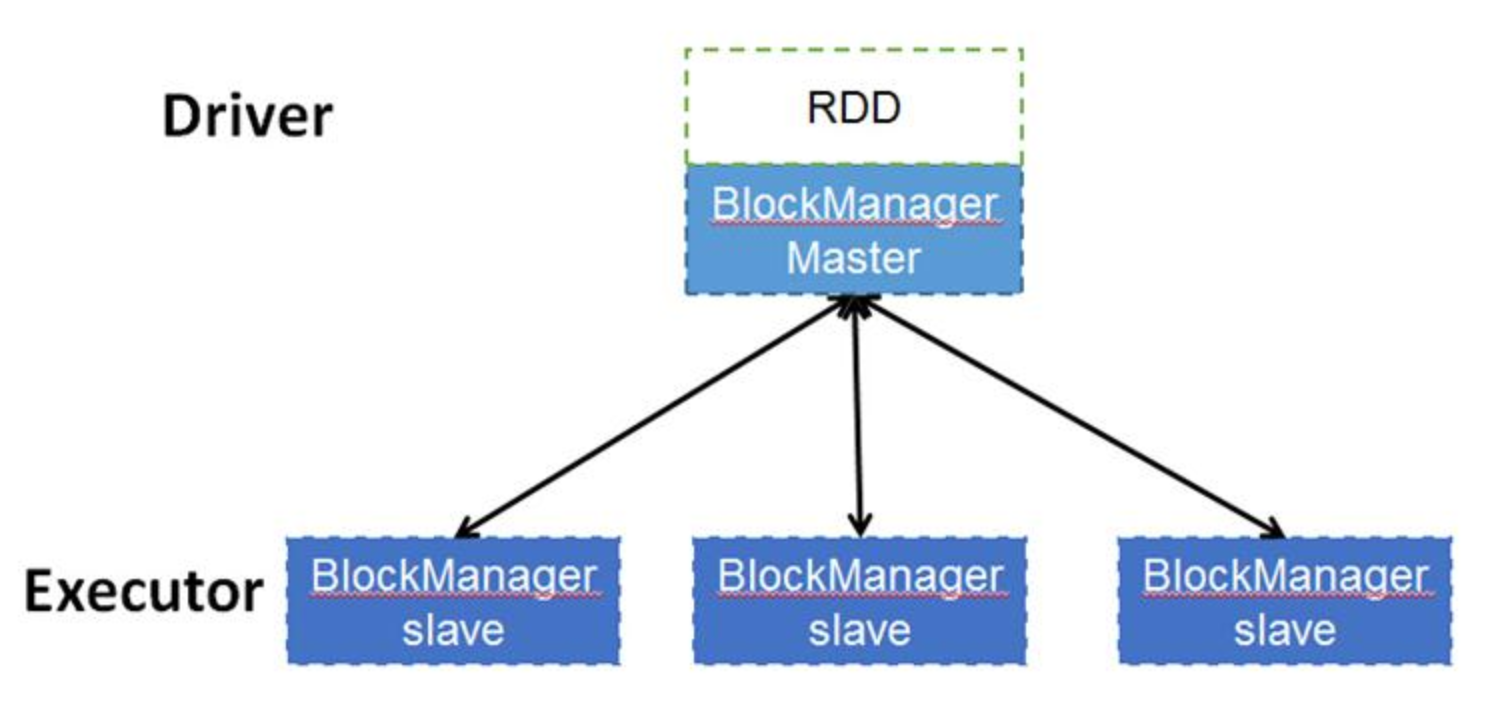
A:spark大部分时候都是在集群上上运行的,那么数据本身一定是也是分布式存储的,数据是由每个Excutor的去管理多个block的,而元数据本身是由driver的blockManageMaster来管理,当每个excutor创建的时候也会创建相对应的数据集管理服务blockManagerSlave,当使用某一些block时候,slave端会创建block并向master端去注册block,同理删除某些block时候,master向slave端发出申请,再有slave来删除对应的block数据。由此可见,实际上物理数据都excutor上,数据的关系管理由driver端来管理。
rdd架构图如下:
4、Q:RDD中为什么要划分宽窄依赖?
A:①:Narrow dependency可以方便地以流水线的形式执行计算,即从头到尾一串chain下来。而wide dependency必须要等所有的parent RDD的结果都准备好以后再执行计算
②:Narrow dependency失败以后,Spark只需要重新计算失败的parent RDD即可;而对于wide dependency来说,一失败可能导致某些分区丢失,必须整体重新进行计算
5、Q:Spark中Job Scheduling是什么样的一个过程?
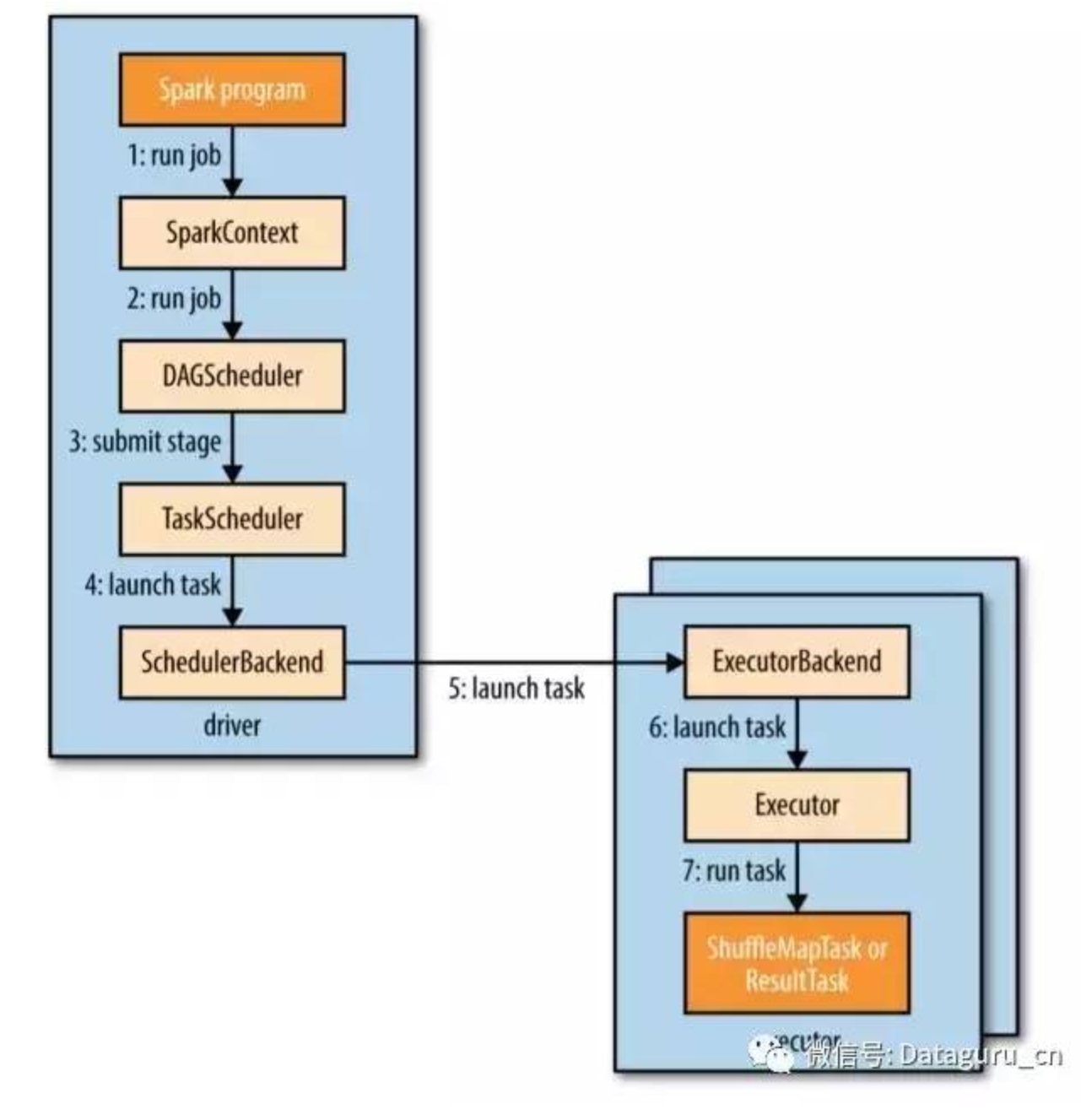
A:简单来说,Spark会将提交的计算划分为不同的stages,形成一个有向无环图(DAG)。Spark的调度器会按照DAG的次序依次进行计算每个stage,最终得到计算结果。执行计算的几个重要的类或接口如下:DAGScheduler、ActiveJob、Stage、Task、TaskScheduler、SchedulerBackend。
这里面最为重要的就是 DAGScheduler 了,它会将逻辑执行计划(即RDD lineage)转化为物理执行计划(stage/task)。之前我们提到过,当开发者对某个RDD执行action的时候,Spark才会执行真正的计算过程。当开发者执行action的时候,SparkContext会将当前的逻辑执行计划传给DAGScheduler,DAGScheduler会根据给定的逻辑执行计划生成一个Job(对应ActiveJob类)并提交。每执行一个acton都会生成一个ActiveJob。
提交Job的过程中,DAGScheduler会进行stage的划分。Spark里是按照shuffle操作来划分stage的,也就是说stage之间都是wide dependency,每个stage之内的dependency都是narrow dependency。这样划分的好处是尽可能地把多个narrow dependency的RDD放到同一个stage之内以便于进行pipeline计算,而wide dependency中child RDD必须等待所有的parent RDD计算完成并且shuffle以后才能接着计算,因此这样划分stage是最合适的。
划分好的stages会形成一个DAG,DAGScheduler会根据DAG中的顺序先提交parent stages(如果存在的话),再提交当前stage,以此类推,最先提交的是没有parent stage的stage。从执行角度来讲,一个stage的parent stages执行完以后,该stage才可以被执行。最后一个stage是产生最终结果的stage,对应ResultStage,而其余的stage都是ShuffleMapStage。
提交stage的时候,Spark会根据stage的类型生成一组对应类型的Task(ResultTask或ShuffleMapTask),然后将这些Task包装成TaskSet提交到TaskScheduler中。一个Task对应某个RDD中的某一个partition,即一个Task只负责某个partition的计算:
TaskScheduler会向执行任务的后端(SchedulerBackend,可以是Local, Mesos, Hadoop YARN或者其它集群管理组件)发送ReviveOffers消息,对应的执行后端接收到消息以后会将Task封装成TaskRunner(Runnable接口的实例),然后提交到底层的Executor中,并行执行计算任务。
整个Spark Context执行task的步骤图:
6、Q:Executor个数和机器个数的关系,一个机器就是一个Executor吗?
A:每个节点可以运行多个 Executor,一个 Executor 相当于一个进程;
一个 Executor 可以有多个 core,一个 core 执行一个 task,一个 core 相当于 Executor 进程里的一个线程;