一、学习视频
https://www.bilibili.com/video/BV1oE411s7h7?p=44
二、SparkSQL简介
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用。
三、DataFrame概述
与RDD类似,DataFrame也是一个分布式数据容器。然而DataFrame更像传统数据库的二维表格,除了数据以外,还记录数据的结构信息,即schema。同时,与Hive类似,DataFrame也支持嵌套数据类型(struct、array和map)。
四、DataFrame的创建
Spark2.0以上版本,使用SparkSession接口替代SparkContext及HiveContext接口来实现数据的加载,转换,处理。SparkSession对象可以将各种各样的数据加载进来,构成DataFame,然后再将DataFrame转换成其自身的表,对这个表就可以进行SQL查询。
在编写独立应用程序时,可以使用以下三行代码生成一个SparkSession对象。

如果在pyspark中,会默认生成一个SparkCntext对象sc以及一个SparkSession对象spark
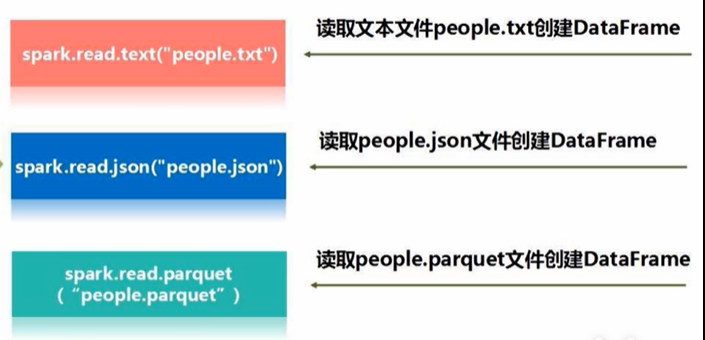
SparkSession对象读取数据的三种方式: