Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
Abstract
我们提出了一种技术,用于为基于卷积神经网络(CNN)的大型模型的决策生成“可视化解释”,使它们更加透明和可解释。
我们的方法——Gradient-weighted Class Activation Mapping (Grad-CAM),使用流入最后卷积层的任何目标概念的梯度(如在一个分类网络的“狗”或在网络字幕中一系列的词)产生一个粗定位map,用于强调图像中用于预测指定概念的重要区域。
与以前的方法相比,Grad-CAM适用于各种各样的CNN model-families: (1) 使用全连接层的CNNs(例如VGG), (2) 用于结构化输出(如字幕)的CNNs,(3)用于有着多模式输入(如视觉问答)任务的CNNs或强化学习,所有的实现都不需要架构更改或重新训练。我们将Grad-CAM与现有的细粒度可视化结合起来,创建一个高分辨率的分类可视化、Guided Grad-CAM,并将其应用于图像分类、图像字幕和视觉问答(visual question answering,VQA)模型,包括基于resnet的架构。
在图像分类模型的上下文中,我们的可视化(a)提供这些模型的失效模式的原因(说明看似不合理的预测有合理的解释),(b)优于在ILSVRC-15 weakly-supervised定位任务中的方法,(c)对对抗性扰动具有鲁棒性,(d)更忠实于底层模型,和(e)通过确定数据集的bias,帮助实现模型泛化。
对于图像字幕和VQA,我们的可视化显示,即使是非注意的模型也能学会定位输入图像的区分性区域。
我们设计了一种通过Grad-CAM识别重要神经元的方法,并将其与neuron names[4]结合起来,为模型决策提供文本解释。最后,我们设计并进行了人类研究,以衡量Grad-CAM解释是否帮助用户在深度网络的预测中建立适当的信任,并表明Grad-CAM帮助未经训练的用户成功地区分“较强”的深度网络和“较弱”的深度网络,即使两者做出相同的预测。代码可见https://github.com/ramprs/grad-cam/,带有CloudCV(http://gradcam.cloudcv.org)的demo,视频可见youtu.be/COjUB9Izk6E。
1 Introduction
基于卷积神经网络(CNN)的深度神经模型在各种计算机视觉任务实现了前所未有的突破,从图像分类[33、24]、对象检测[21],语义分割[37]图像字幕[18,55,7,29],视觉问答[3,20,42,46]和最近出现的,视觉对话[11、13、12]和embodied问答[10,23]。虽然这些模型具有优越的性能,但由于它们无法分解为独立的直观组件,因此很难解释[36]。因此,当今天的智能系统出现故障时,它们通常会在没有警告或解释的情况下失败, 导致用户盯着一个不连贯的输出,纳闷系统为什么会这样做。
Interpretability matters. 为了在智能系统中建立信任,并使其有意义地融入我们的日常生活,很明显,我们必须建立“透明”的模型,能够解释为什么它们会预测它们预测的东西。广义上说,这种透明度和解释能力在人工智能(AI)进化的三个不同阶段是有用的。首先,当AI明显弱于人类且还不能可靠部署时(例如,视觉答[3]),透明度和解释的目标是识别失败模式[1,25],从而帮助研究人员将他们的努力集中在最富有成效的研究方向。其次,当人工智能与人类相当并且可可靠部署时(例如,在足够的数据上训练的图像分类[30]),目标是在用户中建立适当的信任和信心。第三,当AI明显比人类强的时候(例如国际象棋或围棋[50]),解释的目标是机器教学[28]——也就是说,机器教会人类如何做出更好的决策。
在准确性和简单性或可解释性之间通常存在权衡。经典的基于规则或专家系统[26]具有高度的可解释性,但不是非常精确(或健壮)。每个阶段都是手工设计的可分解管道,因此被认为更具有可解释性,因为每个单独的组件都假定有一个自然直观的解释。通过使用深层模型,我们牺牲了可解释的模块来实现不可解释的模块,这些模块通过更抽象(更多层次)和更紧密的集成(端到端训练)来实现更好的性能。最近引入的深度残差网络(ResNets)[24]的深度超过200层,并在一些具有挑战性的任务中显示了最先进的性能。这种复杂性使得这些模型难以解释。因此,深层模型开始探索可解释性和准确性之间的范围。
Zhou等人[59]最近提出了一种名为Class Activation Mapping (CAM)的技术,用于识别不包含任何全连接层的受限类图像分类CNNs所使用的鉴别区域。从本质上说,这项工作牺牲了模型的复杂性和性能,以获得模型工作的更大透明度。相反,我们在不改变其架构的情况下使现有的最先进的深度模型具有可解释性,从而避免了可解释性与准确性之间的权衡。我们的方法是一个CAM的泛化[59],适用于广泛的CNN模型家族: (1) 使用全连接层的CNNs(例如VGG), (2) 用于结构化输出(如字幕)的CNNs,(3)用于有着多模式输入(如视觉问答)任务的CNNs或强化学习,无需架构更改或重新训练。
What makes a good visual explanation? 以图像分类[14]为例,该模型用于证明任何目标类别的“良好”的视觉解释应是(a)具有类别区分度的(即在图像中定位该类别)和(b)是高分辨率的(即能捕捉细粒度的细节)。
图1显示了“tiger cat”类(上一行)和“boxer”(狗)类(下一行)的一些可视化结果。像Guided Back-propagation[53]和Deconvolution[57]这样的像素空间梯度可视化方法是高分辨率的,并且突出了图像中的细粒度细节,但是没有类别区分度(图1b和图1h非常相似)。

相比之下,像CAM或我们提出的Gradient-weighted Class Activation Mapping (Grad-CAM)这样的定位方法是具有高度类别可区分度的(图1c中的“猫”解释中只强调了“猫”区域,而没有强调“狗”区域,图1i中也是如此)。
为了结合这两个方法的优点,我们展示了将现有的像素空间梯度可视化方法与Grad-CAM相融合,从而创建具有高分辨率和类别可区分的 Guided Grad-CAM可视化方法是可能的。因此,即使图像中包含了多种可能概念的证据,图像中与任何感兴趣的决策相对应的重要区域也会以高分辨率细节显示出来,如图1d和1j所示。当对“tiger cat”进行可视化显示时,Guided Grad-CAM不仅突出了猫的区域,还突出了猫身上的条纹,这对于预测特定种类的猫很重要。
总的来说,我们的贡献有:
(1)我们介绍一种名为Grad-CAM的类别可区分的定位技术,它可以为任何基于CNN的网络生成可视化解释,而不需要进行架构更改或再训练。我们评估了Grad-CAM的定位(第4.1节)和对模型的忠诚度(第5.3节),在这些方面,它都优于基线的效果。
(2)我们将Grad-CAM应用于现有的top-performing 的分类、字幕(第8.1节)和VQA(第8.2节)模型。对于图像分类,我们的可视化帮助我们了解当前CNNs的失败(第6.1节),表明看似不合理的预测有合理的解释。对于字幕和VQA,我们的可视化显示,普通的CNN + LSTM模型通常在定位区分图像区域方面非常出色,尽管它们没有在grounded image-text对上接受过训练。
(3)我们展示了如何通过揭示数据集中的偏差来帮助诊断错误模式的概念证明。这不仅对泛化很重要,而且对公平和无偏差的结果也很重要,因为社会上越来越多的决策是由算法做出的。
(4)我们提出了用于图像分类和VQA的ResNets[24]的Grad-CAM可视化方法(第8.2节)。
(5)我们使用Grad-CAM中的神经元重要性和[4]中的神经元names,获得模型决策的文本解释(第7节)。
(6)我们在人类身上进行的研究表明(第5节),Guided Grad-CAM解释是具有类别可区分度的,它不仅帮助人类建立信任,而且还帮助未经训练的用户成功地区分出“较强”和“较弱”的网络,即使两者的预测完全相同。
Paper Organization: 论文的其余部分组织如下。在第三节中,我们提出了我们的方法—— Grad-CAM和Guided Grad-CAM。在第4和第5部分,我们评估了Grad-CAM定位能力、类别辨别力、可信度和忠诚度。在第6节中,我们展示了Grad-CAM的一些使用案例,如诊断图像分类CNNs和在数据集中识别偏差。在第7节中,我们提供了一种方法,去使用Grad-CAM以获得文本解释。在第8节中,我们将展示如何将Grad-CAM应用于视觉和语言模型——如图像字幕和视觉问答(VQA)。
2 Related Work
我们的工作借鉴了最近在CNN可视化、模型信任评估和弱监督定位方面的工作。
Visualizing CNNs. 许多之前的作品[51,53,57,19]通过突出“重要”像素(即这些像素强度的变化对预测分数的影响最大)来可视化CNN的预测。具体来说,Simonyan等人的[51]可视化使预测类分数w.r.t.像素强度的偏导数,而Guided Backprop-agation[53]和Deconvolution[57]对“raw”梯度进行修改,从而导致质量改进。这些方法在[40]中进行了比较。尽管生成了细粒度的可视化结果,但这些方法并不具有类别区分度。不同类的可视化结果几乎是相同的(参见图1b和图1h)。
其他可视化方法合成图像以最大限度地激活一个网络单元[51,16]或反转一个潜在表示[41,15]。尽管这些图像可以是高分辨率的和类别可区分的,但它们不特定于单个输入图像,而是对整个模型进行可视化。
Assessing Model Trust. 受[36]可解释性概念和[47]模型信任评估的启发,我们通过类似于人类研究[47]的方式对Grad-CAM可视化进行评估,以表明它们可以成为用户评估和信任自动化系统的重要工具。
Aligning Gradient-based Importances. Selvaraju等人[48]提出了一种使用我们工作中引入的基于梯度的神经元重要性的方法,并将其映射到人类的特定类领域知识,以便学习新的类的分类器。在未来的工作中,Selvaraju等人[49]提出了一种方法,将基于梯度的重要性与人类注意力maps进行比对,以便于使视觉和语言模型相一致。
Weakly-supervised localization. 另一项相关工作是CNNs环境下的弱监督定位,其任务是仅使用整体图像类标签对图像中的对象进行定位[8,43,44,59]。
与我们的方法最相关的是用于定位[59]的 Class Activation Mapping (CAM) 方法。该方法修改了图像分类CNN架构,用卷积层和全局平均池化[34]代替全连接层,从而实现了特定类的feature map。其他人研究了使用全局最大池化[44]和log-sum-exp池化[45]的类似方法。
CAM的缺点是需要在softmax层之前有feature maps,所以它只适用于在预测之前对卷积maps进行全局平均pooling的特定类型CNN架构(即conv feature maps→全局平均pooling→softmax层)。在某些任务(如图像分类)上,这样的架构可能无法达到与一般网络相比的精度,或者可能根本不适用于其他任务(如图像字幕或VQA)。我们引入了一种新的方法,利用梯度信号结合feature maps,不需要对网络结构进行任何修改。这使得我们的方法可以应用于现成的基于CNN的架构,包括用于图像字幕和视觉问答的架构。对于全卷积架构,CAM是Grad-CAM的一种特殊情况。
其他方法通过对输入图像的扰动进行分类来实现定位。Zeiler和Fergus[57]通过遮挡patches和对遮挡图像进行分类来干扰输入,通常导致相关物体被遮挡时分类分数较低。这一原理适用于[5]的定位。Oquab等人[43]对包含一个像素的多个patch进行分类,然后对这些patch的评分进行平均,得到像素的分类评分。与这些不同的是,我们的方法一次性实现了定位;它只需要对每个图像进行一次前向和partial后向传递,因此通常效率要高一个数量级。在最近的工作中,Zhang等人[58]引入了contrastive Marginal Winning Probability (c-MWP),这是一种Winner-Take-All的概率公式,用于建模用于神经分类模型的,可以突出区分区域的top-down的注意力。其在计算上比Grad-CAM昂贵,并且只适用于图像分类CNNs。此外,Grad-CAM在定量和定性评价方面优于c-MWP(见4.1节和D节)。
3 Grad-CAM
许多之前的研究已经断言,CNN中更深层次的表征捕获了更高层次的视觉构造[6,41]。此外,卷积层自然保留了在全连接的层中丢失的空间信息,因此我们可以期待最后的卷积层在高级语义和详细空间信息之间有最好的折衷结果。这些层中的神经元在图像中寻找特定类的语义信息(比如物体部分)。Grad-CAM使用流进CNN最后一个卷积层的梯度信息,为每个神经元分配一个感兴趣的特定决策的重要性值。虽然我们的技术是相当普遍的,因为它可以用来解释深层网络的任何层的激活,但在这项工作中,我们只关注于解释输出层的决策。
如图2所示,
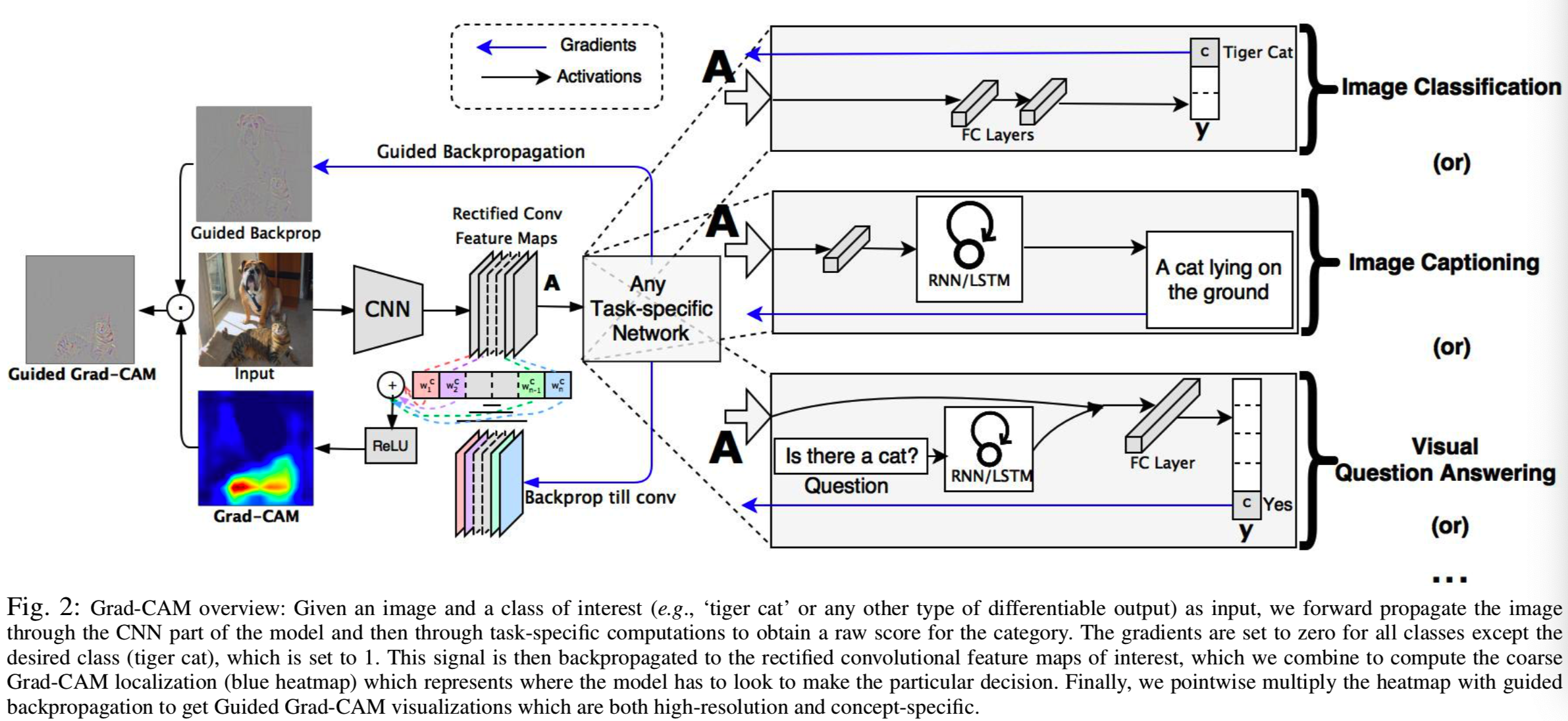
为了获得任意类c,宽为u、高为v的类别可区分的定位map ![]() ,我们首先计算类c分数yc(before the softmax)关于一个卷积层的feature map激活Ak的梯度
,我们首先计算类c分数yc(before the softmax)关于一个卷积层的feature map激活Ak的梯度![]() 。然后对该梯度流的宽和高维度(分别用i和j标明)进行全局平均池化,去获得神经元重要性权重
。然后对该梯度流的宽和高维度(分别用i和j标明)进行全局平均池化,去获得神经元重要性权重![]() :
:
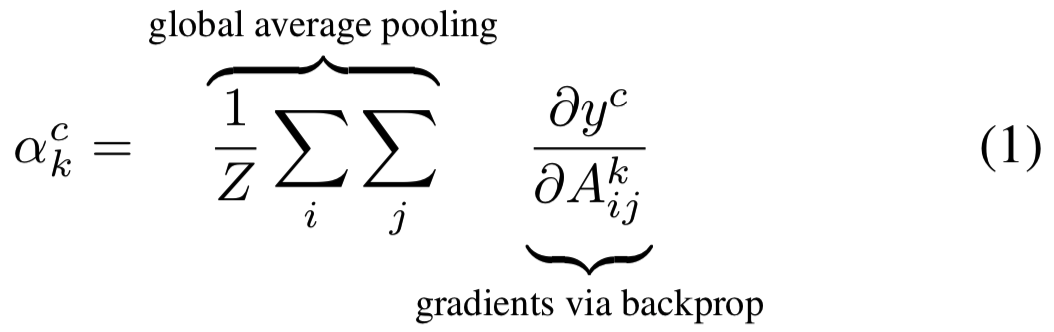
在计算的![]() 同时后向传播关于激活的梯度,精确的计算相当于权重矩阵和关于激活函数的梯度的连续矩阵乘积,直到梯度被传播到最后的卷积层。因此,权重
同时后向传播关于激活的梯度,精确的计算相当于权重矩阵和关于激活函数的梯度的连续矩阵乘积,直到梯度被传播到最后的卷积层。因此,权重![]() 表示A以下深度网络一个partial linearization,用于捕获对于目标类c来说,feature map k的重要性。
表示A以下深度网络一个partial linearization,用于捕获对于目标类c来说,feature map k的重要性。
我们对正向激活map A进行加权组合,然后使用ReLU函数:
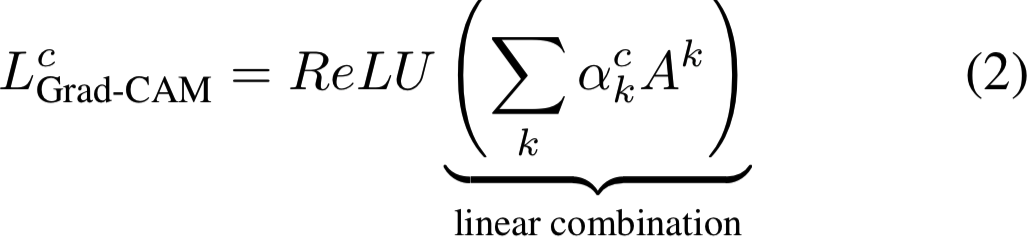
注意,这将得到一个与卷积特征图(如VGG[52]和AlexNet[33]网络的最后一个卷积层为14×14)相同大小的粗略heatmap。我们对maps的线性组合使用ReLU,因为我们只对对感兴趣的类别有positive影响的特征感兴趣,例如,为了增加yc,需要增加像素强度。negative像素很可能属于图像中的其他类别。正如预期的那样,如果没有这个ReLU,定位maps有时会突出显示更多想要的类,并且在定位方面执行得更差。图1c、1f和1i、1l分别显示了“tiger cat”和“boxer(狗)”的Grad-CAM可视化结果。消融研究在B部分。
一般来说,yc不必是一个图像分类CNN产生的类分数。它可以是任何可区分的激活,包括标题中的文字或对问题的回答。
3.1 Grad-CAM generalizes CAM
在本节中,我们将讨论Grad-CAM和Class Activation Mapping(CAM)[59]之间的联系,并正式证明Class Activation Mapping将CAM推广到各种基于CNN的架构中。回想一下,CAM为一个图像分类CNN生成了一个定位maps,它具有一种特定的架构,其中全局平均池化的卷积feature map直接被输入softmax。特别的是,让倒数第二层生成K个feature maps ![]() ,使用i、j标明其中的一个元素。所以
,使用i、j标明其中的一个元素。所以![]() 表示feature map Ak位置(i,j)上的激活。然后该feature maps使用Global Average Pooling(GAP)进行空间池化,然后线性转换去生成每个类c的分数Yc,
表示feature map Ak位置(i,j)上的激活。然后该feature maps使用Global Average Pooling(GAP)进行空间池化,然后线性转换去生成每个类c的分数Yc,
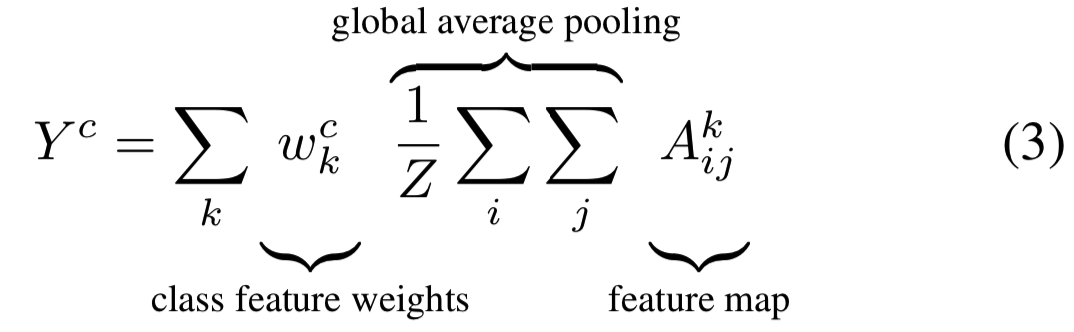
(其实就是对最后一个卷积层的输出 + GAP + fc层 = score)
定义Fk为全局平均池化输出:
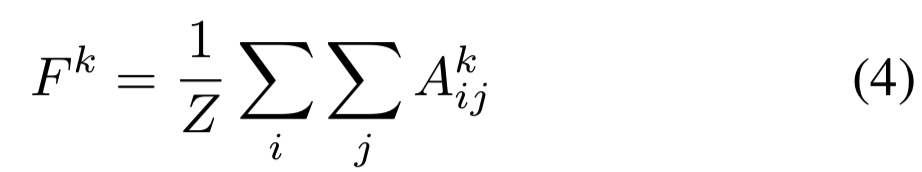
使用下面的公式计算最后的分数:
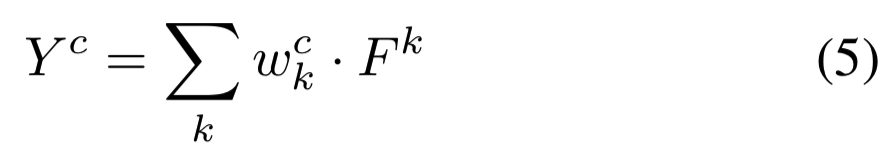
其中![]() 是连接第k个feature map和第c个类的权重。计算类c分数(Yc)关于feature map Fk的梯度:
是连接第k个feature map和第c个类的权重。计算类c分数(Yc)关于feature map Fk的梯度:

计算(4)关于![]() 的偏导数,我们可得
的偏导数,我们可得![]() 。替换(6)中式子,得:
。替换(6)中式子,得:
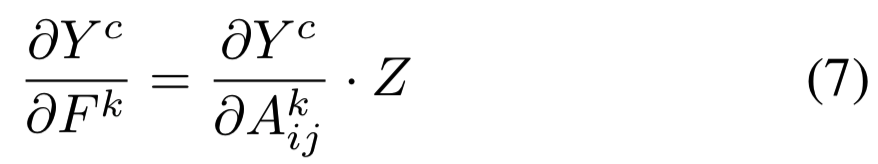
从等式(5)我们得到![]() 。因此得:
。因此得:
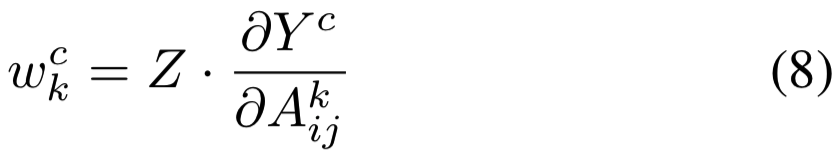
对等式(8)两边的所有像素(i,j)求和:

因为Z和![]() 与(i,j)无关,所以等式(9)可以写成:
与(i,j)无关,所以等式(9)可以写成:
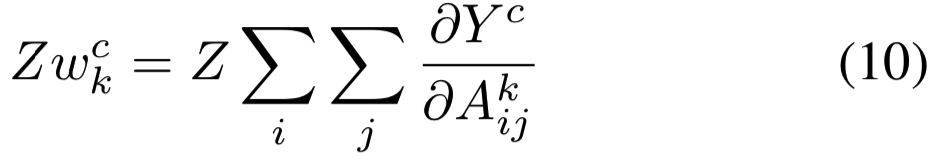
注意,Z是feature map像素的数量(![]() )。因此最后式子可得:
)。因此最后式子可得:
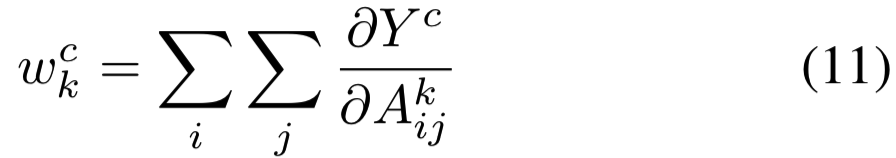
等式(10)再乘上在可视化过程中进行标准化的比例常数(1/Z),![]() 就等价于等式(1)中Grad-CAM使用的
就等价于等式(1)中Grad-CAM使用的![]() 了。因此,Grad-CAM是CAM的严格泛化。这种泛化使我们能够从基于CNN的模型中生成可视化的解释,这些模型将卷积层与更复杂的交互作用串联起来,比如图像字幕和VQA(8.2节)。
了。因此,Grad-CAM是CAM的严格泛化。这种泛化使我们能够从基于CNN的模型中生成可视化的解释,这些模型将卷积层与更复杂的交互作用串联起来,比如图像字幕和VQA(8.2节)。
3.2 Guided Grad-CAM
虽然Grad-CAM具有类别区分和定位相关图像区域的能力,但它缺乏像像素空间梯度可视化方法(Guided Backpropagation [53], Deconvolution[57])那样突出细粒度细节的能力。Guided Backpropagation使相对于图像的梯度可视化,在通过ReLU层反向传播时,负梯度被抑制。直观地说,它的目的是捕获神经元检测到的像素,而不是抑制神经元的像素。如图1c所示,Grad-CAM可以很容易地对cat进行定位;然而,从粗略的heatmap中还不清楚为什么网络预测这一特殊实例为“tiger cat”。为了结合两者的优点,我们通过element-wise的乘法将引导Guided Backpropagation和Grad-CAM可视化融合在一起(![]() 首先使用双线性插值向上采样到输入图像分辨率)。图2左下角说明了这种融合。这种可视化既高分辨率(当感兴趣的类别是“tiger cat”时,它会识别出重要的“tiger cat”特征,比如条纹、尖尖的耳朵和眼睛),又具有类别可区分性(它会突出“tiger cat”,但不突出“boxer(狗)”)。用Deconvolution代替Guided Backpropagation可以得到类似的结果,但是我们发现Deconvolution可视化有伪影,而且Guided Backpropagation通常噪声更小。
首先使用双线性插值向上采样到输入图像分辨率)。图2左下角说明了这种融合。这种可视化既高分辨率(当感兴趣的类别是“tiger cat”时,它会识别出重要的“tiger cat”特征,比如条纹、尖尖的耳朵和眼睛),又具有类别可区分性(它会突出“tiger cat”,但不突出“boxer(狗)”)。用Deconvolution代替Guided Backpropagation可以得到类似的结果,但是我们发现Deconvolution可视化有伪影,而且Guided Backpropagation通常噪声更小。
3.3 Counterfactual Explanations
对Grad-CAM稍加修改,我们就可以得到一些解释,这些解释强调了对那些可能使网络改变其预测的区域的支持。因此,移除这些地区的概念将使模型对其预测更有信心。我们把这种解释方式称为反事实解释(counterfactual explanations)。
具体地说,我们对卷积层的特征映射A的yc(类c的分数)的梯度取反。因此,重要性的权重,现在成为:

如(2)所示,我们对正向激活maps A进行加权求和,加权后的权重为![]() ,然后再进行ReLU,得到反事实的解释,如图3所示。
,然后再进行ReLU,得到反事实的解释,如图3所示。

4 Evaluating Localization Ability of Grad-CAM
4.1 Weakly-supervised Localization
在本节中,我们评估了Grad-CAM在图像分类中的定位能力。ImageNet定位挑战[14]除了需要提供分类标签外,还需要提供边界框。与分类相似,对top-1和top-5预测类别进行评价。
给定一幅图像,我们首先从网络中获取类预测,然后为每个预测类生成Grad-CAM maps,并以最大强度的15%作为阈值对其进行二值化(即大于该阈值的地方标1,小于标0)。这样就产生了连接的像素片段,我们在最大的单个片段周围画了一个边框。注意,这是一种弱监督的定位——在训练期间,模型没有告知边界框注释。
我们使用现成的预训练的VGG-16[52]、AlexNet[33]和GoogleNet[54](从Caffe[27] Zoo获得)来评估Grad-CAM的定位。在进行ILSVRC-15评估后,我们报告了表1中val集的top-1和top-5定位 errors。Grad-CAM定位errors明显优于c-MWP[58]和Simonyan等人[51]的定位errors,后者使用grab-cut方法将图像空间梯度后处理为热图。VGG-16的Grad-CAM也比CAM[59]取得了更好的top-1定位error,CAM需要改变模型架构,需要重新训练,从而得到更差的分类错误(比top-1差2.98%),而Grad-CAM并不会降低分类性能。

4.2 Weakly-supervised Segmentation
语义分割涉及到为图像中的每个像素分配一个对象类(或背景类)的任务。这是一项具有挑战性的任务,需要昂贵的像素级注释。弱监督分割的任务是只使用图像级注释对目标进行分割,从图像分类数据集中可以相对便宜地获得图像级注释。在最近的工作中,Kolesnikov等人[32]引入了一种新的损失函数用于训练弱监督图像分割模型。他们的损失函数基于三个原则——1)使用弱定位线索作为种子,鼓励分割网络匹配这些线索, 2)基于哪些类可以出现在一个图像的信息,扩展目标种子到合适大小的区域,3)限制分割对象的边界,减轻在训练中不精确的边界的问题。他们表明,他们提出的损失函数,包括上述三个损失,导致了更好的分割结果。
但是,他们的算法对弱定位种子的选择比较敏感,没有弱定位种子,网络就无法正确地定位目标。在他们的工作中,他们使用了来自基于VGG-16网络的CAM映射,这些CAM映射用作对象种子,用于弱定位foreground类。在PASCAL VOC 2012分割任务中,我们用从标准VGG-16网络中获得的GRAD-CAM替换CAM映射,并获得了49.6分(与用CAM得到的44.6分相比)的Intersection over Union(IoU)。图4给出了一些定性结果。

4.3 Pointing Game
Zhang等[58]引入了Pointing Game 实验来评价不同可视化方法在场景中定位目标物体的判别性。他们的评估协议首先用ground truth值对象标签提示每一种可视化技术,并在生成的热图上提取出最大激活点。然后,它评估该点是否位于目标对象类别的一个注释实例中,从而将其视为命中或未命中。
然后使用![]() 计算定位准确度。然而,这一评价仅衡量可视化技术的精度。我们修改了协议,想让其也能测量召回——我们计算来自CNN分类器(We use GoogLeNet finetuned on COCO, as provided by [58])top-5类预测的定位maps,然后使用Pointing Game设置去评估他们,其中设置使用一个额外的选项,即如果map上的最大激活点低于一个阈值,则拒绝来自该模型的任何top-5预测结果, 即如果可视化正确拒绝了不在ground truth类别中的预测,则将其认为击中了目标(hit)。我们发现,Grad-CAM比c-MWP[58]表现显著(70.58% vs 60.30%)。比较c-MWP[58]和Grad-CAM的定性例子见第D5节。
计算定位准确度。然而,这一评价仅衡量可视化技术的精度。我们修改了协议,想让其也能测量召回——我们计算来自CNN分类器(We use GoogLeNet finetuned on COCO, as provided by [58])top-5类预测的定位maps,然后使用Pointing Game设置去评估他们,其中设置使用一个额外的选项,即如果map上的最大激活点低于一个阈值,则拒绝来自该模型的任何top-5预测结果, 即如果可视化正确拒绝了不在ground truth类别中的预测,则将其认为击中了目标(hit)。我们发现,Grad-CAM比c-MWP[58]表现显著(70.58% vs 60.30%)。比较c-MWP[58]和Grad-CAM的定性例子见第D5节。
5 Evaluating Visualizations
在本节中,我们将描述我们所进行的人类研究和实验,以理解我们的模型预测方法的可解释性和可靠性之间的权衡。我们的第一个人类研究评估了我们的方法的主要前提- 即Grad-CAM可视化是否比以前的技术更有判别能力?在确定了这一点之后,我们转向理解它是否能够引导终端用户适当地信任可视化的模型。在这些实验中,我们比较了在PASCAL VOC 2007训练集上微调,验证集上可视化验证的VGG-16和AlexNet网络。
5.1 Evaluating Class Discrimination
为了衡量Grad-VAM是否有助于区分类,我们从PASCAL VOC 2007 val集中选择图像,图像恰好包含两个注释的类别,并为每个类别创建可视化。对于VGG-16和AlexNet CNNs,我们使用四种技术获得特定类别的可视化:Deconvolution, Guided Backpropagation, and Grad-CAM versions of each of these methods(Deconvolution Grad-CAM and Guided Grad-CAM)。我们在Amazon Mechanical Turk(AMT)上向43个人展示了这些可视化图像,并问他们“图中描述了两个物体类别中的哪一个?”(如图5所示)。

直观地说,一个好的预测解释是能够为感兴趣的类产生有区别的可视化。实验对90幅图像类别对使用了4种可视化方法(即得到360种可视化结果);对每幅图像采集9个评级,根据ground truth进行评估并求均值,得到准确度如表2所示。在查看Guided Grad-CAM时,人类受试者正确识别可视化类别的情况为61.23%(Guided Backpropagation为44.44%);因此,Grad-CAM可以提高16.79%的性能。同样地,我们还发现Grad-CAM使得Deconvolution的类别区分性更强(由53.33%变为60.37%)。在所有的方法中,Guided Grad-CAM效果最好。有趣的是,我们的结果表明,尽管Guided Backpropagation更美观,Deconvolution比Guided Backpropagation具有更强的分类区分能力(53.33% vs 44.44%)。据我们所知,我们的评估首先量化了这种微妙的差异。

5.2 Evaluating Trust
给出两种预测解释,我们评估哪一种更可信。我们使用AlexNet和vgg16来比较Guided Backpropagation和Guided Grad-CAM,注意到vgg16被认为比AlexNet更可靠,其在PASCAL分类上的mAP精度为79.09 (vs. 69.20)。为了区分可视化的有效性和被可视化的模型的准确性,我们只考虑那些两个模型都作为与ground truth相同预测的实例。分别为VGG-16和AlexNet各给定一个可视化结果,和对应的预测对象类别,54 AMT工人被要求比较模型之间的可靠性,评价标准为:clearly more/less reliable (+/-2), slightly more/less reliable (+/-1), and equally reliable (0)。这个页面在图5所示。为了消除任何偏差,vgg16和AlexNet都被分配为“model-1”,概率近似相等。值得注意的是,从表2中可以看出,我们发现,尽管两种模型做出了相同的预测,但人类受试者能够简单地从预测解释中识别出更准确的分类器(即VGG-16比AlexNet好)。在Guided Backpropagation中,人们给VGG-16打的平均分数是1.00,这意味着它比AlexNet稍微可靠一些,而引导的Guided Grad-CAM获得了更高的分数1.27,这说明了VGG-16显然更可靠。因此,仅仅是基于个人的预测解释,我们的可视化就可以帮助用户信任一个泛化更好的模型,。
5.3 Faithfulness vs. Interpretability
可视化对模型的可靠性是指它能够准确地解释模型学到的功能。自然地,在可视化的可解释性和可靠性之间存在着一种权衡——一个更可靠的可视化通常更难以解释,反之亦然。事实上,有人可能会说,一个完全可靠的解释是对模型的完整描述,在深度模型的情况下,这是不可解释的/不容易可视化的。在前面的章节中,我们已经验证了可视化是可以合理地解释的。我们现在评估他们对潜在模型的可靠性。一种期望是我们的解释应该是局部准确的,即在输入数据点附近,我们的解释应该忠实于模型[47]。
为了进行比较,我们需要一个具有高局部可信度的参考解释。对于这样的可视化,一个明显的选择是图像遮挡[57],当输入图像的patch被遮盖时,我们测量CNN评分的差异。有趣的是,那些改变CNN分数的patches,也是那些Grad-CAM和Guided Grad-CAM赋于高强度的patches, 在PASCAL 2007 val集的2510张图像上达到0.254和0.261的rank correlation (而Guided Backpropagation, c-MWP and CAM分别是0.168、0.220和0.208)。这表明与之前的方法相比,Grad-CAM更忠实于原模型。通过定位实验和人类研究,我们发现Grad-CAM可视化更具有可解释性,并且通过与遮挡映射的相关性,我们发现Grad-CAM更忠实于模型。
6 Diagnosing image classification CNNs with Grad-CAM
在本节中,我们将在imagenet上预训练的vgg16的背景下,进一步演示Grad-CAM在分析图像分类CNNs的失效模式、理解对抗噪声的影响、识别和消除数据集中的偏差方面的使用。
6.1 Analyzing failure modes for VGG-16
为了了解网络正在犯什么错误,我们首先得到一个网络(vgg16)未能正确分类的示例列表。对于这些分类错误的例子,我们使用Guided Grad-CAM来可视化正确的和预测的类。如图6所示,一些错误是由于ImageNet分类中固有的歧义造成的。我们还可以看到,似乎不合理的预测有合理的解释,这也是在HOGgles[56]中所做的观察。与其他方法相比,Guided Grad-CAM可视化的一个主要优势是,由于它的高分辨率和区分类别的能力,它很容易实现这些分析。

6.2 Effect of adversarial noise on VGG-16
Goodfellow等人[22]证明了当前深度网络对对抗示例的脆弱性,即对输入图像进行微小的、不可察觉的扰动,从而使网络以高置信度对其进行误分类。我们为imagenet预训练过的VGG-16模型生成对抗图像,这样它将高概率(> 0.9999)分配给图像中不存在的类别,而低概率分配给已存在的类别。然后我们为当前的类别计算Grad-CAM可视化。如图7所示,尽管网络确定没有这些类别(“tiger cat”和“boxer”),但Grad-CAM可视化可以正确地将它们定位。这表明,Grad-CAM对于对抗噪音是相当稳健的。

6.3 Identifying bias in dataset
在本节中,我们将演示Grad-CAM的另一个应用:识别和减少训练数据集中的偏差。在有偏差的数据集上训练的模型可能不能推广到现实世界的场景中,或者更糟,可能会使偏见和刻板印象(如性别、种族、年龄等)永久化。我们为“医生”和“护士”二分类任务微调了一个imagenet预训练的VGG-16模型。我们使用来自流行图像搜索引擎的前250幅相关图像(针对每个类)来构建训练和验证分割。测试集的性别分布在两个类中保持平衡。虽然经过训练的模型具有良好的验证精度,但其推广效果不佳(82%的测试精度)。
模型预测的Grad-CAM可视化显示(见图8中列的红色框区域)显示,模型已经学会通过观察人的脸/发型来区分护士和医生,从而学习了性别刻板印象。事实上,这种模式将几名女医生误认为护士,将男护士误认为医生。显然,这是有问题的。结果显示,图像搜索结果是有性别偏见的(78%的医生图像是男性,93%的护士图像是女性)。

通过这些从Grad-CAM可视化中获得的直觉,我们通过添加男护士和女医生的图像来减少训练集的偏差,同时保持每个类的图像数量不变。训练模型不仅推广了更好的测试精度(90%),而且关注了正确的区域(图8的最后一列)。这个实验展示了一个概念验证,Grad-CAM可以帮助检测和删除数据集自身的偏差,这是很重要的,不只是为了更好的泛化,还为了当社会上有着越来越多的算法决策后,能得到公平和道德的结果。
7 Textual Explanations with Grad-CAM
等式(1)给出了一种获取特定类卷积层中每个神经元的神经元重要性α的方法。文献[60,57]中提出了一些假设,认为神经元是概念“检测器”。神经元重要性的正值越高,表明该概念的存在会导致类分数的增加,而负值越高,则表明该概念的缺失会导致类分数的增加。
有了这种直觉,让我们研究一种产生文本解释的方法。在最近的工作中,Bau等人[4]提出了一种自动命名训练网络中任意卷积层神经元的方法。这些名称表示神经元在图像中寻找的概念。使用他们的方法。我们首先获得最后一个卷积层的神经元名称。接下来,我们基于他们特定类的重要性分数αk去对top-5个和bottom-5的神经元进行排序并得到它们。这些神经元的名称可以用作文本解释。
图9展示了在Places365数据集上训练的图像分类模型(VGG-16)的一些可视化和文本解释示例[61]。在(a)中,由(1)计算的正重要神经元寻找直观的概念,如图书和书架,这些概念表明了类“书店”。同样要注意的是,负重要的神经元会寻找一些不会出现在“书店”图像中的概念,比如天空、道路、水和汽车。在(b)中,为了预测“瀑布”,视觉和文字解释都强调了“水”和“分层”,这是对“瀑布”图像的描述。(e)是由于分类错误导致的错误案例,因为网络在没有绳索的情况下预测了“绳桥”,但重要的概念仍然(如水和桥)指示了预测的类别。在(f)中,虽然Grad-CAM正确指示着门和楼梯去预测"电梯门",但是检测门的神经元没有通过0.05的IoU阈值(选择为了抑制神经元名称的噪声),因此不属于文本的解释。更多定性的例子可以在Sec .F.中找到。

8 Grad-CAM for Image Captioning and VQA
最后,我们将Grad-CAM应用于视觉和语言任务,如图像字幕[7,29,55]和视觉问答(VQA)[3,20,42,46]。我们发现,与基线可视化方法相比,Grad-CAM可以为这些任务提供可解释的可视化解释,而基线可视化方法在预测变化时不会发生显著变化。注意,现有的可视化技术不是类可区分的(Guided Backpropagation, Deconvolution),就是不能用于这些任务/架构,或者两者都是(CAM、c-MWP)。
8.1 Image Captioning
在本节中,我们使用Grad-CAM可视化图像字幕模型的空间支持。我们在公开可用的neuraltalk2实现[31]上构建了Grad-CAM,它使用了一个用于图像的经过优化的vgg16 CNN和一个基于LSTM的语言模型。注意,这个模型没有明确的注意力机制。给定一个标题,我们计算它的log概率关于在CNN的最后一个卷积层(VGG-16的conv5_3)的unit的梯度,并生成第3节中所述的梯度Grad-CAM可视化结果哦。参见图10a。在第一个例子中,尽管风筝和人的尺寸相对较小,但对于生成的标题,Grad-CAM maps定位了每一个出现风筝和人。在下一个例子中,Grad-CAM正确地突出了披萨和男人,但忽略了旁边的女人,因为标题中没有提到“女人”。更多的例子在Sec.C。
Comparison to dense captioning. Johnson等人[29]最近引入了Dense Captioning(DenseCap)任务,该任务要求系统对给定图像中的突出区域进行联合定位和字幕标注。他们的模型由一个全卷积的定位网络(Fully Convolutional Localization Network,FCLN)和一个基于LSTM的语言模型组成,FCLN为感兴趣的区域生成边界框,而LSTM则生成相关的字幕,所有这些都是在一次前向传递中完成的。使用DenseCap,我们为每张图像生成5个特定区域的标题,并带有相关的ground truth边界框。一个全图字幕模型(neuraltalk2)的Grad-CAM需要定位生成区域字幕的边界框,如图10b所示。我们通过计算框内和框外的平均激活率来量化这一点。比率越高越好,因为它们表明对标题所属区域的关注程度越高。均匀高亮整幅图像的基线比率为1.0,而Grad-CAM达到3.27±0.18。增加高分辨率细节后,基线改善为2.32±0.08(Guided Backpropagation),最佳定位为6.38±0.99(Guided Grad-CAM)。因此,Grad-CAM能够对DenseCap模型描述的图像区域进行定位,尽管整体字幕模型从未接受过边界框标注的训练。

8.1.1 Grad-CAM for individual words of caption
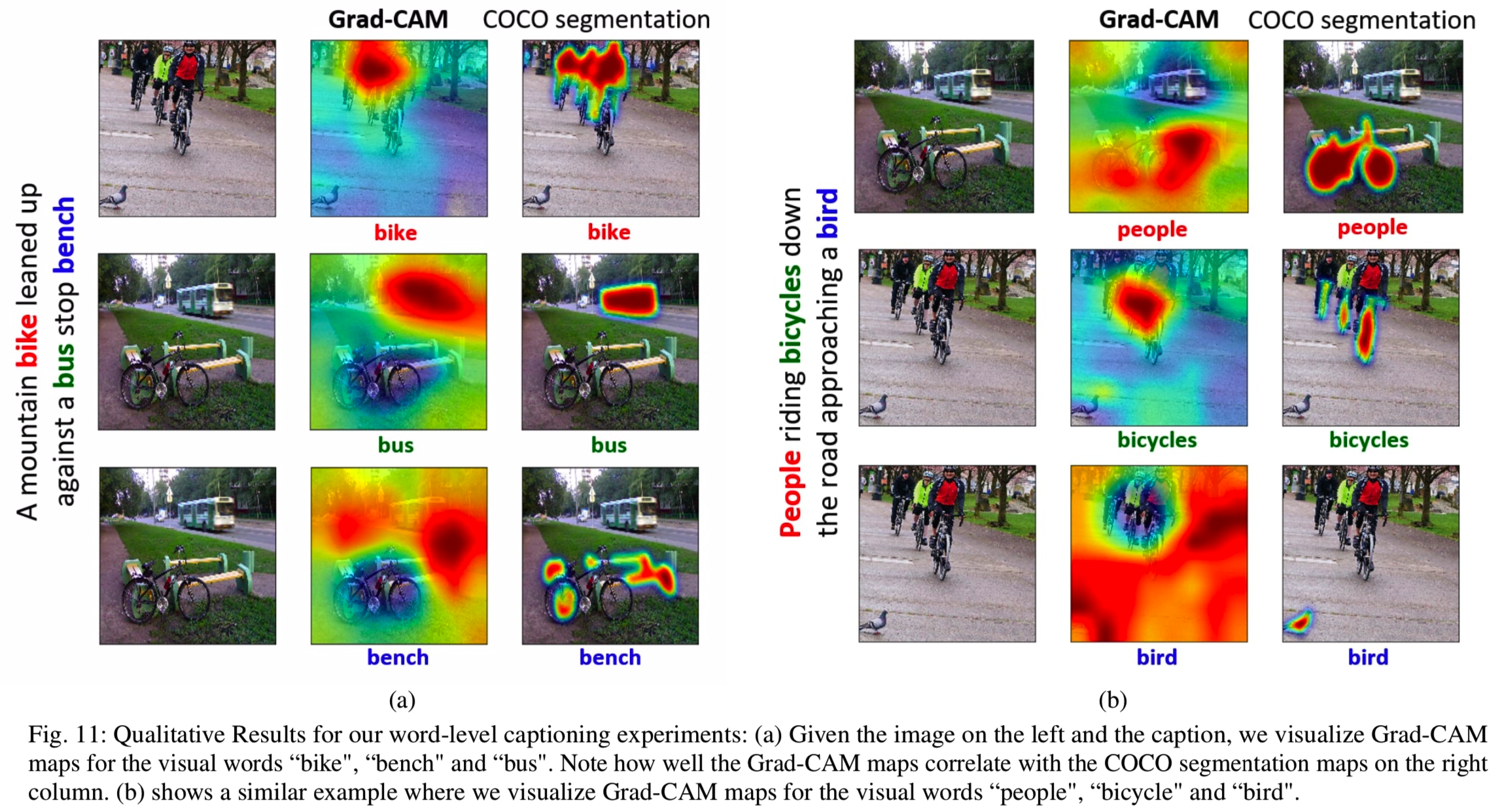
在我们的实验中,我们使用了在MSCOCO上预训练的Show and Tell模型[55],而没有通过从Inception[54]架构获得的视觉表示进行微调。为了得到ground truth字幕中单个单词的Grad-CAM map,我们在相应的时间步长对每个视觉单词进行one-hot编码,并利用等式(1)计算神经元重要性分数,并使用等式(2)结合卷积特征maps。
Comparison to Human Attention 我们手动创建了一个对象类别到单词的映射,它将对象类别(如‘person’)映射到潜在的细粒度标签(如[" child ", " man", "woman",…])。我们将COCO字幕中存在的830个可视单词映射到80个COCO类。然后,我们使用80个类别的分词注释作为这个匹配词子集的human attention。
然后使用来自[58]的pointing evaluation。对于标题中的每个可视单词,我们生成Grad-CAM映射,然后提取最大激活点。然后,我们评估该点是否在对应COCO类别的人类注意力映射分割中,从而将其视为成功或失败。点准确度计算为![]() 。我们在来自COCO数据集的1000个随机采样图像中实现该实验,并获得了30.0%的准确率。一些定性样本可见图11。
。我们在来自COCO数据集的1000个随机采样图像中实现该实验,并获得了30.0%的准确率。一些定性样本可见图11。
8.2 Visual Question Answering
典型的VQA管道[3,20,42,46]包括一个用于处理图像的CNN和一个用于问题的RNN语言模型。图像和问题表示被融合来预测答案,通常采用1000-way分类(1000是答案空间的大小)。由于这是一个分类问题,我们选择一个答案(在(3)中的分数yc)并使用它的分数来计算图像上的Grad-CAM可视化来解释答案。尽管任务很复杂,包括视觉和文本组件,但图12中描述的解释(关于Lu等人[38]的VQA模型)令人惊讶地直观和信息丰富。我们通过关联遮挡映射来量化Grad-CAM的性能,如第5.3节所示。Grad-CAM的rank correlation(与遮挡映射)为0.60±0.038,而Guided Backpropagation的rank correlation为0.42±0.038,表明我们的Grad-CAM可视化具有更高的可信度。
Comparison to Human Attention. Das等人[9]为VQA数据集[3]的一个子集收集了人的注意力maps。人们为了回答一个视觉问题,而对该图像关注的部分对应的maps部分有很高的强度。利用[9]中的rank correlation评价协议,将[38]的VQA模型与[3]的1374个val问题图像(QI)对 上的人的注意力地maps与Grad-CAM可视化方法进行了比较。Grad-CAM与人的注意maps的相关系数为0.136,高于随机或偶然注意图(零相关)。这表明,尽管没有在真实的图文对上进行训练,即使是基于非注意的CNN + LSTM的VQA模型,在预测特定答案的区域定位方面也非常出色。
Visualizing ResNet-based VQA model with co-attention. Lu等人[39]使用200层ResNet[24]对图像进行编码,并共同学习了问题和图像的分层注意机制。图12b显示了该网络的Grad-CAM可视化结果。当我们可视化ResNet的更深层时,我们看到了大多数相邻层次的Grad-CAM只有小的变化,而在涉及维数减少的层次之间有着大变化。更多resnet的可视化可以在Sec.G中找到,就我们所知,我们是第一个可视化基于resnet模型的决策的人。

9 Conclusion
在这项工作中,我们提出了一种新的类可区分的定位技术-Gradient-weighted Class Activation Mapping (Grad-CAM)-通过产生可视化的解释使任何基于CNN的模型更加透明。此外,我们将Grad-CAM定位与现有的高分辨率可视化技术相结合,以获得两者的最佳效果—— 即高分辨率和类可区分的Guided Grad-CAM可视化方法。我们的可视化在两个方向上都优于现有的方法—— 即在可解释性和对原始模型的忠实性上。广泛的人类研究表明,我们的可视化可以更准确地区分类,更好地显示分类器的可信度,并帮助识别数据集中的偏差。此外,我们设计了一种通过Grad-CAM识别重要神经元的方法,并为模型决策提供了一种获取文本解释的方法。最后,我们展示了Grad-CAM在各种现成架构上的广泛适用性,如图像分类、图像字幕和可视化问题回答。我们认为,一个真正的人工智能系统不仅应该是智能的,还应该能够对其信念和行为进行推理,让人类信任和使用它。未来的工作包括解释深度网络在强化学习、自然语言处理和视频应用等领域做出的决策。
Appendix(只挑一部分)
1.说明在最后一个卷积层可视化效果比其他更早的层好。因为最后一层能更好地捕捉高级语义信息,并保持空间信息,而更早的层有着更小的接受域,且仅关注局部特征,见图3

2.说明使用Global Average pooling比使用Global Max pooling好
3.使用Guided-ReLU和Deconv-ReLU说明负梯度也携带了重要的信息
4.图19部分
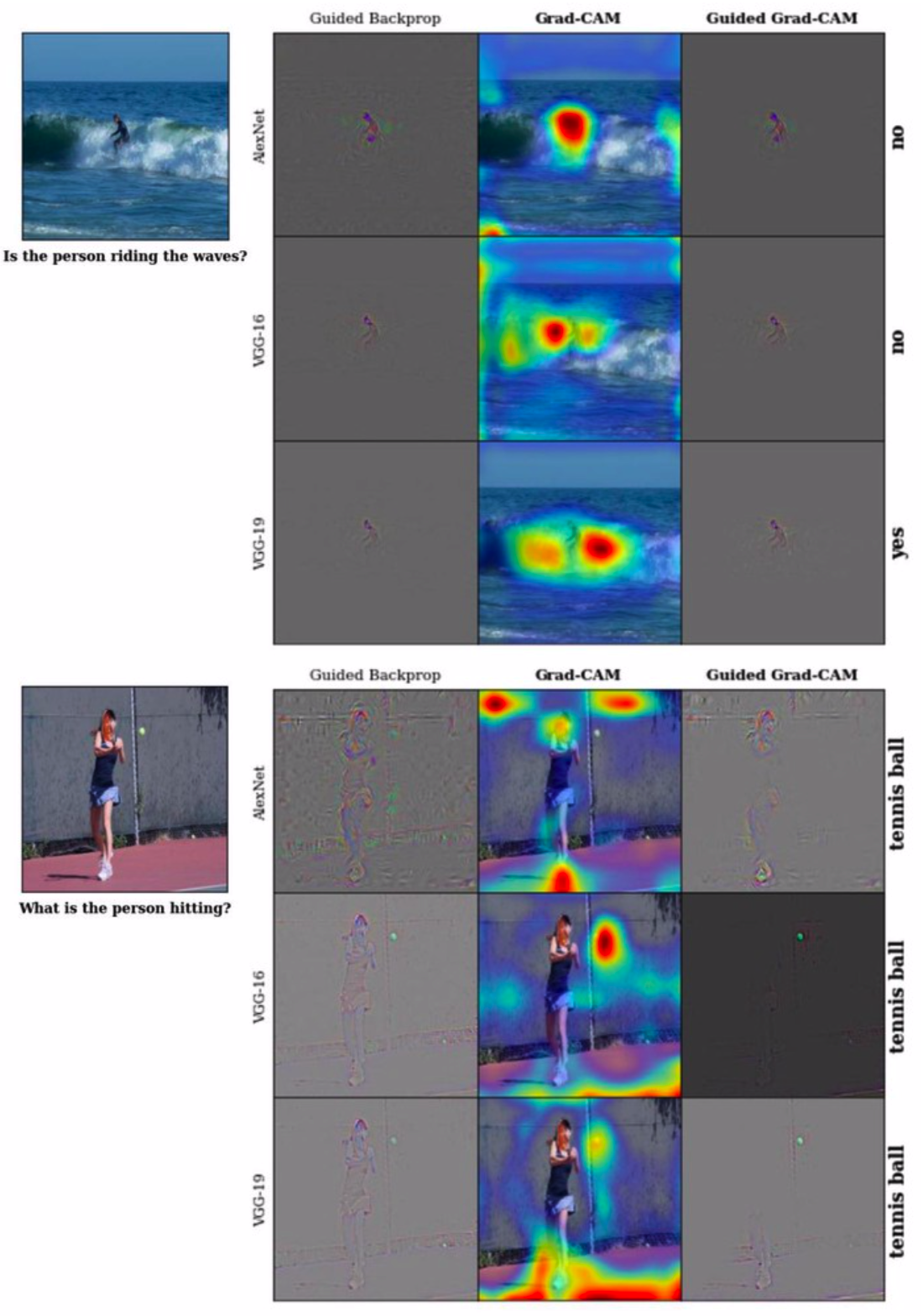
这是个视觉问答的结果,可见在回答问题“Is the person riding the waves?”时,AlexNet和VGG-16模型回答“No”(当他们集中关注与人而非海浪时)。另一方面,VGG-19回答“Yes”,但是它关注的区域是人附近的区域。对于另一个问题“What is the person hitting?”,AlexNet回答“Tennis ball”,但是它关注的是周围的环境,而不是球。从这些可视化结果,我们可以认为,这样的模型如果部署到现实场景中是十分冒险的,可信度比较低。