缓存流程
在讲这五个问题之前,首先我们回顾下正常的缓存的使用流程
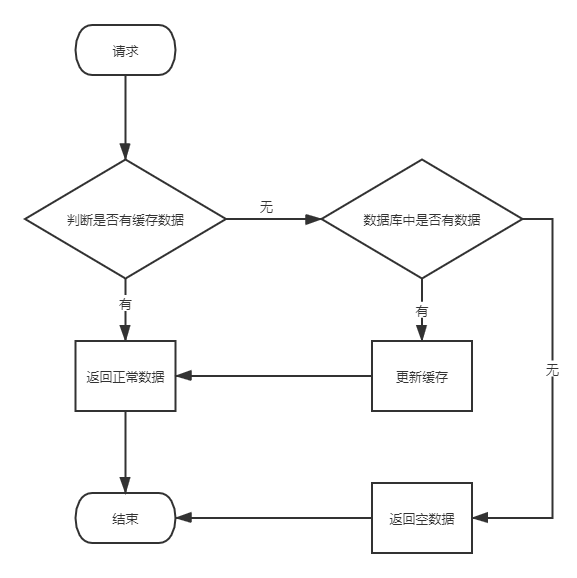
程序在处理请求时,会先从缓存中进行查询,如果缓存中没有对应的key,则会从数据库中查询,如果查询到结果,并将查询结果添加到缓存中去,反之不缓存。流程就不多解释了,基于这个我们展开下面的问题。
缓存穿透
产生原因
当查询一个一定不存在的key时,由于不能命中缓存,所以要查询数据库,但是这个key又不存在,所以查询不到结果,不会缓存。于是就有了利用这种一定不存在的key作为查询条件,对系统进行攻击,增加数据库压力,这种现象称为缓存穿透。
解决方法
- 布隆过滤
首先要规范key的命名,对不规范的key直接过滤掉,并对所有可能的key以hash形式存储到一个足够大的bitmap中,不存在的数据会被此bitmap拦截,以避免查询数据库。 - 缓存空对象
意思很简单,就是对返回数据为空的情况也进行缓存,并设置一个很短的过期时间,这样也能起缓解作用。但是这也会产生下面两个问题:- 缓存空对象意味着需要更多的存储空间,可再缩短缓存时间,过期自动剔除
- 导致缓存与数据库不一致,比如某个key:a查询时还没有数据,这时会缓存空值,但是其他某个流程已走完,数据已添加到了数据库中,这时访问依旧会返回空值,因为缓存还没过期,所以解决方法就是增删改时也进行缓存的刷新
缓存雪崩
产生原因
当大批量缓存集中在同一时间内失效(或者redis宕机),产生大量缓存穿透,此时又有请求并发袭来,查询压力瞬间都落在了数据库上,此时就产生了缓存雪崩。
解决方法
- 失效时间加随机值
给缓存失效时间加一个随机值,避免集体失效 - 实现redis高可用
通过对redis实现集群搭建来避免部分机器宕机导致redis不可用的情况 - 分布式锁或分布式队列
保证缓存单线程写,并在没有获取锁的线程中一直轮询缓存,直到超时
缓存击穿
产生原因
缓存击穿是指缓存中没有但是数据库中有的数据(通常是缓存到期),由于并发,未能从缓存读到数据,从而引起数据库鸭梨瞬间增大
解决方法
- 设置热门缓存数据永不过期
这里永不过期有两层意思:- 不设置过期时间或超长缓存时间即物理上不过期
- 在缓存对象上添加一个标识过期时间的属性,在获取数据后校验过期时间,如果已过期则异步去更新改缓存
这种方式可能会出现数据脏读(在缓存更新期间取到旧数据)的情况,视业务而定使用与否
- 分布式锁或分布式队列
保证缓存单线程写,并在没有获取锁的线程中一直轮询缓存,直到超时
缓存一致性
如果对数据有强一致性要求的,那就不要使用缓存了
缓存并发竞争
产生原因
多个子系统set同一个key,导致产生并发竞争
解决方法
- 对key没有顺序要求
使用分布式锁实现 - 对key有顺序要求
将key对应的值带上时间戳 - 异步队列
放入队列中,串行set就行