Recurrent Neural Network (RNN)
1、什么是RNN
2、LSTM
一、什么是LSTM
二、LSTM框架
3、RNN分析
RNN
1、什么是RNN
- RNN可以处理序列的信息(即前面的输入对后面是有关系的)
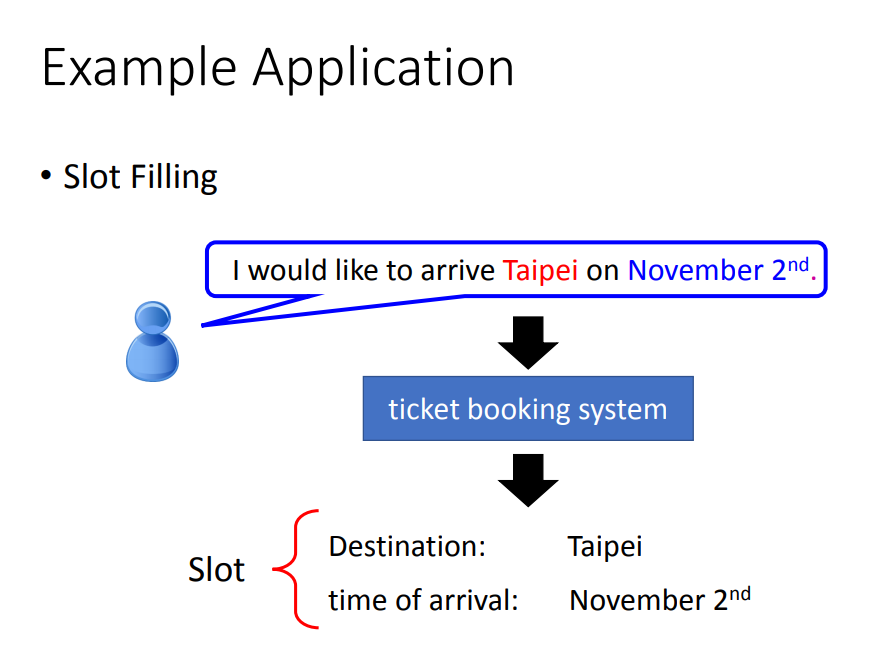
下面通过一个订票系统的例子去说明什么是RNN:
1)、目标:假设我们现在做这么一个事情,说下面一句话,系统会自动知道Taipei是目的地,November是时间
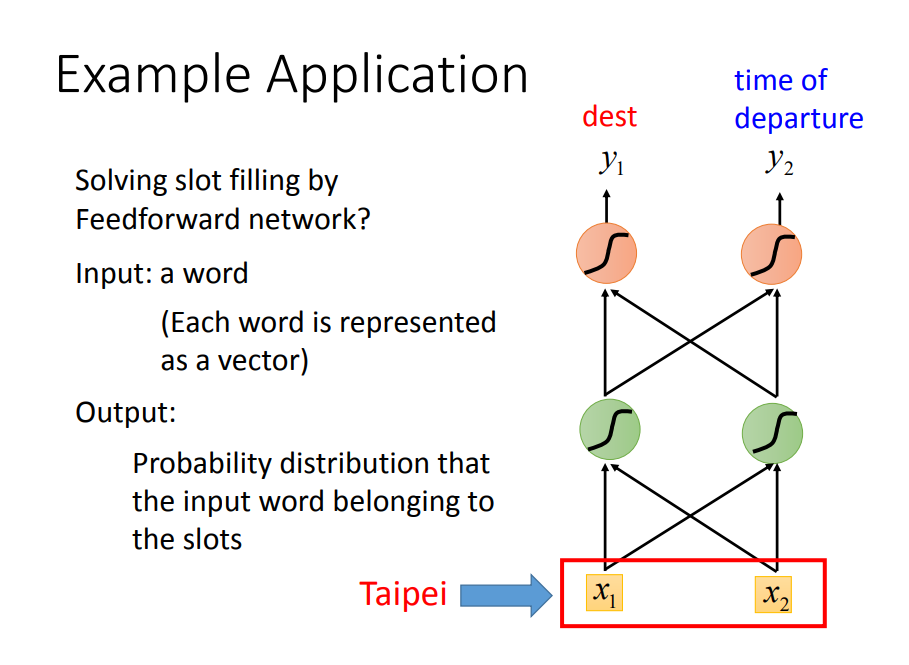
2)、如果没有把这句话当做一个序列,那么用前馈神经网络方法的话,这样是没有考虑到上下文的。
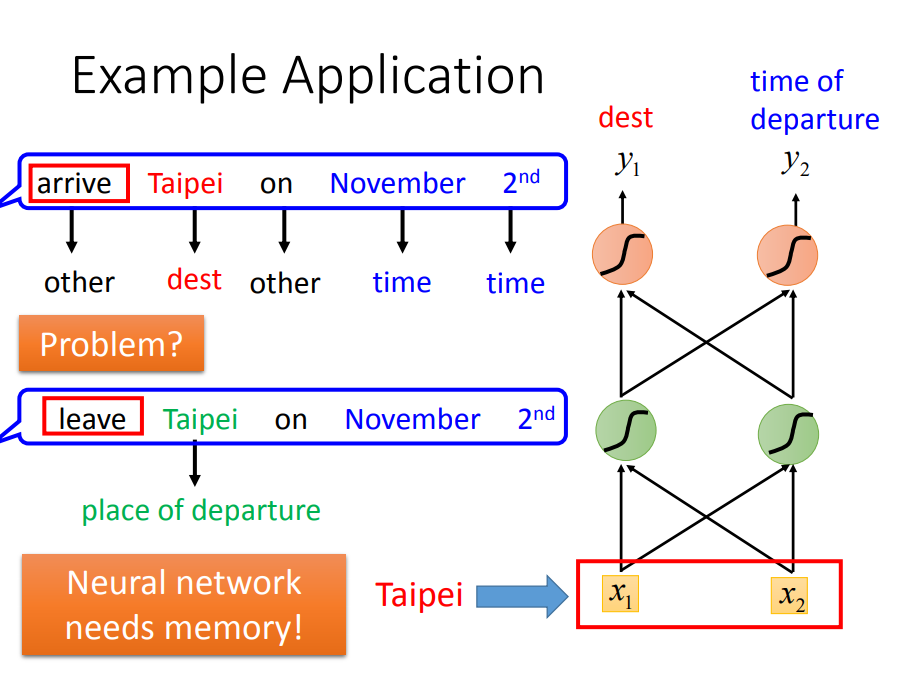
3)、因此要解决这个问题,模型需要有memory,这就引出了RNN

RNN具体是怎么做到记忆的呢
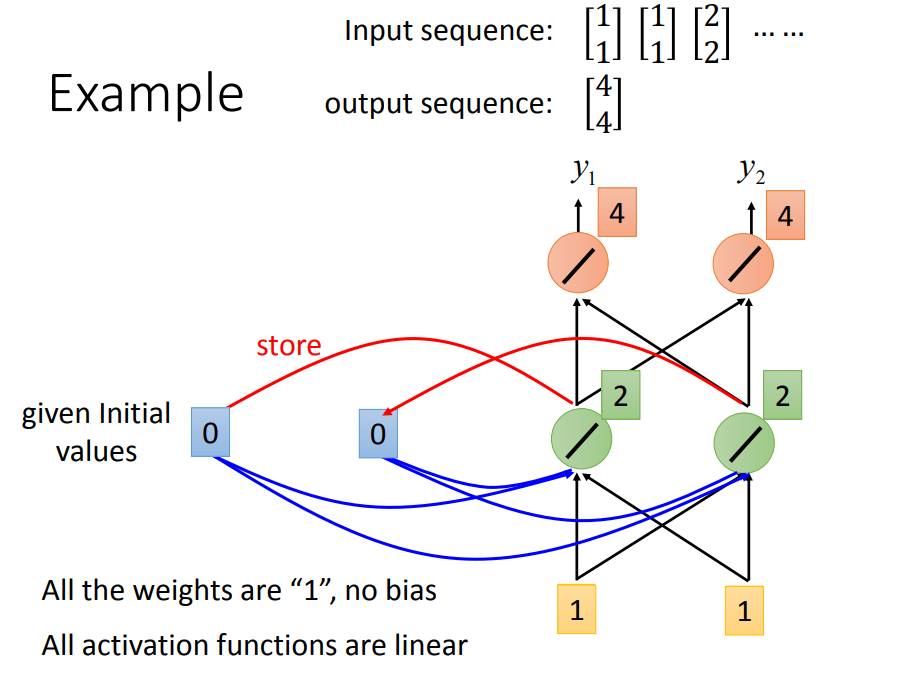
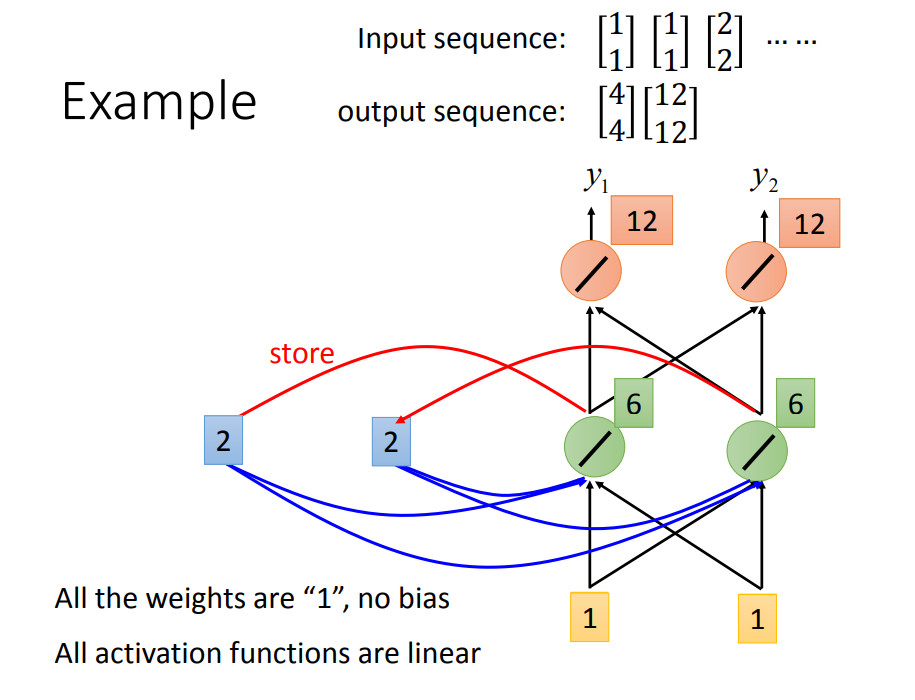
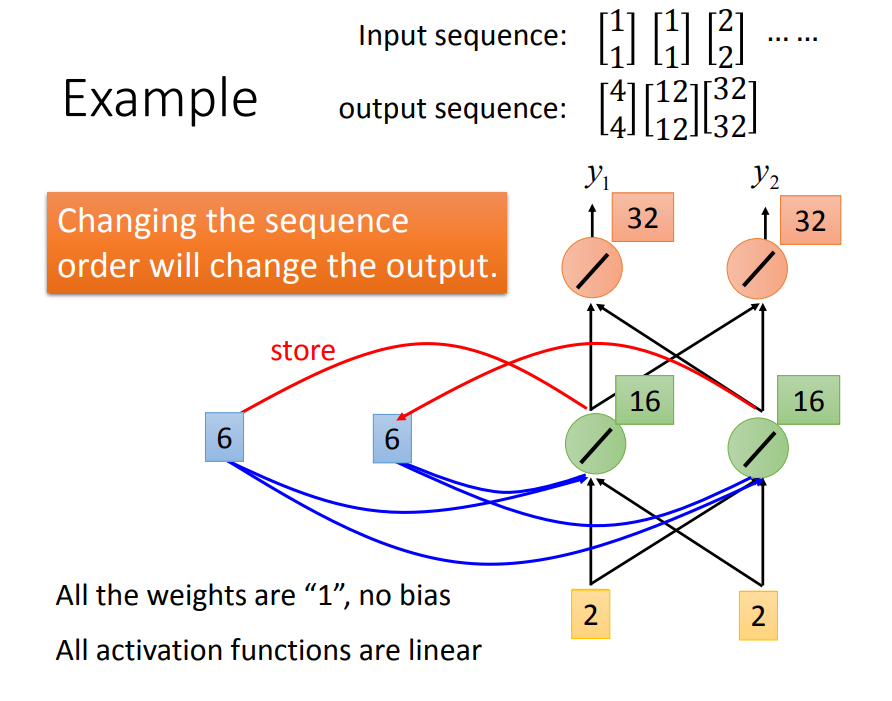
再看看RNN是如何解决Slot Filling的问题:
- 注意的是,下面不是三个神经网络,而是同一个神经网络
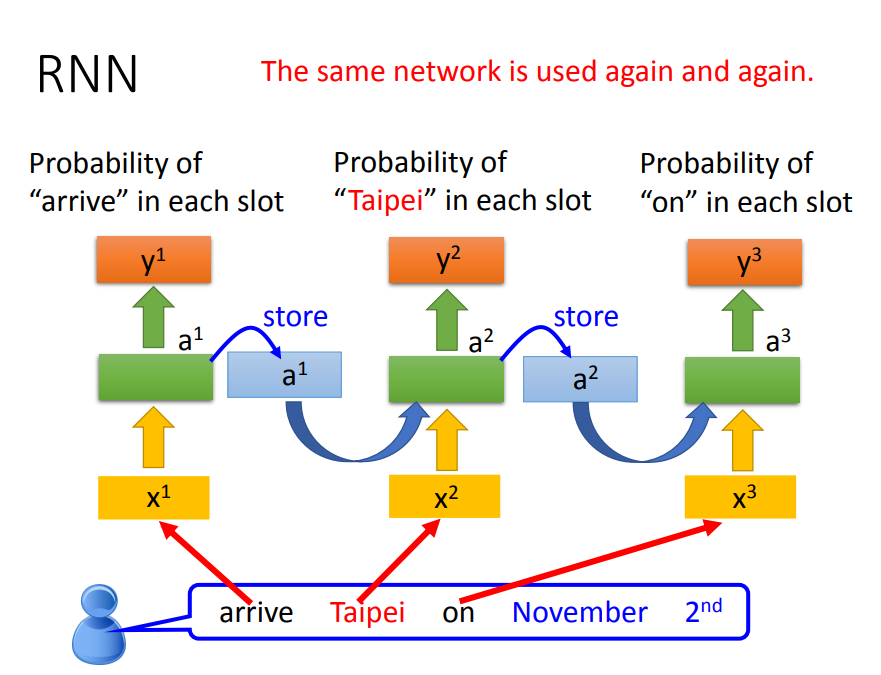
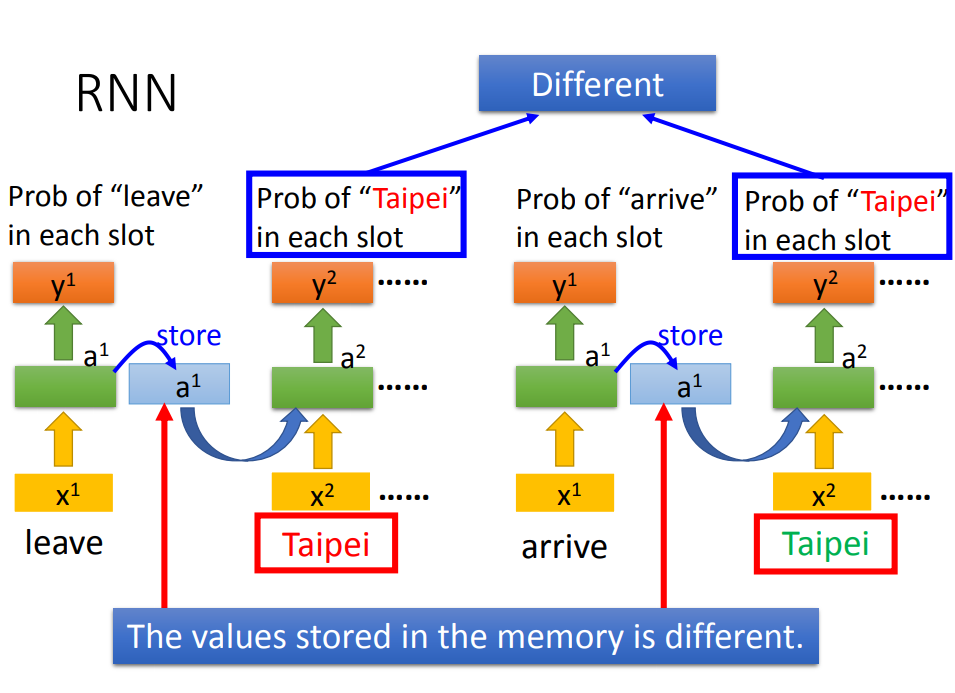
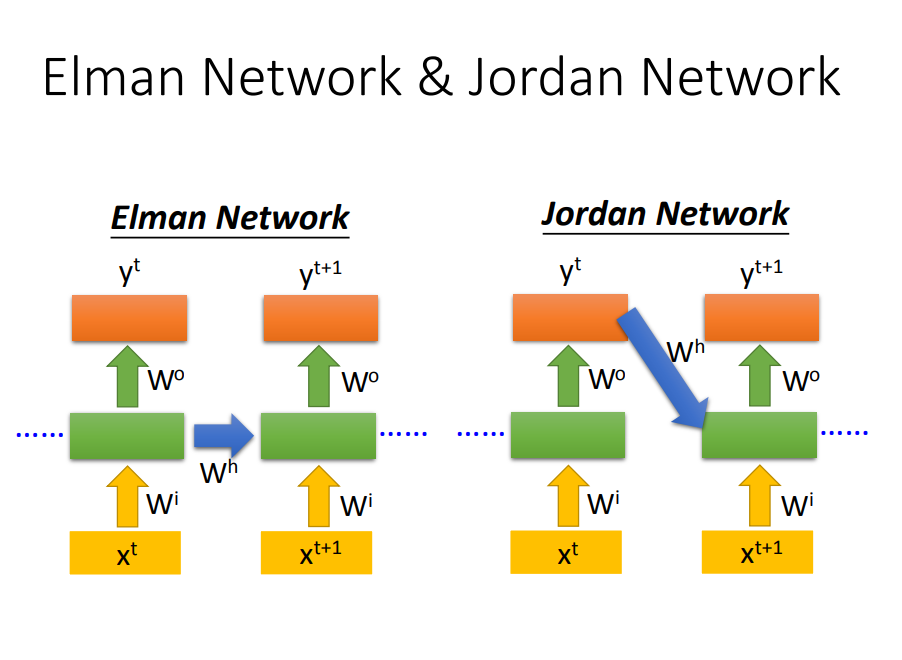
4)RNN种类
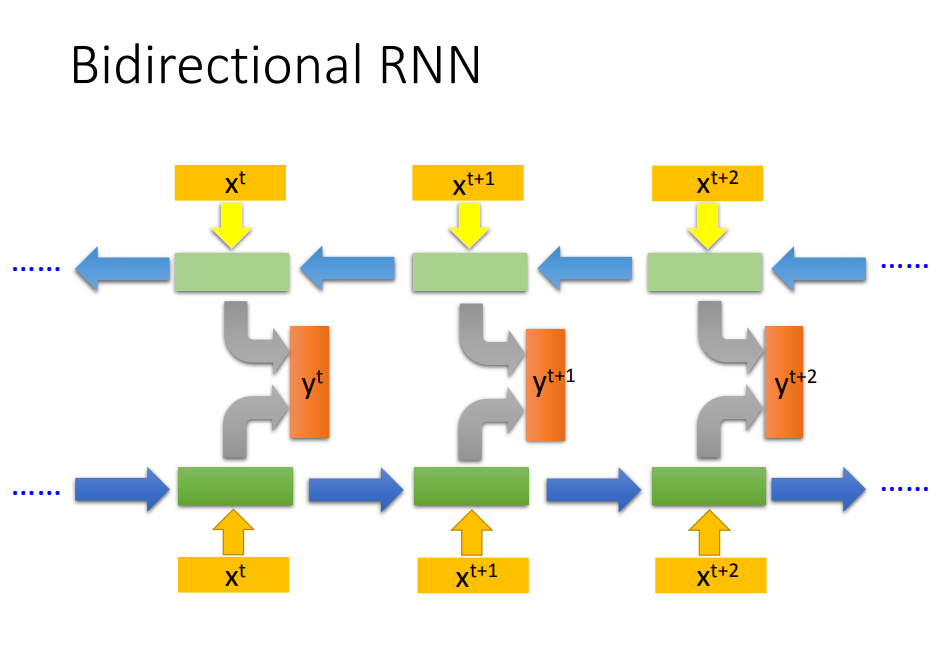
双向神经网络:在产生Y{t+1}的时候,你的network不只是看过xt到x{t+1}所有的input,它也看了从句尾到x{t+1}的input
2、LSTM
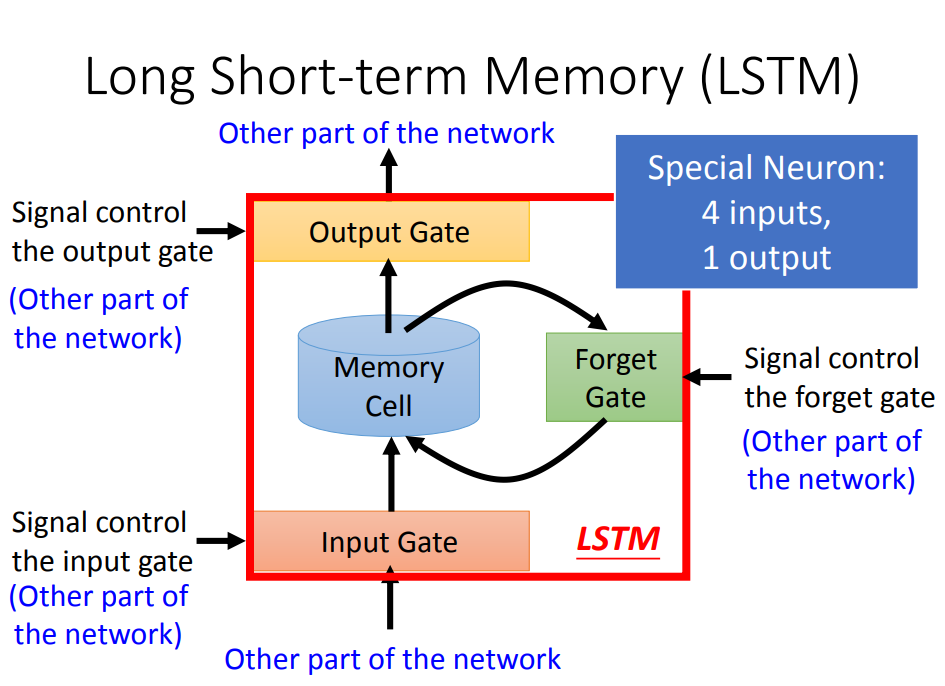
一、什么是LSTM
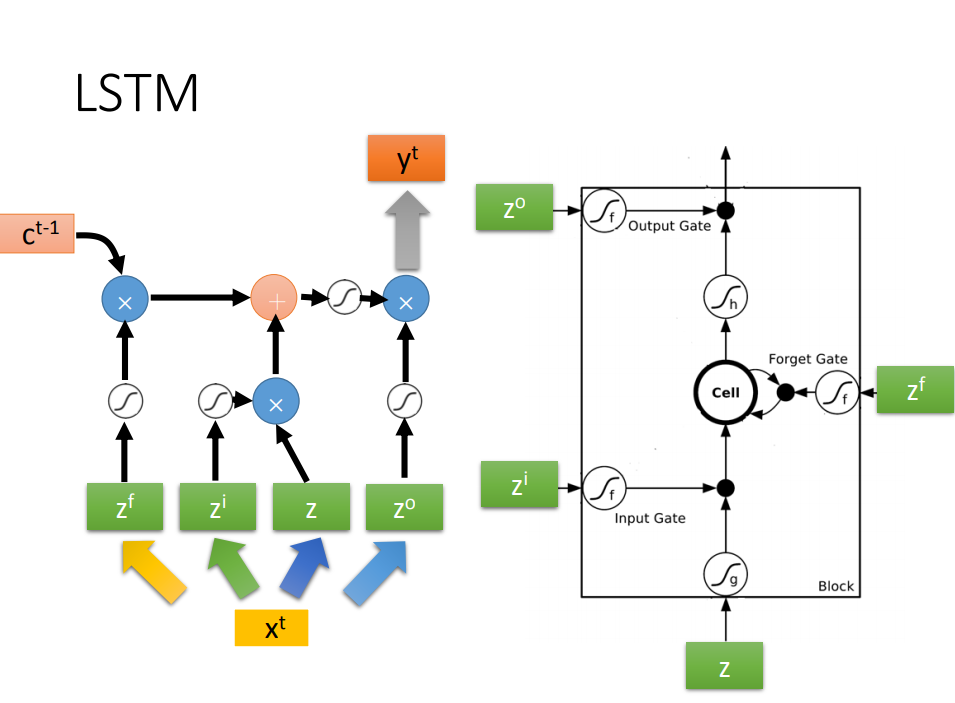
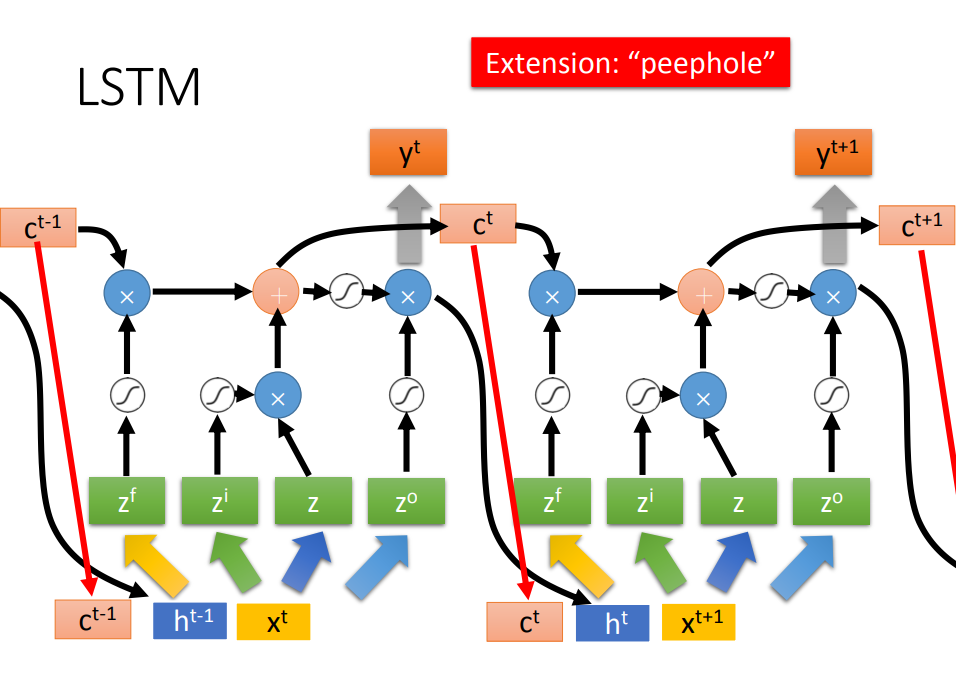
- 左图中,LSTM是四输入一输出,其中有三个gate,每个gate打开还是关闭,都是学出来的
- 右图中,Z,Zi,Z0都是数值输入,三个gate使用的激活函数是sigmoid,于是把各个输入输出就可以用式子表示出来

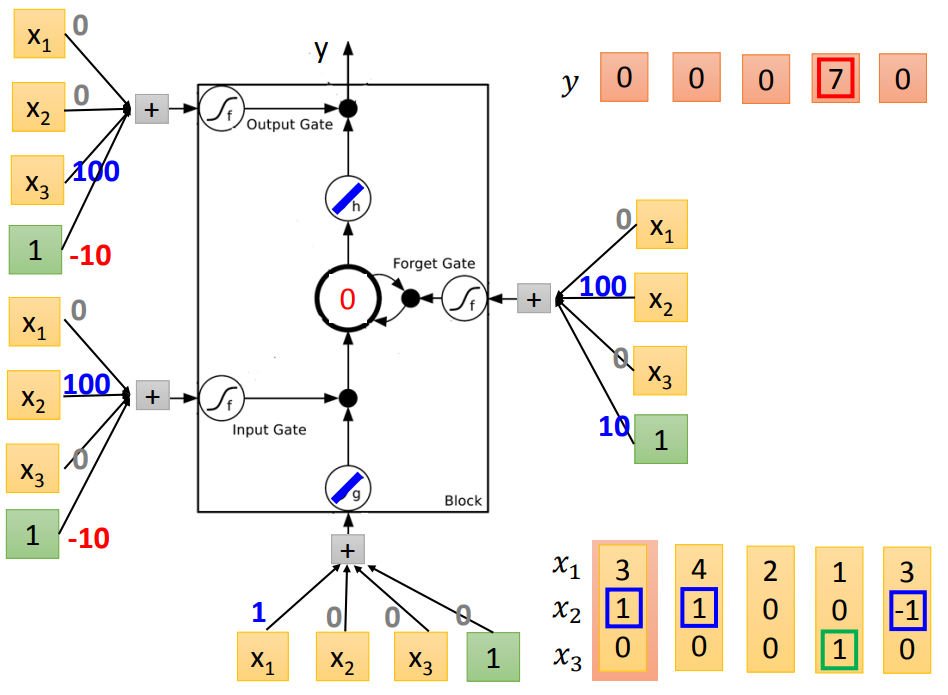
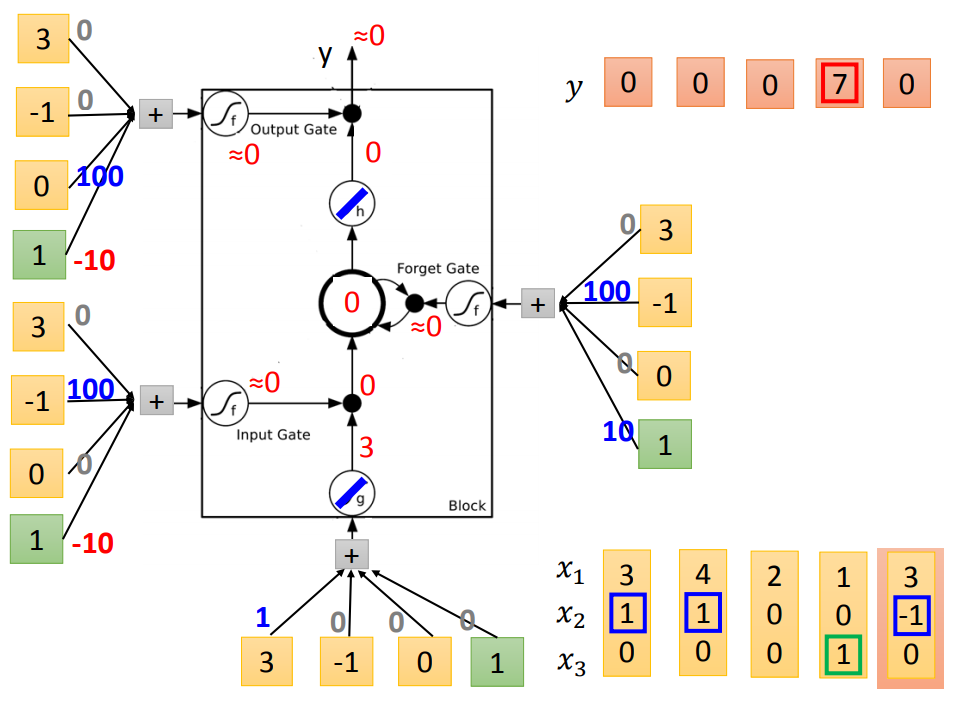
举个栗子说明:
输入:三维vector[x1,x2,x3]
输出:一维vector y
下图从左到右表示更新过程,蓝色代表memory

代入LSTM中训练:(假设要训练的bias-10和weight100都已知)
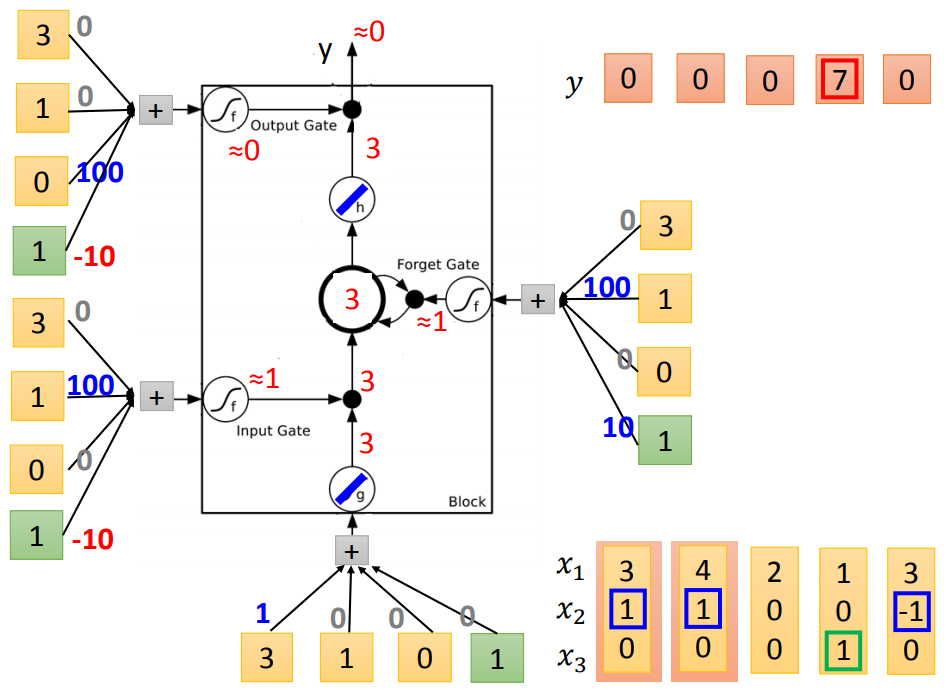
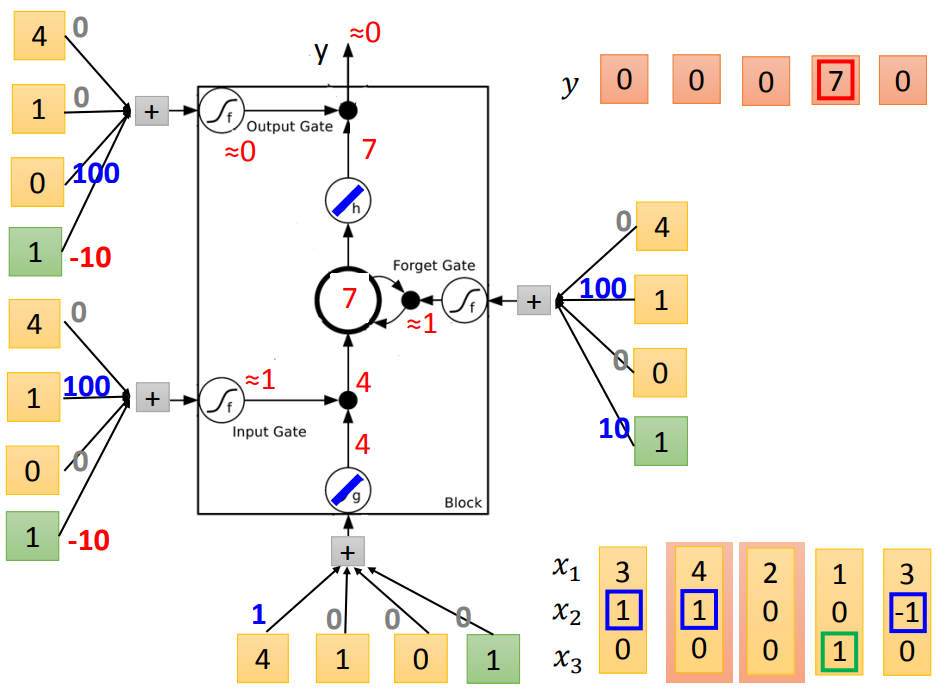
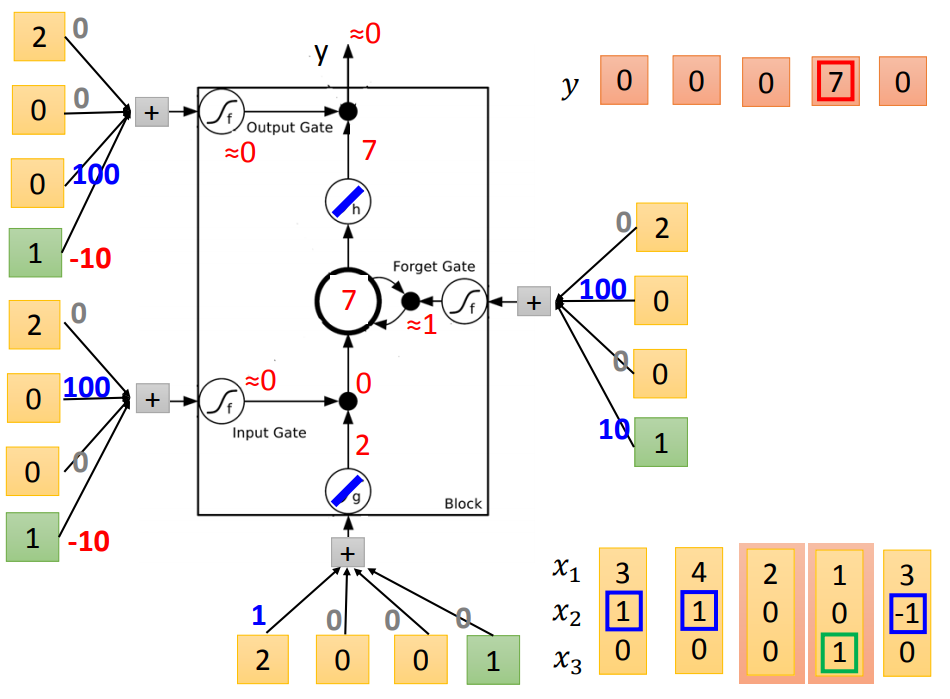
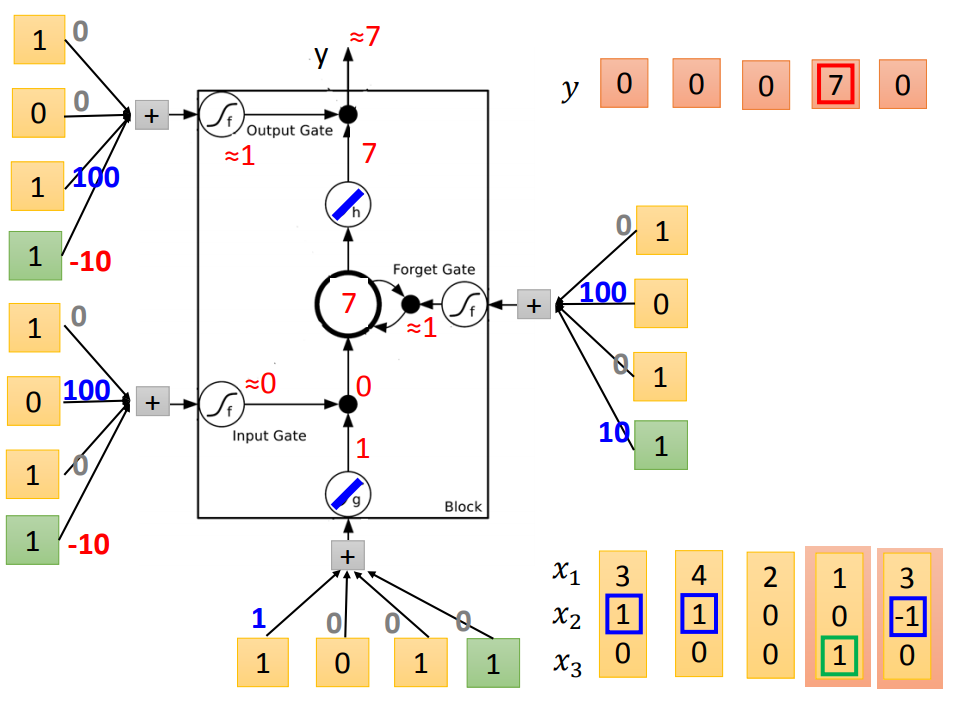
二、LSTM框架
- LSTM的参数是普通神经网络的四倍

进一步揭开LSTM面纱
- 输入Xt先经过线性转化为4个vector组成的Z
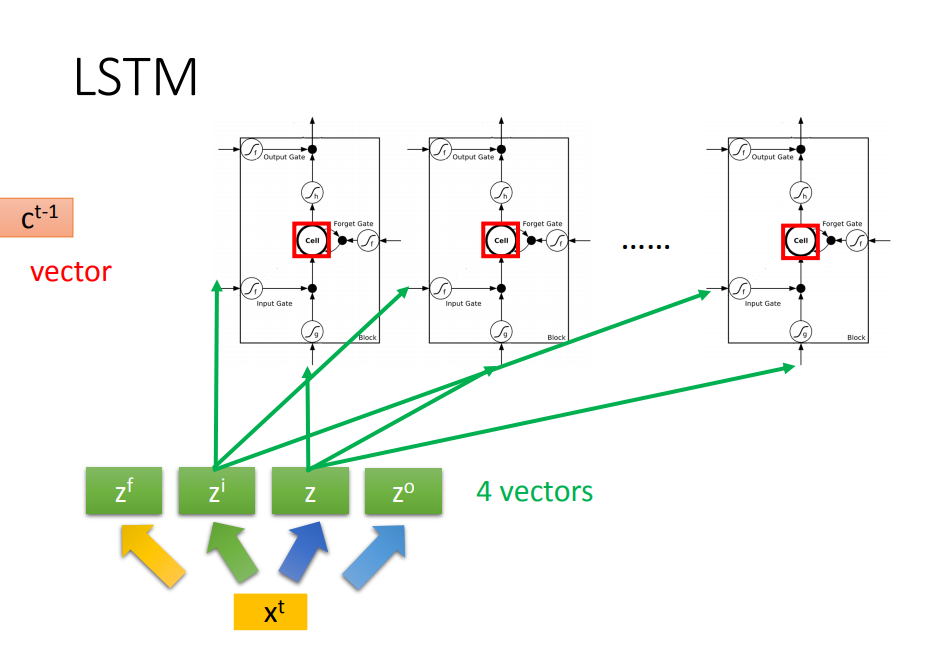
多层的LSTM感受一下
- C是memory的vector
- h是上一个LSTM神经元隐层的输出

3、RNN分析
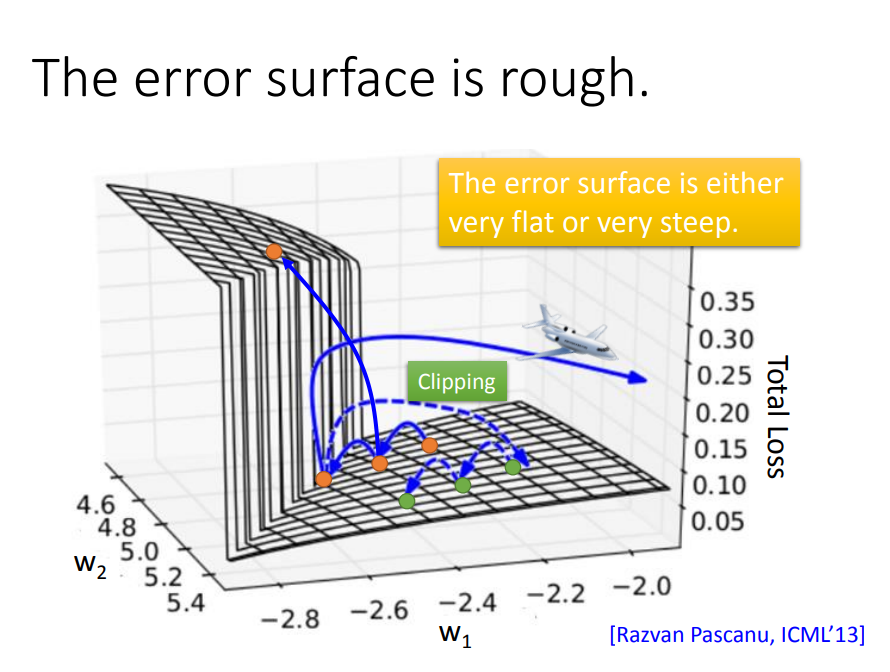
一、RNN会出现“悬崖”(梯度消失或爆炸)问题
Total Loss对于参数的偏导的曲面是很不平整的,有很多断崖,因此会出现好几种情况:
- 第一种:1→2→3跳跃到悬崖上
- 第二种:1→2→4踩到墙脚
- 第三种:1→2→4→5加大学习率后直接飞出去
用clipping方法(当gradient大于某一个threshold的时候,不要让它超过那个threshold),当gradient大于15时,让gradient等于15结束
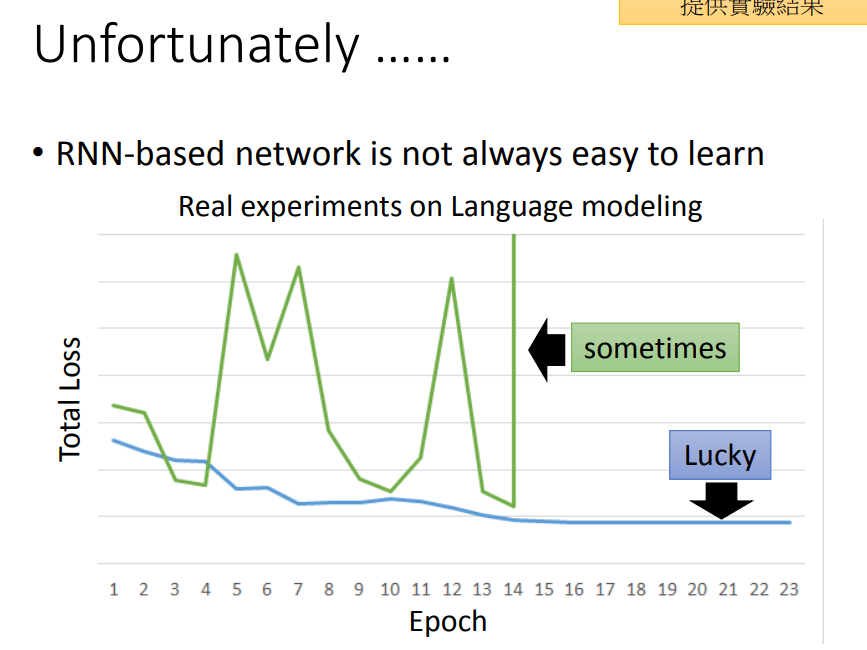
为什么RNN会有这样的特性?是不是因为sigmoid函数会造成梯度消失?换成ReLU会不会解决这个问题?
答案是:sigmoid函数不是造成不平整的原因,且ReLU在RNN上表现并不如sigmoid。所以activation function并不是这里的关键点。
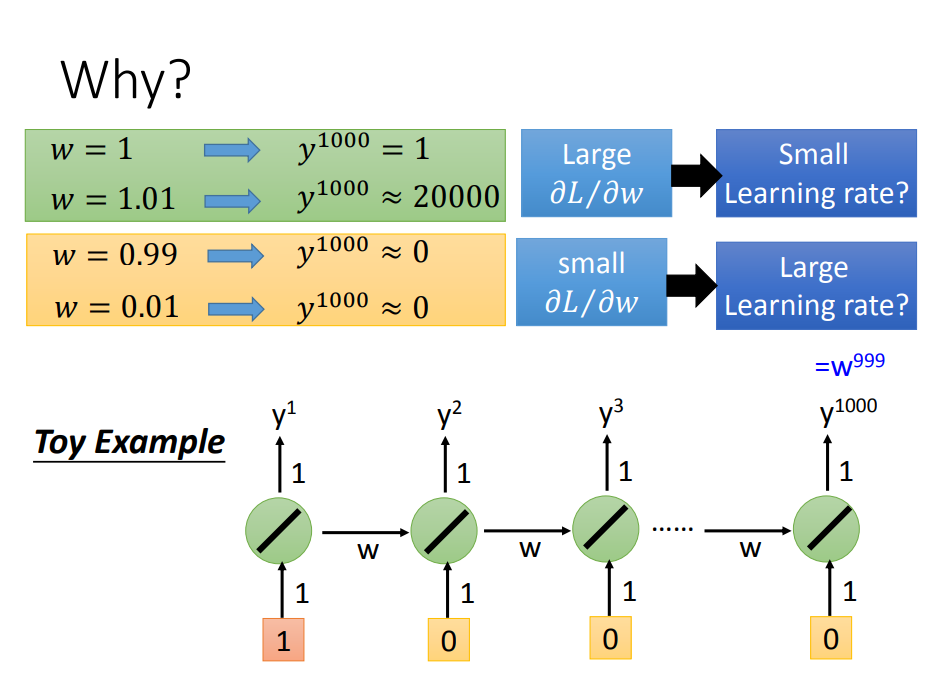
二、悬崖问题分析
现在w是我们要学习的参数,我们需要知道它的gradient,只要稍微改变w 的值,看看对output有多大的影响。
三、问题解决方案
面试题:LSTM为什么可以解决RNN的梯度消失问题?
LSTM和RNN在处理memory cell里面的值的方式不一样:
RNN每次都把新的值存到memory cell里面,旧的值被替换;
LSTM则用了input gate的计算结果与输入相乘后的值累加到memory cell里面。
思想:
- RNN每次都替换旧的值,旧的值没有办法对最后的值有所影响;
- LSTM则采用累加策略,旧的值的还在memory cell里面,也就意味旧的值还持续影响最后输出;
- 也就是说在LSTM里面,一旦对memory造成影响,那影响一直会被留着(除非forget gate要把memory的值洗掉),不然memory一旦有改变,只会把新的东西加进来,不会把原来的值洗掉,所以它不会有gradient vanishing的问题
其实LSTM的第一个版本其实就是为了解决gradient vanishing的问题,所以它是没有forget gate,forget gate是后来才加上去的。甚至,现在有个传言是:你在训练LSTM的时候,你要给forget gate特别大的bias,你要确保forget gate在多数的情况下都是开启的,只要少数的情况是关闭的
