一.了解模块
什么是模块:
模块就是一系列功能的结合体
1.导入模块的三种来源:
1.内置模块 (python解释器自带的模块)
2.第三方模块 (别人写好的)
3.自定义编写
2.模块的四种表现形式:
1. 使用python解释器编写好的py文件(py文件也可以称之为模块,一个py文件就是一个模块)
2. 被已编译为共享库或DLL的C或C++扩展(了解)
3. 把一些列模块组织到一起的文件(文件夹下有__init__.py文件,该文件夹称之为包)
4. 使用c编写好并连接到python解释器的内置模块
为什么用模块:
1.从文件级别管理组织程序
当程序比较庞大的时候,项目部可能只在一个py文件中,当多个文件中都需要使用相同的方法的时候,
可以将该方法写到公共的py文件中,其他文件就可以以模块的形式调用即可
2.提升开发效率(拿来主义)
我们也可以下载别人写好的模块导入到自己的项目中,可以极大的提升开发效率
如何使用模块:
1. import 模块名
2. form 模块名 import 变量名
一定要区分那个是执行文件,那个是被导入文件(******)
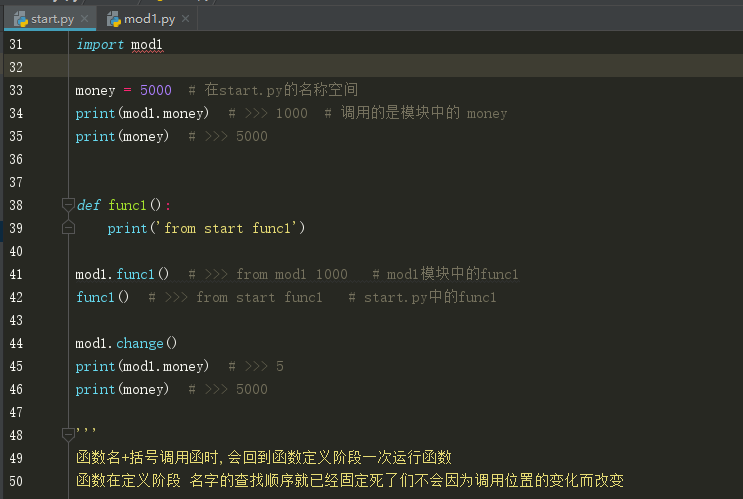
二.import 模块名
调用模块发生的事情:
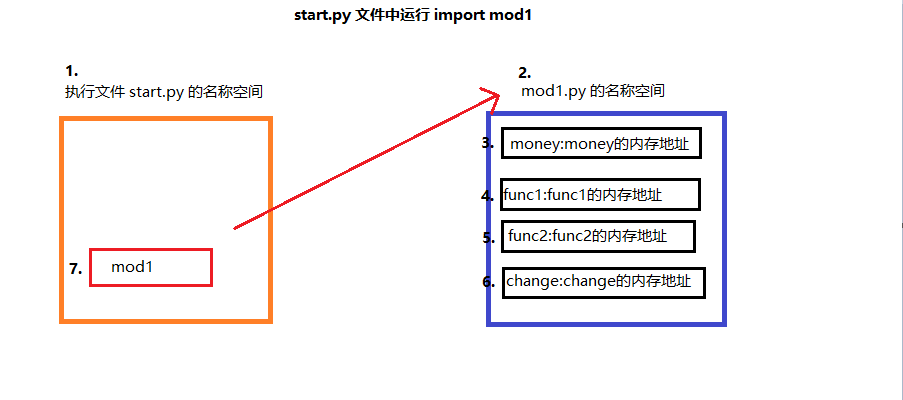
1.运行执行文件start.py,首先创建一个执行文件start.py的名称空间
2.运行import mod1 代码,导入mod1.py模块(首次)******
2.1.运行mod1.py文件
2.2.创建mod1.py的名称空间,将mod1.py文件中代码产生的名字与值存放到其中
2.3.在执行文件start.py的名称空间中产生一个指向mod1.py名称空间的名字(mod1)
注意:(*****)
多次重复导入相同模块,只会要用第一导入的成功
使用import导入模块,访问模块名称空间的名字的统一方式:模块名.名字
特点:
1.指名道姓的访问模块中的名字,永远不会与执行文件中的名字冲突
2.如果想访问模块中的名字也必须使用 模块名.名字 的方式
当要导入的几个模块有相同部分或者同属于一个模块,可以使用 import 模块1,模块2...的方式(不推荐使用)
当导入的几个模块没有联系的情况下,应该分多次导入:
import 模块1
import 模块2
import 模块3
ps :
1.通常导入的模块会写在文件的开头
2.当模块的名字比较复杂的情况下,可以给该模块取别名 如:import 模块 as 新名字
之后通过新名字调用模块中的名字即可
例:
# 文件 mod1.py
print('form in mod1.py')
money = 1000
def func1():
print('from mod1',money)
def func2():
print('form mod1 模块')
func1()
def change():
global money
money = 5
三.from 模块名(文件) import 名字
调用模块发生的事情:
1.运行执行文件start.py,首先创建一个执行文件start.py的名称空间
2.运行form mod1 import 名字 代码,导入mod1.py模块(首次)******
2.1.运行mod1.py文件
2.2.创建mod1.py的名称空间,将mod1.py文件中代码产生的名字与值存放到其中
2.3.直接拿到指向mod1.py文件中的某个值的名
注意:(*****)
多次重复导入相同模块,只会要用第一导入的成功
特点:
1.访问模块中的名字不需要加模块名前缀
2.在访问模块中的名字可能会与当前执行文件中的名字冲突
例:
#文件 mod2.py
print('form in mod2.py')
money = 1000
def func1():
print('from mod2',money)
def func2():
print('form mod2 模块')
func1()
def change():
global money
money = 5
# 对应特点四:
__all__ = ['money','func1']
# 特点一:
from mod2 import money,func1
print(money) # >>> 1000 # 能去到指定名字的值
print(func1) # <function func1 at 0x00000271A9FE1E18>
print(func2) # 导入模块时指定了名字 ,其他名字取不到
# 特点二:
money = 500
from mod2 import money
print(money) # >>> 1000
from mod2 import money
money = 500
print(money) # >>> 500
# 特点三:
from mod2 import * # 取出mod2.py中的所有名字(会占内存)
print(money)
print(func1)
print(func2)
print(change)
# 特点四: __all__
from mod2 import *
print(money)
func1()
func2() # 报错
'''
__all__ 可以指定其所在的py文件,被当做模块导入时,限制导入者能拿到的名字
__all__ = ['变量名1','变量名2',...] (可取到的名字)
'''
四.关于循环导入
如果出现循环导入问题 那么一定是你的程序设计的不合理
循环导入问题应该在程序设计阶段就应该避免
解决循环导入问题的方式
1.方式1
将循环导入的句式写在文件最下方()
2.方式2
函数内导入模块
五.关于__name__
print(__name__)
# 当文件被当做执行文件执行的时候__name__打印的结果是__main__
# 当文件被当做模块导入的时候__name__打印的结果是模块名(没有后缀)
if __name__ == '__main__': # 判断当前文件是否被当做模块导入其他文件
pass
六.模块的查找顺序
1.先从内存中找
2.内置中找
3.sys.path中找(环境变量):
import sys
sys.path.append(r'模块的路径')
# print(sys.path)
from dir import md
模块的查找顺序是以执行文件为准。而执行文件路径只能找到它的同级文件和上一级目录。
不识别其他的文件路径,所以需要将与执行文件同级的,
模块在里面的文件夹路径添加到执行文件的。因为执行文件只能找到与其同级别的文件
七.绝对导入,相对导入
绝对导入必须依据执行文件所在的文件夹路径为准
1.绝对导入无论在执行文件中还是被导入文件都适用
相对导入
.代表的当前路径
..代表的上一级路径
...代表的是上上一级路径
注意相对导入不能再执行文件中使用
相对导入只能在被导入的模块中使用,使用相对导入 就不需要考虑
执行文件到底是谁 只需要知道模块与模块之间路径关系
八.文件目录规范
项目名
bin文件夹
start.py项目启动文件
conf文件夹
settings.py项目配置文件
core文件
src.py项目核心逻辑文件
db文件夹
数据库文件
lib文件夹
common.py项目所用到的公共的功能
log文件夹
log.log项目的日志文件
readme文本文件 介绍项目
start.py项目启动文件格式
import sys
import os
BASE_DIR = os.path.dirname(os.path.dirname(__file__))
sys.path.append(BASE_DIR)
"""
pycharm会自动将你新建的最顶层的目录自动添加到环境变量中
上面这两句话 不是针对你的 是针对下载你这个软件的用户
"""
from core import src
if __name__ == '__main__':
src.run()
# 1.将core文件路径添加到system path中 ...太low
# 2.将ATM文件夹添加到system path中