- 创建数据库表


1 create table person 2 ( 3 FName varchar(20), 4 FAge int, 5 FRemark varchar(20), 6 primary key(FName) 7 )
- 基本sql语句
1 --查询 2 select * from person where FAge<18; 3 --删除 4 delete from person where FRemark='名誉总裁'; 5 --插入 6 insert into person(FAge,FRemark)values(19,'新员工') 7 --更新 8 update person set FRemark='总经理'where FRemark='名誉总裁' or position='副经理';
- 一次插入数据
View Code
INSERT INTO T_ Person(FName,FAge,FRemark) VALUES('Jim',20,'USA'); INSERT INTO T_ Person(FName,FAge,FRemark) VALUES('Lili',22,'China'); INSERT INTO T_ Person(FName,FAge,FRemark) VALUES('XiaoWang',17,' China’);
insert 语句中的顺序可以是任意的,语句中的列的顺序不会影响插入的结果,但是values后面的字段值要和前面的字段值对应.可以忽略某些字段的插入
View Codeinsert into T_person(FAge,FName)values(22,'LXF')
- 不指定插入的列
View Code
insert into T_person values('lurenl',23,'China')
如果不指定要插入的列,values后面的字段要按照数据库定义的字段顺序插入
- 非空约束对数据插入的影响.
如果对一个字段添加了非空约束,是不能向字段中插入null值的,比如T_Debt表的FAmount字段有非空约束.
insert into t_debt(FAmount,Fperson)values(null,'jim')
会报错:不能将值NULL插入列’FAmount',表’dbo.T Debt';列不允许有空值。INSERT失败
- 主键对数据插入的影响
-
主键是在同一张表中必须是唯一的,如果在进行数据插入的时候指定的主键与表中己有
的数据重复的话则会导致违反主键约束的异常。insert into t_debt(FNumber,FAmount,FPerson)values('1',300,'Jim')
会报错:不能在对象dbo.T Debt中插入重复键
- 数据的删除
删除person表里面的所有数据
delete from person;
delete删除的是表中的数据.drop删除数据的同时连表的结构都删除了
drop table person
delete执行完成之后还能查询,只是表是空的数据,drop执行完成之后再select,就会提示"数据表person不存在"
- 给列起别名
别名的定义规则(列名 AS 别名)
View Codeselect FName as name from person
也可以省略as
View Codeselect FName name from person
- 按照条件过滤
SELECT FName FROM T_ Employee WHERE FSalary<5000
- 聚合(最)
- MAX查询年龄大于25岁的员工的最高工资
View Code
select Max(FSalary) from person where FAge>25
- 也可以为聚合函数的结构取别名
View Code
SELECT MAX(FSa工ary) as MAX-SALARY FROM T_ Emp工oyee WHERE FAge>25
- AVG求平均值
View Code
SELECT AVG(FAge) FROM T_ Emp工oyee WHERE FSalary>3800 - SUM求总数
View Code
SELECT SUM(FSa工ary) FROM T_ Emp工oyee
- MIN最小值与MAX一起使用
View Code
SELECT MIN(FSalary),MAX(FSalary) FROM T_ Emp工oyee
- Count计算数据总条数
View Code
SELECT COUNT(*),COUNT(FNumber)FROM T_ Employee
- 排序Order By
- order by位于select 语句的末端(asc代表升序,可以省略:desc是降序,不能省略)
View Code
SELECT * FROM T_ Employee ORDER BY FAge ASC
按照年龄从大到小排序,如果年龄相同则按照
之类的排序功能
View CodeSELECT * FROM T_ Employee ORDER BY FAge DESC,FSalary DESC
- ORDER BY子句完全可以与WHERE子句一起使用(ORDER BY子句要放到WHERE子句之后,不能颠倒它们的顺序)
View Code
SELECT * FROM FAge>23 BY FAge T_ Emp工oyee WHERE ORDER by FAge DESC,FSalary DESC
- 通配符过滤
- like,_
- _(单个通配符)
View Code
SELECT * FROM T_ Employee WHERE FName LIKE '_erry'
以任意字符开头,剩余部分为“erry"
- 要检索长度为4、第3个字符为“n ",其他字符为任意字符
View Code
SELECT * FROM T_ Employee WHERE FName LIKE,'__n_'
- %(多字通配符)
View Code
SELECT * FROM T_ Employee WHERE FName LIKE’T%’
以“T”开头,长度任意。
- 姓名中包含字母"n”的员工信息
View Code
SELECT * FROM T_ Employee WHERE FName LIKE’%n%’
-
单字符匹配和多字符匹配还可以一起使用。
View CodeSELECT * FROM T_ Employee WHERE FName LIKE’%n_'上面表示:最后一个字符为任意字符、倒数第_个字符为“n " ,长度任意的字符串。
- 集合匹配[](表示匹配集合中的任意一个)(只有MSSQLServer支持)
View Code
SELECT * FROM T_Employee WHERE FName LIKE '[SJ]%'
上面代表:以“S”或者“J“开头长度,长度任意
- 否定符"^"(用来对集合取反)(只有MSSQLServer支持)
View Code
SELECT * FROM T_Employee WHERE FName LIKE '[^SJ]%'
上面表示:不以“S”或者“J“开头,长度任意。
- is null和is not null(空值检测)
View Code
SELECT * FROM T_Employee WHERE FNAME IS NOT NULL AND FSalary <5000上面表示:查询所有姓名已知且工资小于5000的员工信息
- "!","<>","not"(反义运算符)
View Code
SELECT * FROM T_Employee WHERE FAge<>22 AND FSALARY !=2000
上面表示:所有年龄不等于22岁并且工资不等于2000元”.(!=和<>)
View CodeSELECT * FROM T_Employee WHERE NOT(FAge=22) AND NOT(FSALARY<2000)
上面表示:检索所有年龄不等于22岁并且工资不小于2000元(not)
- where...or...和in(),(多值运算)
View Code
SELECT FAge,FNumber,FName FROM T_Employee WHERE FAge=21 OR FAge=22 OR FAge=25; SELECT FAge,FNumber,FName FROM T_Employee WHERE FAge IN (21,22,25)
上面两句结果完全一样,都是要把21,22,25的所有信息查询出来
- 范围值查询(between...and...)
View Code
SELECT * FROM T_Employee WHERE FAGE>=23 AND FAGE <=27; SELECT * FROM T_Employee WHERE FAGE BETWEEN 23 AND 27
上面结果完全一样,检索所有年龄介于23岁到27岁之间的员工信息
- group by(分组)
View Code
SELECT FAge FROM T_Employee WHERE FSubCompany = 'Beijing' GROUP BY FAge
GROUP BY子句必须放到SELECT语句的之后,如果SELECT语句有WHERE子句,则GROUP BY子句必须放到WHERE语句的之后。
虽然GROUP BY子句常常和聚合函数一起使用,不过GROUP BY子句并不是不能离开聚合函
数而单独使用的,GROUP BY子句中可以指定多个列,只需要将多个列的列名用逗号隔开即可。 -
数据分组与聚合函数
View CodeSELECT FAge,COUNT(*) AS CountOfThisAge FROM T_Employee GROUP BY FAge
上面表示:查看每个年龄段的员工的人数
- count(*)是会对每个分组统计总数
- having(对部分数组尽心筛选)
View Code
--这是错误的(语法错误) SELECT FAge,COUNT(*) AS CountOfThisAge FROM T_Employee GROUP BY FAge WHERE COUNT(*)>1
上面报错是因为:聚合函数不能在where语句中使用,必须要用having字句来代替.比如下面
View CodeSELECT FAge,COUNT(*) AS CountOfThisAge FROM T_Employee GROUP BY FAge HAVING COUNT(*)>1
HAVING语句中也可以像WHERE语句一样使用复杂的过滤条件:检索人数为1个或者3个的年龄段
View CodeSELECT FAge,COUNT(*) AS CountOfThisAge FROM T_Employee GROUP BY FAge HAVING COUNT(*) =1 OR COUNT(*) =3
也可以使用IN操作符来实现上面的功能
View CodeSELECT FAge,COUNT(*) AS CountOfThisAge FROM T_Employee GROUP BY FAge HAVING COUNT(*) IN (1,3)
- where 和having(使用where的时候group by要位于where之后,使用having的时候group by要位于having之前)
View Code
--这句是错的 SELECT FAge,COUNT(*) AS CountOfThisAge FROM T_Employee HAVING COUNT(*) IN (1,3) GROUP BY FAge
需要特别注意,在HAVING语句中不能包含未分组的列名,例如
View Code--这句是错的 SELECT FAge,COUNT(*) AS CountOfThisAge FROM T_Employee GROUP BY FAge HAVING FName IS NOT NULL
执行的时候数据库系统会提示类似如下的错误信息:
HAVING 子句中的列 'T_Employee.FName' 无效,因为该列没有包含在聚合函数或 GROUP BY 子句中。
需要用WHERE语句来代替HAVING,修改后的SQL语句如下:
View CodeSELECT FAge,COUNT(*) AS CountOfThisAge FROM T_Employee WHERE FName IS NOT NULL GROUP BY FAge
- 限制结果集行数:在进行数据检索的时候有时候需要只检索结果集中的部分行
- MySql(MYSQL中提供了LIMIT关键字用来限制返回的结果集,LIMIT放在SELECT语句的最后位置)(语法:“LIMIT 首行行号,要返回的结果集的最大数目”。)
View Code
select * from person order by age desc limit 2,5;
上面表示:返回按照年龄降序的从第二行开始(行号从0开始)的最多5条记录;
View CodeSELECT * FROM T_Employee ORDER BY FSalary DESC LIMIT 0,5
上面表示:按照工资降序排列的前五条记录
- MSSQLServer 2000(提 供 了 TOP 关 键 字 用来 返回 结 果 集 中的 前 N条 记录)
View Code
select top 5 * from T_Employee order by FSalary Desc
上面表示:检索工资水平排在前五位(按照工资从高到低)的员工信息.
View CodeSELECT top 3 * FROM T_Employee WHERE FNumber NOT IN(SELECT TOP 5 FNumber FROM T_Employee ORDER BY FSalary DESC)ORDER BY FSalary DESC
上面表示:
检索按照工资从高到低排序检索从第六名开始一共三个人的信息;
-
MSSQLServer2005(容几乎所有的MSSQLServer2000的语法,另外提供ROW_NUMBER()帮助更好的限制结果集行数的功能)(ROW_NUMBER()函数可以计算每一行数据在结果集中的行号(从1开始计数))<语法:
ROW_NUMBER OVER(排序规则)
>
View Codeselect ROW_NUMBER() OVER(order by FSalary),FNumber,FName,FSalary,FAge from T_Employee
会输出如下图
 如果想得到第3行到第5行的数据:下面的是错的
View Code
如果想得到第3行到第5行的数据:下面的是错的
View Code--代码是错的 SELECT ROW_NUMBER() OVER(ORDER BY FSalaryDESC),FNumber,FName,FSalary,FAge FROM T_Employee WHERE (ROW_NUMBER() OVER(ORDER BY FSalary DESC))>=3 AND (ROW_NUMBER() OVER(ORDER BY FSalary DESC))<=5
运行时会报错:开窗函数只能出现在 SELECT 或 ORDER BY 子句中::也就是说ROW_NUMBER()不能用在WHERE语句中.
View Codeselect * from (select row_number()over(order by fsalary desc)as rownum,fname,fname,fsalary,fage from t_employee) as a where a.rownum>=3 and a.rownum<=5
上面的结果就是想要的结果
- Oracle(Oracle中支持窗口函数ROW_NUMBER(),其用法和MSSQLServer2005中相同)(orace中定义别名的时候不能用as)
View Code
select * from(select row_number() over(order by fsalary desc) row_num,fnumber,fname,fsalary,fage from t_employee) a where a.row_num>=3 and a.row_num<=5
不过oracle提供了更方便的特性,用来计算行号,oracle为每个结果集都默认增加了一个默认的表示行号的列,这个列的名称为rownum(从1开始计数)
View CodeSELECT * FROM T_Employee WHERE rownum<=6 ORDER BY FSalary Desc
上面表示:按工资从高到底排序的前6名员工的信息;
当进行检索的时候,对于第一条数据,其rownum为1,因为符合“WHERE rownum<=6”
所以被放到了检索结果中;当检索到第二条数据的时候,其rownum为2,因为符合“WHERE
rownum<=6”所以被放到了检索结果中……依次类推,直到第七行。
View Code---这是错误的代码 SELECT rownum,FNumber,FName,FSalary,FAge FROM T_Employee WHERE rownum BETWEEN 3 AND 5 ORDER BY FSalary DESC
当进行检索的时候,对于第一条数据,其rownum为1,因为不符合“WHERE rownum
BETWEEN 3 AND 5”,所以没有被放到了检索结果中;当检索到第二条数据的时候,因为第
一条数据没有放到结果集中,所以第二条数据的rownum仍然为1,而不是我们想像的2,所以因
为不符合“WHERE rownum<=6”,没有被放到了检索结果中;当检索到第三条数据的时候,
因为第一、二条数据没有放到结果集中,所以第三条数据的rownum仍然为1,而不是我们想像的3,所以因为不符合“WHERE rownum<=6”,没有被放到了检索结果中…… - DB2也支持row_number(),语法跟mssql和oracle一样,还提供了fetch关键字用来提取前N行..语法为:fetch first 条数 rows only
View Code
select * from t_employee order by fsalary desc fetch first 6 rows only --必须注意:fetch字句要放在order by语句后面
上面表示:
按工资从高到底排序的前6名员工的信息
View Codeselect * from t_employee where fnumber not in(select fnumber from t_employee order by fsalary desc fetch first 5 rows only) order by fsalary desc fetch first 3 rows only
上面表示:检索按照工资从高到低排序检索从第六名开始一共三个人的信息
- 数据库分页
假设页面上有首页,尾页,上一页,下一页.每页显示条数为PageSize,当前页数(从0开始)为CurrentIndex,那么只要查询从第PageSize*CurrentIndex开始的PageSize条数据,得到的就过就是当前页的数据;点击[上一页],将currentindex设置为currentindex-1;点击[下一页],将currentindex设置为currentindex+1;点击[首页],将currentindex设置为0;点击[尾页],将currentindex设置为 "总条数/PageSize"(如果有余,再加1).
-
抑制数据重复
当我们做数据检索的时候,如果一列的数据有重复的,这不是我们想要的,比如,我们检索公司人元列表的时候,很多部门名称是相同的,这不是我们想要的,我门想要的就是把重复的部门只留下一个,distinct关键字是用来进行重复数据抑制的最简单的功能,而且所有的数据库都支持distinct.distinct语法只需要在select之后增加distinct即可
View Codeselect fdepartment from t_employee
效果是这样的
 View Code
View Codeselect distinct fdepartment from t_employees
加了distinct之后的效果

- DISTINCT是对整个结果集进行数据重复抑制的,而不是针对每一个列
View Code
select distinct fdepartment,fsubcompany from t_employees
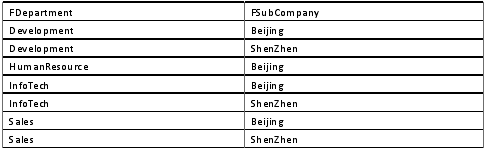 检索结果中不存在fdepartment和fsubcompany列都重复的数据行,但却存在fdepartment列重复的数据行,这就说明DISTINCT是对整个结果集进行数据重复抑制的
检索结果中不存在fdepartment和fsubcompany列都重复的数据行,但却存在fdepartment列重复的数据行,这就说明DISTINCT是对整个结果集进行数据重复抑制的
-
字符串的拼接