一、锁优化的思路和方法
锁的优化是能够尽可能将性能得到提升。锁优化是指怎样在阻塞状态下,尽可能提高性能。
1. 减少锁持有时间

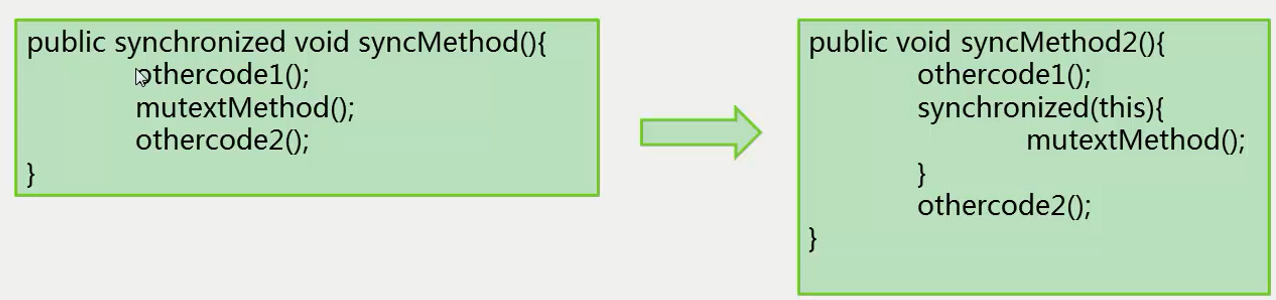
这个程序中如果加了synchronized关键字,进入方法前,要先拿到对象实例的锁。如果这个方法本身里面做很多事情,一个线程进来后,很有可能导致其它线程进不来,优化思路是尽可能减少其它线程等待时间,缩短持有锁的时间缩短。一旦持有锁的时间缩短,大家同时进入临界区的时间缩短。所以没必要把不需要同步的代码,放到synchronized关键字里面,只同步相关代码,尽可能缩小锁的持有时间和持有范围,减少冲突的可能性。
2. 减小锁粒度

加锁可能是对一个很大很重的对象(这个对象可能会被很多线程同时访问)加锁,想法是把大对象所以拆成小对象,增加并行度,降低竞争。
经典例子是HashMap的同步实现。HashMap并不是线程安全的,如果在多线程上使用HashMap,并不安全,安全简单的做法是在Map外面做一层SynchronizedMap的封装,封装后HashMap就编程一个线程同步的。封装内部就是对map的get和put做一个互斥量的同步,在进行get和put之前,都要把互斥量的锁监视器拿到。这样做的问题是HashMap是一个很重要的对象,里面很多的数据,当所有的线程都进来访问的时候,不管是读还是写,都要拿到互斥的对象,因此读会阻塞写,写会阻塞读,同时有多个写多个读,线程是一个个进来,每次只支持对一个对象的读写。

ConcurrentHashMap把一整个HashMap拆成若干个小的segment,每个线程操作的时候只操作小的HashMap,增加并行度。
3. 锁分离

如果系统对程序有读写功能,将读写分离,读与读之间不会相互分离,可以相互访问,不会相互阻塞。如果不使用锁分离,读与读之间也会做阻塞。

LinkedBlockingQueue从头部拿数据,插入数据从尾部,有若干个元素的情况下,两者操作不冲突,所以可以进行更高级别的并发。
4. 锁粗话
通常情况下,为了保证多线程的有效并发,会要求每个线程持有锁的时间尽量短,即在使用完公共资源后,应该立即释放锁。只有这样,等待在这个锁上的其它线程才能尽早的获得资源执行任务。但是,凡事都有一个度,如果对同一个锁不停地高频率的进行请求、同步和释放,其本身也会消耗系统宝贵的资源,反而不利于性能的优化。

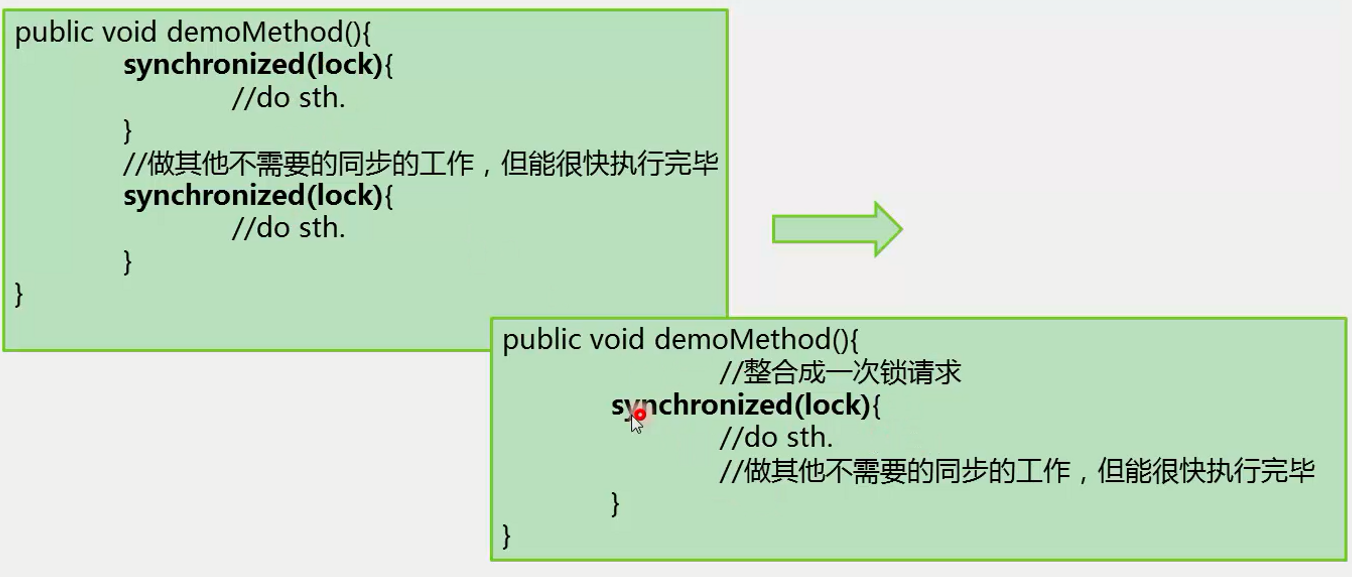
极端情况:
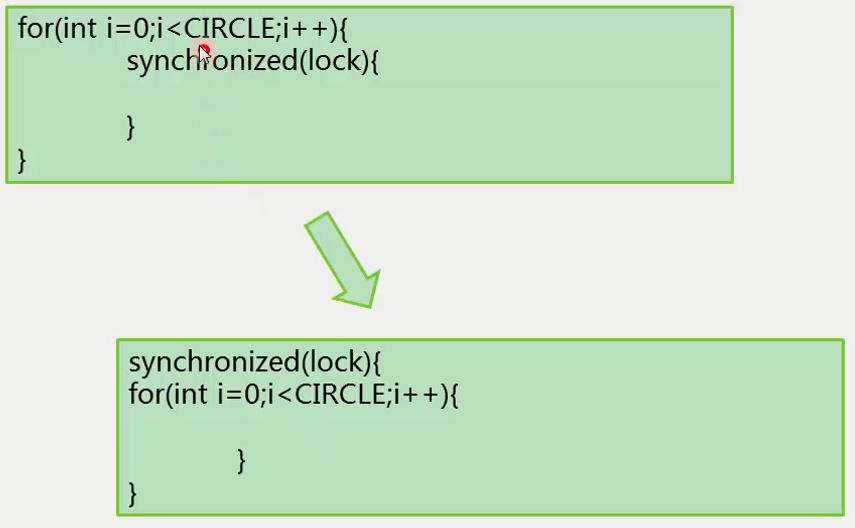
如果在一个循环中不断去请求锁,这个锁被请求很多次,JDK会做一些优化,不如写成下面这样,在循环外侧申请锁,这样从头到尾可以只请求一次锁。
5. 锁消除
在即时编译器时,如果发现不可能被共享的对象,则可以消除这些对象的锁操作。

有些时候,可能对一些完全不可能加锁的代码进行锁的操作。比如使用JDK中的一些类如StringBuffer,在做append时做同步,会自动把锁引入进去,而自己没有察觉,从而可能引入到完全没有多线程的环境中,在这种情况下,为了提高系统性能,可能直接把锁优化掉。
因为createStringBuffer方法append是同步方法,但是此处返回sb.toString(),sb是局部变量,就在线程的栈空间内,就在局部变量表内,其它线程不能访问这个局部变量,所以不能被多个线程访问。所以一定在被这个线程内访问,因此对它所有的同步操作都是没有意义的,有可能对它进行优化,前提开启server模式,开启逃逸分析(return sb, 可能变成全局的公有的变量,这种情况逃出了函数的局部范围),都安全的情况下,就可以进行锁消除。

二、虚拟机内的优化
当使用synchronized虚拟机内部做什么事情
1. 偏向锁
(1) 对象头Mark
Mark Word:对象头的标记,32位
描述对象的hash、锁信息、垃圾回收标记,年龄
- 指向锁记录的指针
- 指向monitor的指针
- GC标记
- 偏向锁线程ID
对象头在32位系统中就是32位的标记,里面可以存放很多信息,比如对象的hash、锁等系统性的信息。
(2)偏向锁
* 大部分情况是没有竞争的,所以可以通过偏向来提高性能
* 所谓的偏向,就是偏心,即锁会偏向于当前已经占有锁的线程
* 将对象头Mark的标记设置为偏向,并将线程ID写入对象头Mark
* 只要没有竞争,获得偏向锁的线程,在将来进入同步块,不需要做同步
* 当其他线程请求相同的锁时,偏向模式结束
* -XX:+UseBiasedLocking -默认启用
* 在竞争激烈的场合,偏向锁会增加系统负担
偏向锁就是很偏心,即锁会偏向于当前已经占有锁的线程,也就是说它会判断一下,当前请求这把锁的线程是不是已经占有这把锁了,如果已经占有了,也就是认为你已经持有这把锁了,你可以进去,有时候会出现线程不停地去请求同一把锁。基于思想:锁是一种悲观的策略,可能会发现数据的竞争,会有冲突,会有线程安全问题,所以要加锁。事实上,冲突的概率多大,不好说。如果负载量不大,一般情况下,竞争是不存在的,我们是杞人忧天。如果竞争不存在的或者竞争不激烈,偏向锁可以拿来提高系统性能。因为一旦一个系统线程持有偏向锁,等她下一次进去的时候,就会判断说是不是属于偏向模式,如果我属于偏向模式,并且偏向模式是我的话,我就直接不会进行锁的操作了,直接进入到锁里面去了,这样可以提高我进入锁的过程速度,系统性能提高。如果没有竞争,只是我一个线程反复进入一把锁,偏向锁会对系统性能提升很重要。
偏向锁实现很简单。把对象头部Mark设置为偏向模式,把线程ID(拿到对象锁的线程)写到对象头部。只要没有竞争,获得偏向锁的线程,在将来进入同步块,不需要做同步,只要看看线程头部的ID是不是我自己。当其他线程请求相同的锁时,偏向模式结束,大家参与竞争。使用UseBiasedLocking启用偏向锁,默认是启用的。在竞争激烈的场合,偏向锁会增加系统负担,因为如果每次偏向模式都会失败,每次都要很容易的把偏向模式结束掉,意味着多进行了一次是否偏向的判断,最终还是要走到锁的逻辑中去,因此偏向锁不会有任何效果。
(3) 偏向锁的例子
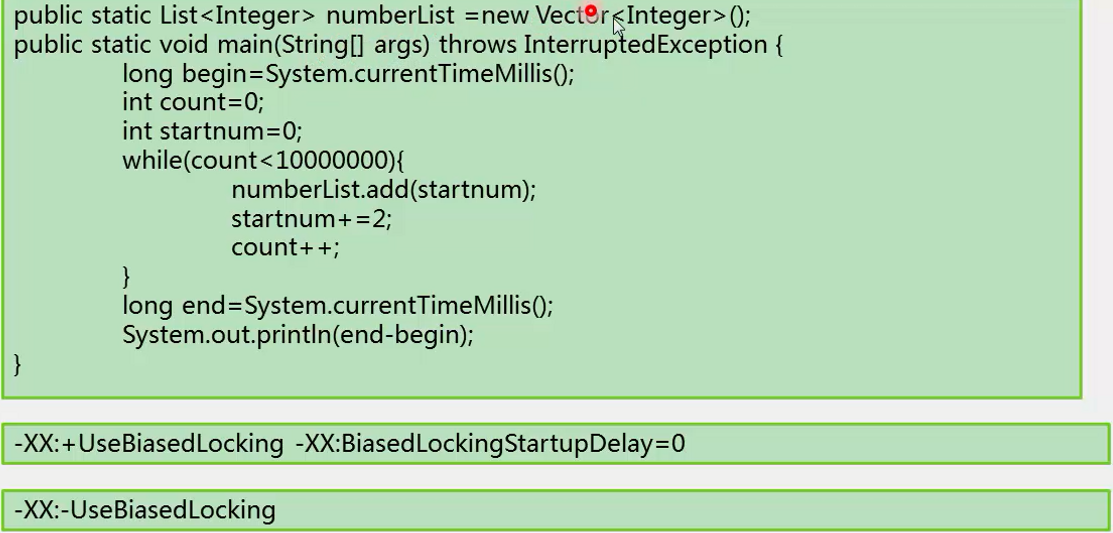
XX:+UseBiasedLocking是使用偏向锁,把偏向锁的StartupDelay时间置为0,在系统起来的几秒钟时间内(4秒),所有的线程同步都不会使用偏向锁。因为系统起来后,刚刚启动,好多事情要做,数据竞争比较激烈,没有必要使用偏向锁模式,但是当几秒后,jvm开启后,偏向模式才真正启动。
此处设置为0,是指系统一启动就启用偏向锁。
XX:-UseBiasedLocking是禁用偏向锁。
本例中,使用偏向锁,可以获得5%以上的性能提升。
2. 轻量级锁
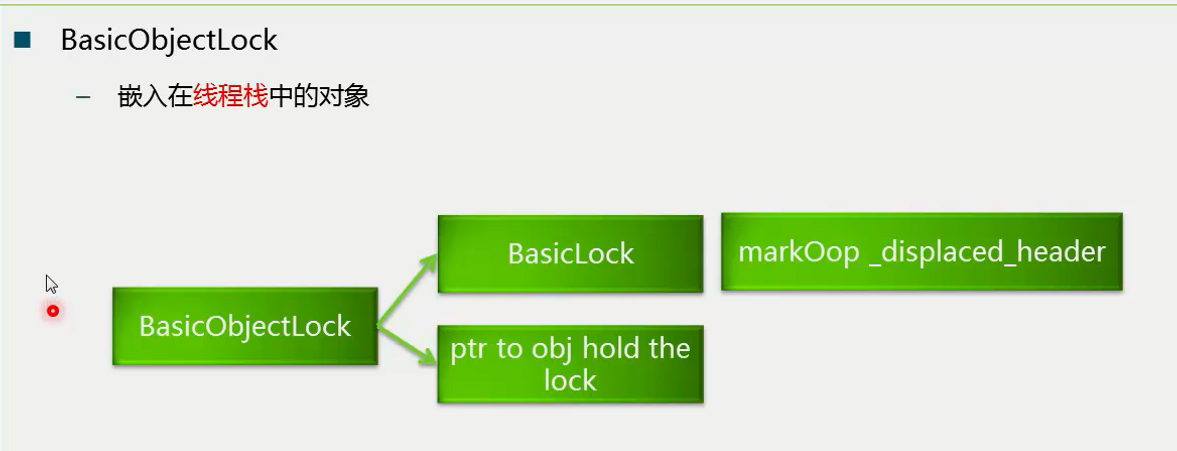
如果偏向锁失败,系统就有可能做轻量级锁。
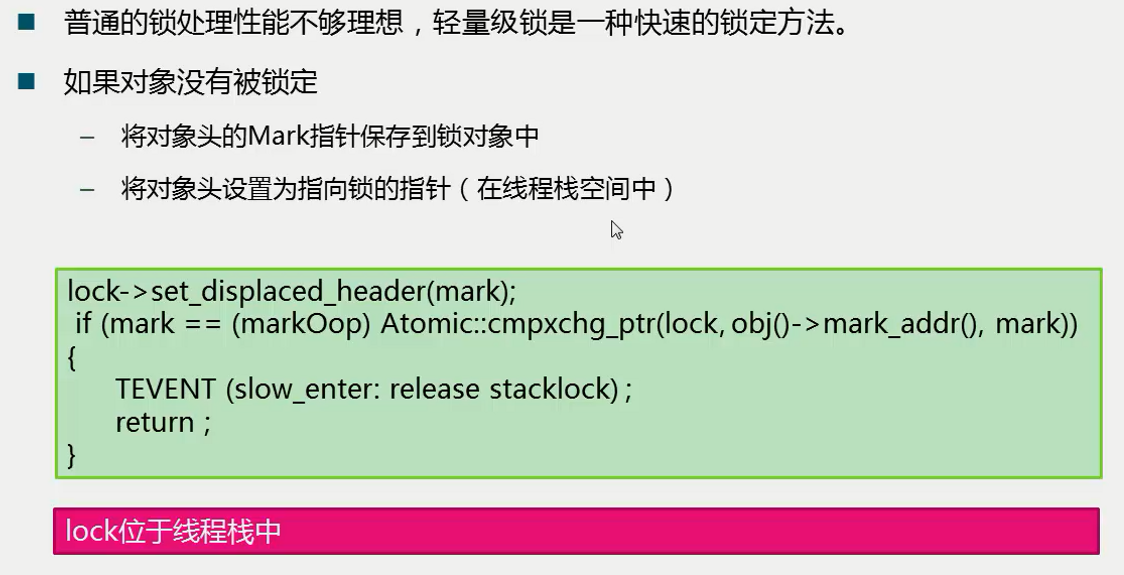
轻量级锁存在的目的是尽可能不动用操作系统层面的互斥,因为那个性能比较差。对于操作系统来说,JVM本身就是一个应用,所以我们希望在应用层面去解决线程同步的问题。轻量级锁就是这样一个思想,我们判断一个线程是否持有某一个对象锁,我们就看这个lock头部的set_dispalced_header是不是设置了这个对象的Mark,如果是,我们会说这个线程就持有了这把锁。
也就是说它会做两件事情,一个是将对象头的Mark指针保存到锁对象中,另一个是将对象头设置为指向锁的指针(同时,注意锁在线程栈空间中)。
这样我需要要判断一个线程是否持有这把锁时,只需要判断对象头部所指向的空间,是不是在线程栈的地址空间中,如果是则认为你持有这把锁,如果不是则认为你不持有这把锁。
如果轻量级锁失败,表示存在竞争,升级为重量级锁(常规锁)
在没有锁竞争的前提下,减少传统锁使用OS互斥量产生的性能损耗
在竞争激烈时,轻量级锁会多做很多额外操作,导致性能下降
常规锁可能动用操作系统的同步方法。
3. 自旋锁
当竞争存在时,如果线程很快获得锁,那么可以不在OS层挂起线程,让线程做几个空操作(自旋)
JDK1.6中-XX:+UseSpining开启
JDK1.7中,去掉此参数,改为内置实现
如果同步块很长,自旋失败,会降低系统性能
如果同步块很短,自旋成功,节省线程挂起切换时间,提高系统性能
如果轻量级锁失败,有可能动用操作系统系统层面的互斥量,有可能不去动用,是因为轻量级锁失败后会尝试自旋锁。
ConcurrentHashMap的put操作,如果发现锁已经被别人拿走了,这时候我们会看到ConcurrentHashMap并不是急着把自己挂起,而是做一个try-lock操作,trylock没有阻塞,它只是一个简单的CAS操作,也就是看看锁对应的AtomicInteger(表示加锁的字段)能不能拿到,如果不能拿到,则会做一个循环,
在循环当中,我们会不断的尝试重新做tryLock操作。
当你拿不到锁时,不要急着把线程挂起,会做几个空循环,当超过最大尝试次数,再挂起。
在虚拟机内部,当轻量级锁也没有办法拿到锁的时候,会去做最后的尝试,就是自旋。自旋会去做一个空循环,并不停地去尝试拿到锁,当大家锁的持有时间都不是特别长的时候,所以空循环有可能经过若干个循环等待后,别人把锁释放掉了,因此可以很顺利把锁拿到,避免线程在操作系统层面被挂起,性能有所提升。
4. 偏向锁、轻量级锁、自旋锁总结
不是Java语言层面的锁优化方法
内置于JVM中的获取锁的优化方法和获取锁的步骤
* 偏向锁可用会先尝试偏向锁
* 轻量级锁可用会先尝试轻量级锁
* 以上失败,尝试自旋锁
* 再失败,尝试普通锁,使用OS互斥量在操作系统层挂起
三、一个错误使用锁的案例

错误原因,对i加锁,然后对它做++操作。integer是不变操作,其实内部使用自动拆箱,改变的不是Integer的值,改变的是i本身的引用,生成新的int值,赋值到i上。
两个线程之间所同步的对象未必相同,对不同的对象做++操作,结果和想象不一样。
四、ThreadLocal及其源码分析
1. ThreadLocal使用案例
ThreadLocal是最彻底的完全的把锁去除掉的方法。有点像在多线程当中,对有数据冲突的对象要进行加锁,把锁去掉的最简单的方法,为每一个线程都提供一个线程实例,不同的线程访问自己的对象,不访问别人的对象。
ThreadLocal思想:多线程中,有数据冲突的对象要加锁。把锁去掉最简单的方法是每一个线程都提供一个对象实例,每个线程访问自己的对象,锁就没必要存在了。
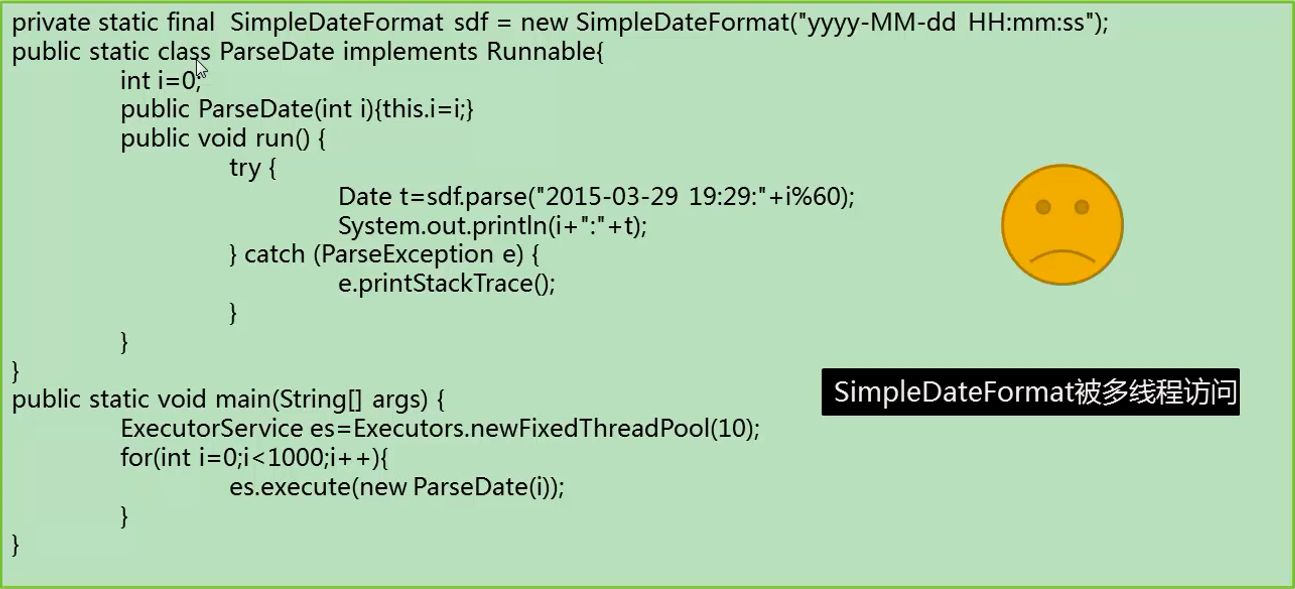
上面代码中,sdf不是线程安全的。
这里我们使用SimpleDateFormat类,用来格式化时间,我们调用parse方法解析时间,然后把时间做一个打印。但是这样写代码,共用一个变量实例,实际上这段代码不能正常执行。原因是sdf不是线程安全的,所以对它操作时,它被多个线程同时访问时,程序会抛出异常,导致它不能正常工作。改成线程安全的方法可以包装一个synchronized,但是在高并发时对synchronized的征用,会效率很低。

相对好的方法是用ThreadLocal封装sdf,声明一个tl,这里面装了sdf,在每一个线程中,如果线程没有变量,get方法表示我拿到当前线程的sdf,就把这个对象设置进去。然后解析时拿当前线程的对象做解析。然后把数据拿出来打印。这样做的后果是,每一个线程会新建一个sdf对象,调用parse时不会有线程安全问题。

错误写法:在外面声明一个唯一的对象tl和sdf,我把它设置到tl中去,每一次也是从ThreadLocal里面拿,然后去做解析,这样的写法是不对的。看起来用了ThreadLocal,但实际上在对每一个ThreadLocal对象实例,都指向了同一个对象实例,所以不是线程安全的。
正确的写法是每一个线程new一个对象出来,原因是ThreadLocal维护线程对应的对象,不会维护每一个对象的拷贝。在set时是把原对象设置进去了,它不会set后把对象复制一份到内存中去,它直接把tl对象中的数据指向了sdf。如果希望每一个线程都有一个自己的对象,就每次new一个,不要把一个公共的东西设置进去。
在hibernate中在保存connection时就使用了ThreadLocal,有些时候我们希望公共类(工具类、数据库连接类)对于每一个线程来讲,自己持有一个,这样减少了数据同步的开销。而这样的工具类,多个线程不希望相互影响,所以可以使用ThreadLocal、
2. ThreadLocal实现源码

首先拿到线程,去拿到线程的ThreadLocalMap,所谓ThreadLocalMap是定义在线程Thread中的一个字段,所谓的线程局部变量ThreadLocalMap隶属于线程Thread,也就是这个map提供了ThreadLocal所有的内部的奥秘,当拿到map后,每个线程都有自己的map。当把值设置上去的时候,有key和value,key是ThreadLocal本身,value是设进去的值。
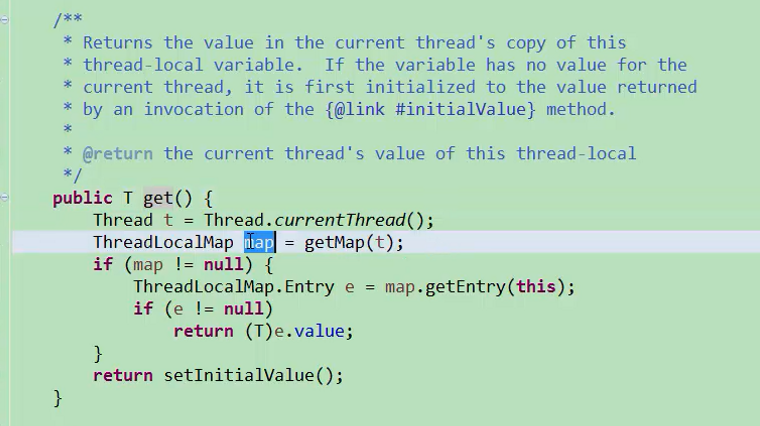
每一个线程都知道某一个ThreadLocal变量值是多少value,因此当get的时候,也能得到entry,进而拿到value。
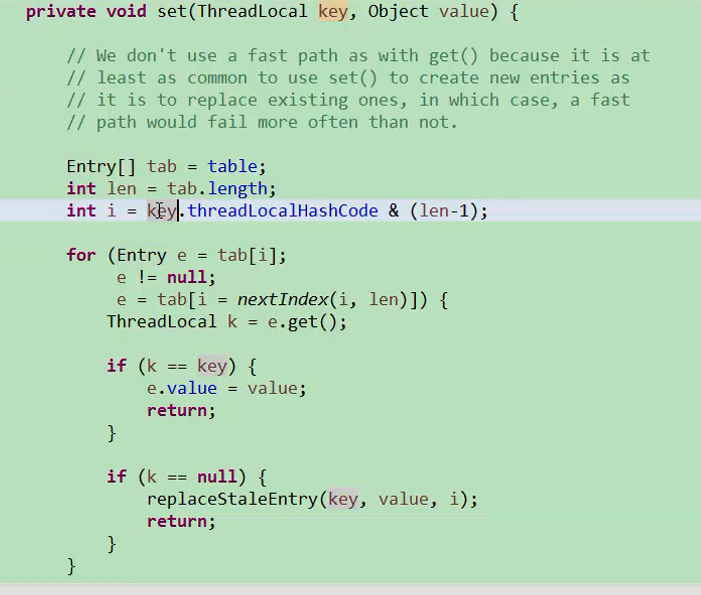
ThreadLocalMap基本类似HashMap,整个map的实现依赖数组entry数组,entry存放值,并进程弱引用,如果没有数据引用到这个对象的话,这个对象会被系统释放掉。
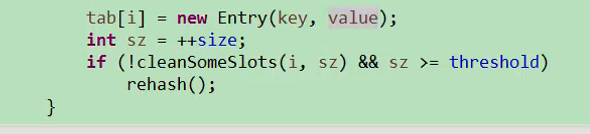
首先做一个hash的映射,把它映射到i当中去。拿到i之后,然后把值设置到table第i个元素中。如果entry当前没有数据存放,就新建一个entry,把key和value存放到hash表当中去。如果有数据存放,首先判断key是否相同,如果相同就把value覆盖掉,如果不相同,就用下一个下标(i++),对entry进行赋值,这里的实现和hash表略有不同。
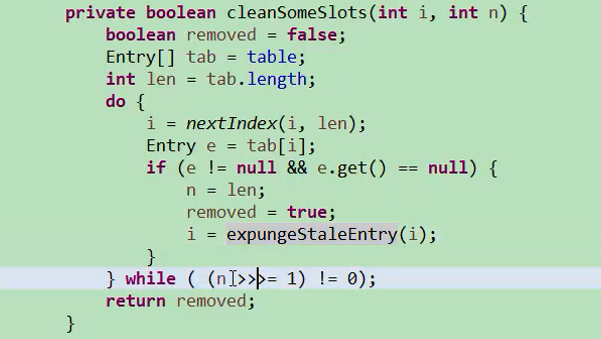
clenSomeSlots会清空没有用的项目,这个扫描不是一个完全的扫描,而是把n左移一位,移除的条件是entry不为null,如果ThreadLocal本身被回收掉了,那就有可能导致ThreadLocal指向的value有可能被回收掉,这样把对象回收掉。