小表驱动大表
1、概念
驱动表的概念是指多表关联查询时,第一个被处理的表,使用此表的记录去关联其他表。驱动表的确定很关键,会直接影响多表连接的关联顺序,也决定了后续关联时的查询性能。
2、原则
驱动表的选择遵循一个原则:
在对最终结果集没影响的前提下,优先选择结果集最小的那张表作为驱动表。改变驱动表就意味着改变连接顺序,只有在不会改变最终输出结果的前提下才可以对驱动表做优化选择。外连接的顺序改变就很可能影响结果。
预估结果集的原则:
- 如果where里没有相应表的筛选条件,无论on里是否有相关条件,默认为全表
- 如果where里有筛选条件,但是不能使用索引来筛选,那么默认为全表
- 如果where里有筛选条件,而且可以使用索引,那么会根据索引来预估返回的记录行数
3、识别
- explain显示结果里排在第一行的就是驱动表
4、嵌套循环算法
(1) 4种算法
- 在使用索引关联的情况下,有Index Nested-Loop join和Batched Key Access join两种算法;
- 在未使用索引关联的情况下,有Simple Nested-Loop join和Block Nested-Loop join两种算法;
(2) Nested-Loop Join Algorithms
一个简单的嵌套循环联接(NLJ)算法,循环从第一个表中依次读取行,取到每行再到联接的下一个表中循环匹配。这个过程会重复多次直到剩余的表都被联接了。通过外循环的行去匹配内循环的行,所以内循环的表会被扫描多次。
for each row in t1 matching range {
for each row in t2 matching reference key {
for each row in t3 {
if row satisfies join conditions,
send to client
}
}
}
(3) Block Nested-Loop Join Algorithm
一个块嵌套循环联接(BNL)算法,将外循环的行缓存起来,读取缓存中的行,减少内循环的表被扫描的次数。
MySQL使用联接缓冲区时,会遵循下面这些原则:
-
join_buffer_size系统变量的值决定了每个联接缓冲区的大小;
-
联接类型为ALL、index、range时(换句话说,联接的过程会扫描索引或数据时),MySQL会使用联接缓冲区;
-
缓冲区是分配给每一个能被缓冲的联接,所以一个查询可能会使用多个联接缓冲区;
-
联接缓冲区永远不会分配给第一个表,即使该表的查询类型为ALL或index;
-
联接缓冲区联接之前分配,查询完成之后释放;
-
使用到的列才会放到联接缓冲区中,并不是所有的列;
-
每个join关键字就对应着一个join buffer,也就是驱动表和第二张表用一个join buffer,得到的块结果集与第三章表用一个join buffer
设S是每次存储t1、t2组合的大小,C是组合的数量,则t3被扫描的次数为:
(S * C)/join_buffer_size + 1

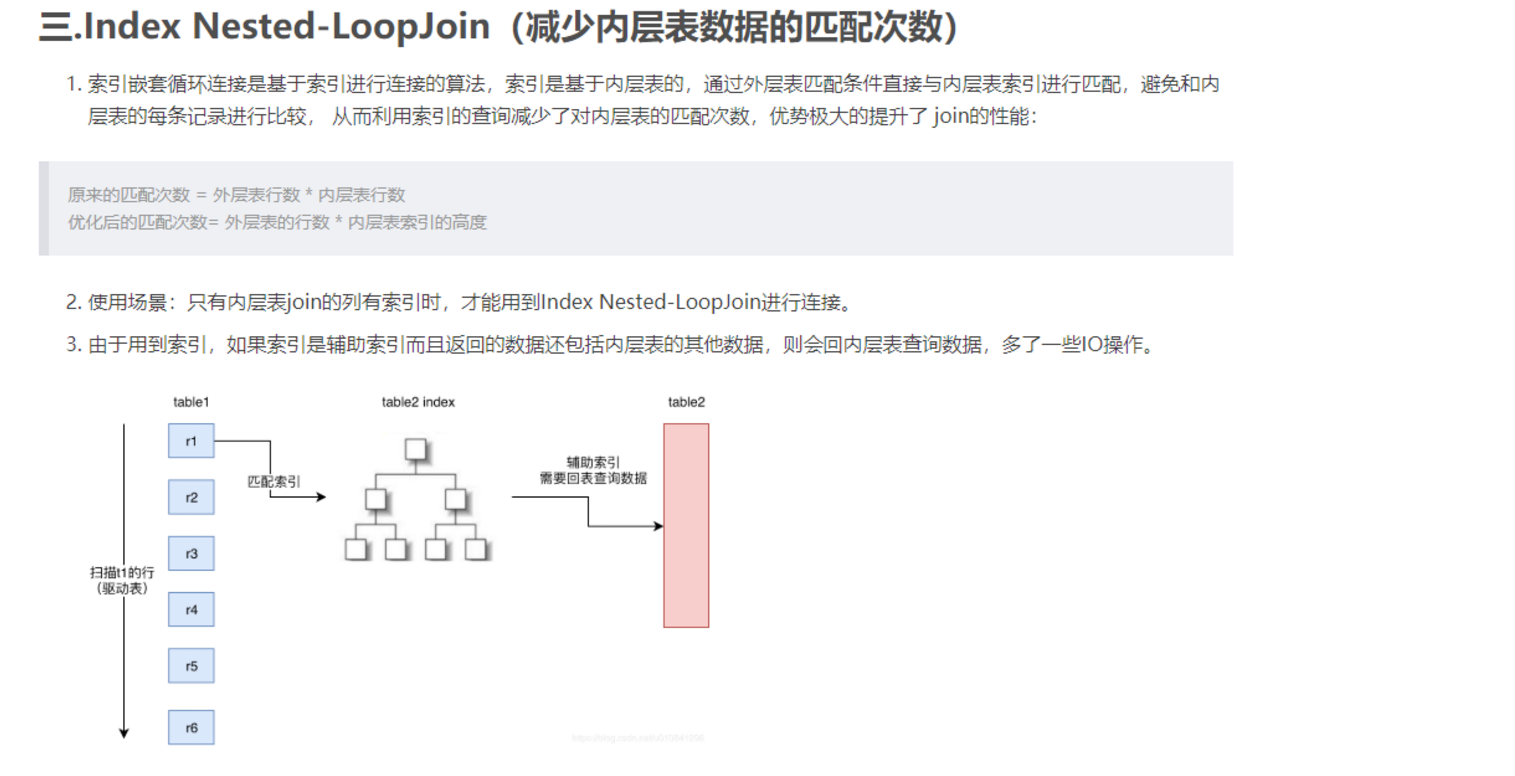
(4) Index Nested-Loop join
通过索引关联被驱动表,使用的是Index Nested-Loop join算法,不会使用msyql的join buffer。根据驱动表的筛选条件逐条地和被驱动表的索引做关联,每匹配到符合的记录,放入net-buffer中,然后继续关联,直到net-buffer满了,返回给client,清空net-buffer,此缓存区由net_buffer_length参数控制
(5) Batched Key Access join
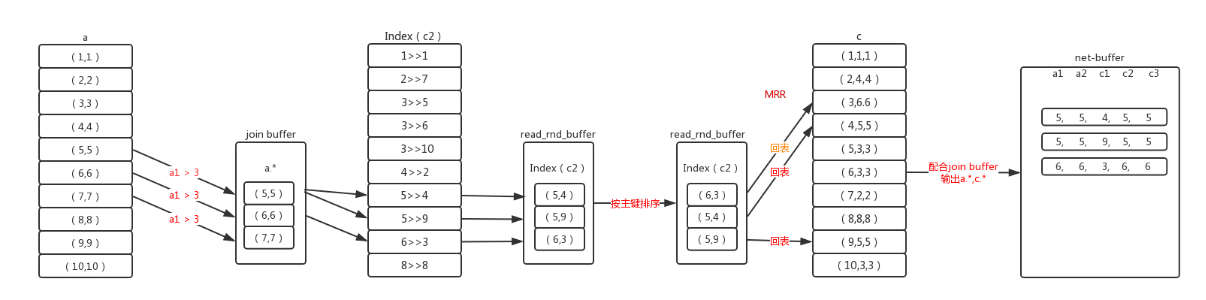
原理:
1、逐条的根据where条件查询驱动表,将符合记录的数据行放入join buffer,然后根据关联的索引获取被驱动表的索引记录,存入read_rnd_buffer。join buffer和read_rnd_buffer都有大小限制,无论哪个到达上限都会停止此批次的数据处理,等处理完清空数据再执行下一批次。也就是驱动表符合条件的数据可能不能够一次处理完,而要分批次处理。
2、当达到批次上限后,对read_rnd_buffer里的被驱动表的索引按主键做递增排序,这样在回表查询时就能够做到近似顺序查询
3、因为mysql的InnoDB引擎的数据是按聚集索引来排列的,当对非聚集索引按照主键来排序后,再用主键去查询就使得随机查询变为顺序查询,而计算机的顺序查询有预读机制,在读取一页数据时,会向后额外多读取最多1M数据。此时顺序读取就能排上用场。
以下示例均以此为基础数据:
create table a(a1 int primary key, a2 int ,index(a2)); --双字段都有索引
create table c(c1 int primary key, c2 int ,index(c2), c3 int); --双字段都有索引
create table b(b1 int primary key, b2 int); --有主键索引
create table d(d1 int, d2 int); --没有索引
insert into a values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(10,10);
insert into b values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(10,10);
insert into c values(1,1,1),(2,4,4),(3,6,6),(4,5,5),(5,3,3),(6,3,3),(7,2,2),(8,8,8),(9,5,5),(10,3,3);
insert into d values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(10,10);
sql如下:
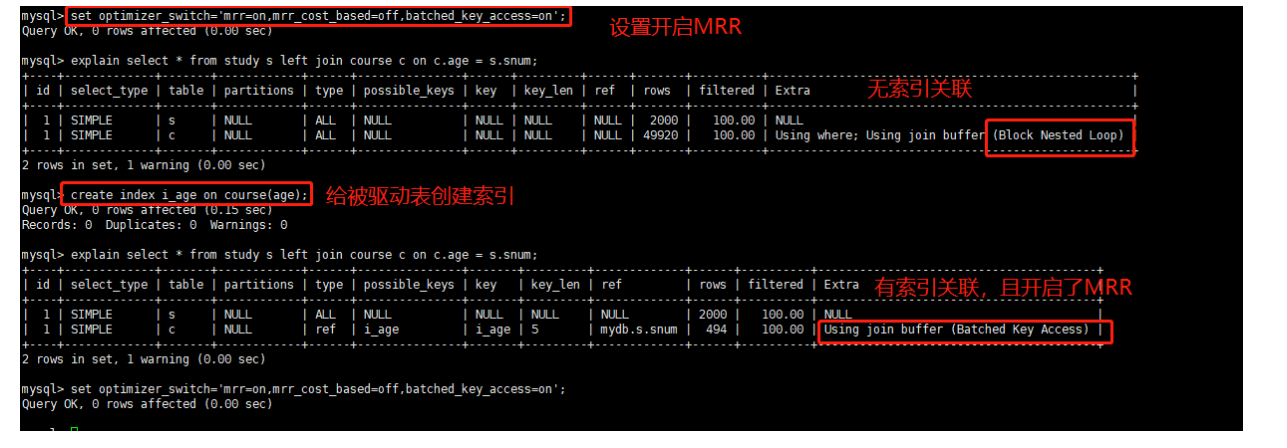
select a.*,c.* from a join c on a.a2=c.c2 where a.a1>4;(下图应为a1>4)
使用:
BKA算法在需要对被驱动表回表的情况下能够优化执行逻辑,如果不需要会表,那么自然不需要BKA算法
如果要使用 BKA 优化算法的话,你需要在执行 SQL 语句之前先设置:
set optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
前两个参数的作用是要启用 MRR(Multi-Range Read)。这么做的原因是,BKA 算法的优化需要依赖于MRR,官方文档的说法,是现在的优化器策略,判断消耗的时候,会更倾向于不使用 MRR,把 mrr_cost_based 设置为 off,就是固定使用 MRR 了。)
(6)嵌套循环的执行过程
多表连接如何执行?是先两表连接的结果集然后关联第三张表,还是一条记录贯穿全局?
sql如下:
select a.*,b.*,c.* from a join c on a.a2=c.c2 join b on c.c2=b.b2 where b.b1>4;
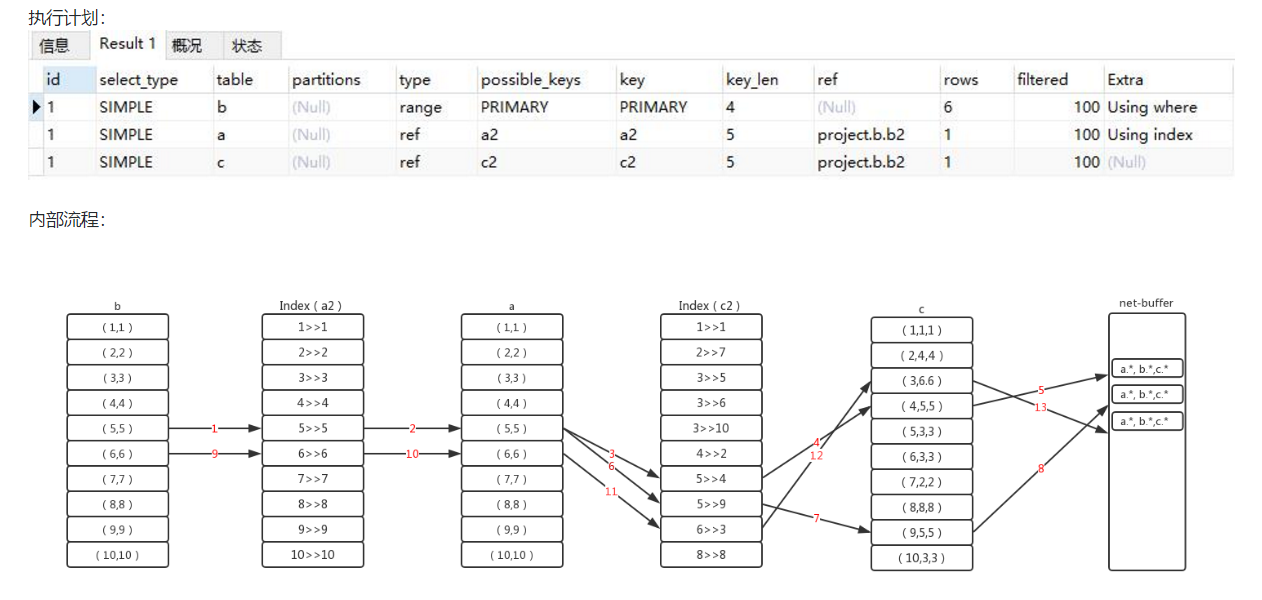
(7) 根据关联索引选择算法