使用Python+selenium实现第一个自动化测试脚本
一,安装Python.
python官方下载地址:https://www.python.org/downloads/
安装后点击开始菜单,在菜单最上面能找到IDLE.
IDLE是python自带的shell, 点击打开, 即可开始编写python脚本了.
二,安装selenium
上面python已安装完成,接下来安装selenium.
安装selenium之前需要安装必要工具. setuptools
安装后,(比如zip包形式安装),进入解压的目录,在命令行执行如下命令即可安装.
python setup.py install
再然后安装pip
https://pypi.python.org/pypi/pip
同样,安装tar或解压包,进入目录cmd执行python setup.py install即可安装
安装selenium
上面2个工具安装好后,安装selenium只需在命令行进入python安装路径Script目录下,执行
pip install -U selenium


即可自动安装.
完成安装后在IDLE输入
from selenium import webdriver

如果没报错即代表安装成功.
三,注意事项
selenium3.0 需要独立安装FireFox驱动.解压后放在python安装路径下即可.
geckodriver驱动要求FireFox浏览器必须48版本以上,如果不是,更新FireFox.
如果用Java开发,需注意3.0必须用JDK1.8版本才行.
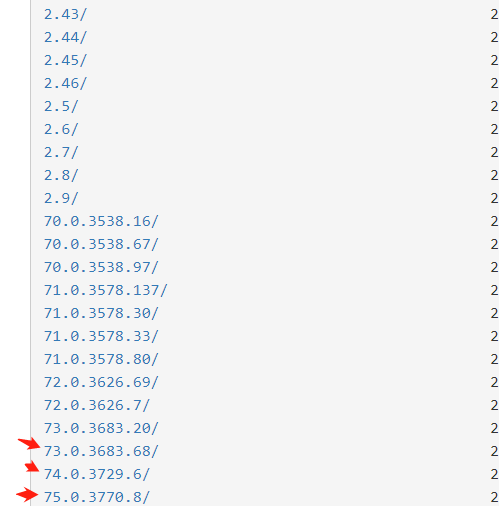
同样谷歌的驱动,没FQ只能使用阿里的镜像了.
注意阿里的镜像对应的谷歌的版本:
四,第一个自动化脚本
完成上面所有准备工作,就可以开始第一个自动化脚本的编写了.
打开IDLE,通过快捷键CTRL+N打开一个新窗口,在新窗口输入以下代码:
# coding = utf-8
from selenium import webdriver
browser = webdriver.Firefox()
browser.get("http://www.baidu.com")
browser.find_element_by_id("kw").send_keys("selenium")
browser.find_element_by_id("su").click()
browser.quit()
这里如果关的过快,就需要将browser.quit()给去掉.不然看不见操作
写完脚本后脚本页执行F5快捷键运行脚本,可以看到脚本启动FireFox浏览器进入百度页面,输入”selenium”点击搜索按钮,第一个脚本即完成了.
代码解析:
# coding = utf-8
(为了防止乱码问题,以及在程序中添加中文注释,把编码统一成UTF-8;)
from selenium import webdriver
(导入selenium的webdriver包,导入webdriver包后才能使用webdriver API进行自动化脚本开发.)
browser = webdriver.Firefox()
(将控制的webdriver的Firefox赋值给browser,获得了浏览器对象才可以启动浏览器;)
browser.get("http://www.baidu.com")
(获得浏览器对象后,通过get()方法,向浏览器发送网址;)
browser.find_element_by_id("kw").send_keys("selenium")
(通过id=kw定位到百度的输入框,并通过键盘方法send_keys()向输入框输入selenium;)
browser.find_element_by_id("su").click()
(通过id=su定位到搜索按钮,并向按钮发送单击事件(click());)
browser.quit()
(退出并关闭窗口的每一个相关的驱动程序.)
名词解释:
1.
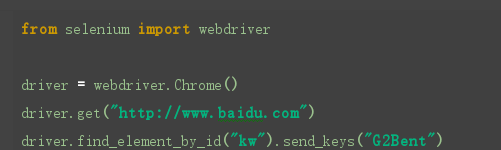
find_element_by_id()
我们可以直接通过英文意思理解这个方法,通过ID查找元素,也就是使用页面里的id属性:id=”“. 我们先定位百度搜索框,在搜索框里输入我们要查找的内容.
2.
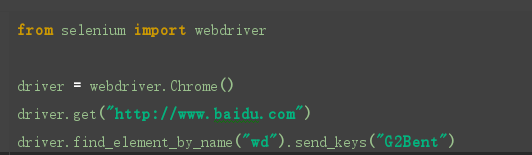
find_element_by_name()
这个定位的方法是通过查找名字的方式,对元素进行定位,我们在检查元素的时候看到name=”“,就可以使用这个方法了.
3.
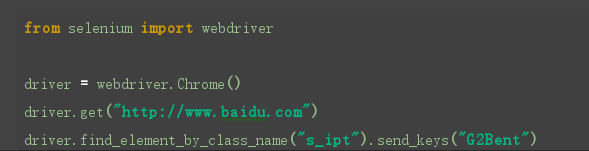
find_elements_by_class_name()
这个定位的方法是通过查找class_name的方式对元素进行定位,在检查元素的时候看到class=”“,就可以使用这个方法了.
4.
find_element_by_tag_name()
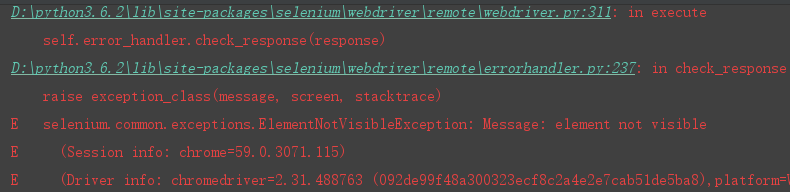
这个定位的方法是通过元素的标签属性对元素进行定位,在检查元素的时候查看元素的最前面的input,但是这个定位方式有个不好的地方在于很多页面都有同样的标签存在,所以我们定位的时候会很麻烦.
所以,这个方法我们不推荐使用. 这个方法也是仅供参考.

实际上是会报错的,因为selenium在定位的时候不清楚我们要找的是哪个元素.
我们如果一定要用这个方法的花,我们就需要清楚,我们定位的标签的精准位置.
5.
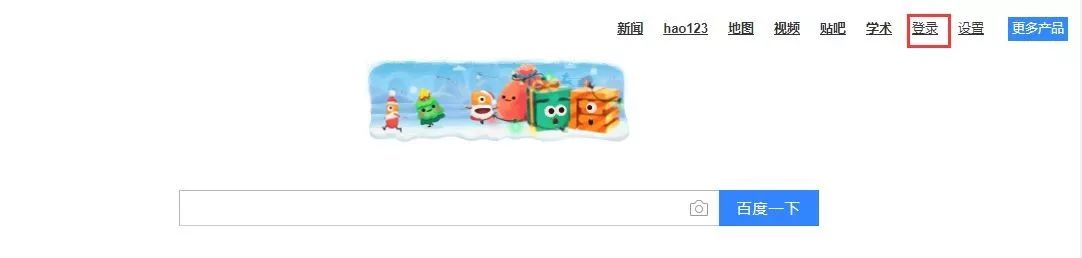
find_element_by_link_text()
这个定位方式是通过查找页面的文本信息进行定位. 也就是我们看到页面的信息去定位, 例如:我们需要定位百度首页的登录按钮.并点击它.

6.
find_element_by_partial_link_text()
这个方法的定位方式就是通过模糊文本信息查找元素,有些时候,我们希望定位到一个文本比较长的元素时,我们就可以通过这个方法去定位.
例如: 定位百度首页页脚下的”使用百度前必读”, 我们是输入”使用”.
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
driver.find_element_by_partial_link_text("使用").click()
这样我们也是可以定位到该元素的.
7.
find_element_by_xpath()
最后来说两种最常用的定位方法,xpath元素定位:通过查找元素的路径去查找元素.
这两个方法在使用上目前很广泛,也很多人推荐使用.这两个很方便,因为浏览器已经帮我们做好准备了,我们只需要复制粘贴就可以了.
我们继续定位搜索框.

这样我们直接复制xpath路径就可以了,这样就可以解决我们会输入错误元素的问题(注:在使用xpath的时候,最外面的双引号改成单引号.
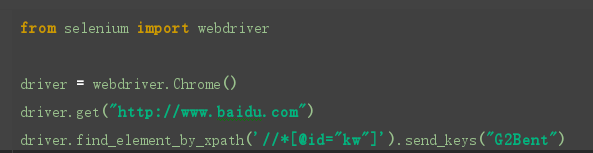
8.
find_element_by_css_selector()
css在操作上跟xpath差不多,也是通过复制粘贴的方式进行定位,不同在于css方法通过对页面中的css元素定位的.
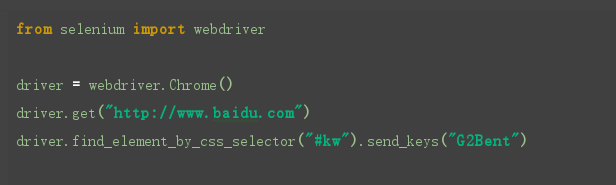
之上8条的原blog,内涵有其它的脚本界面工具Autolt的介绍
假设测试test1.给定登录页面的username和password,并点击登录按钮,进行自动登录测试
代码如下:
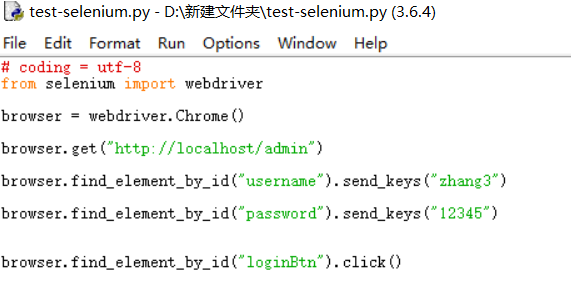
就可以以这条脚本运行,而.py文件保存到桌面也可以直接双击运行(首先要安装python)

加入再测试其它功能可以根据获取id,name等继而进行测试操作.上面只是基本测试.
之后需要进行测试案例的编写,返回测试数据. 以及与ones.ai自动化测试连接.
ones的对接文档
通用说明
流水线(pipeline)
| 参数名 | 值类型 | 取值范围 | 默认值 | 取值例子 | 说明 |
| uuid | string | len=8 | pipeline uuid | ||
| name | string | len<=32 | pipeline 名称 | ||
| owner | string | len=8 | pipeline 创建者 uuid | ||
| create_time | int64 | pipeline 创建时间(秒) | |||
| project | object | pipeline 绑定的 project 信息 | |||
| uuid | string | len=8 | 项目 uuid | ||
| name | string | 项目名称 | |||
| configure_statuses | object | pipeline 配置状态 | |||
| scm | object | 代码仓库集成配置状态,参考下方说明 | |||
| ci | object | 持续集成配置状态,参考下方说明 | |||
| lint | object | 代码质量检查配置状态,参考下方说明 | |||
| test | object | 自动化测试配置状态,参考下方说明 | |||
| artifact | object | 部署结果关联配置状态,参考下方说明 | |||
| branches | array | pipeline 下的已知分支列表,参考下方说明 | |||
| branch_sprint_bindings | array | pipeline 下分支与迭代的绑定列表,参考下方说明 | |||
| sprint_binding_rule | string | pipeline 与项目下迭代的自动绑定规则, 参考下方说明 |
API 说明
1. pipeline 回调
创建一个 pipeline
URL
https://api.ones.ai/project/team/:teamUUID/pipeline/:pipelineUUID/callback
HTTP Method
POST
调用权限
无
传值方式
JSON
参数说明
{
"action": "stage",
"stage": {
"type": "test",//stage 类型:start,finish,lint,test
"name": "test",//stage 名称, eg: "test"
"start_time": start_time, //阶段的开始时间,单位秒
"finish_time": finish_time, //阶段的结束时间,单位秒
"status": status, //stage 状态:unknown,success,failure
},
"payload": {
"test": {
"executions": [{
"language":"python", // 测试语言
"framework":"selenium", // 测试框架名
"id":"", // 执行结果的 ID
"start_time":""// 开始执行的时间,单位毫秒
"finish_time":"" // 执行完成的时间,单位毫秒
"name": "用例名",
"description":"用例描述",
"result": "执行结果", //success, failure, error, skip, unexpected_success, expected_failure
"message": "错误消息"
}]
}
}
}
返回的HTTP status code
| 状态码 | 说明 |
| 200 | 成功 |
| 400 | 请求结构错误 |
| 403 | token 无效,无权限 |
| 500 | 服务器错误 |
| 801 | 参数错误 |
返回JSON
| 参数名 | 值类型 | 取值范围 | 默认值 | 取值例子 | 说明 |
| pipeline | object | 参考顶端 pipeline 模型 |