小白使用Bert跑分类模型
2019.3.18 Monday - 3.19 Tuesday
网上使用Bert跑文本分类的教程很多:
Blog:https://blog.csdn.net/u012526436/article/details/84637834
Github地址:https://github.com/google-research/bert
很神奇的一点,点击直接下载速度超级慢,但是右键保存下载速度很快。
Run_classifier.py
1.main函数入口中,flags.mark_flag_as_required()。TF定义了tf.flags用于支持接受命令行传递参数,相当于接受args。该方法则是在程序运行前将某些命令行参数加入到“必备参数”的字典中,以判断解析完的参数是否满足这些必备要求。
2.Tf.logging.set_verbosity() : 五个不同级别的日志消息。DEBUG, INFO, WARN, ERROR AND FATAL, 设置为哪个级别TensorFlow则输出与该级别相对应的所有日志消息以及所有级别的严重级别。默认设置为Warn, 但是在跟踪模型训练时,可以将级别调整为INfo, 这将提供适合操作正在进行的其他反馈。
3.导入上一级模块的包:
parentdir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.insert(0, parentdir)
from data_helpers import *
4.Tf.app.flags.define_string() 定义一个用于接收string类型数值的变量。三个参数:1. 变量名称 2. 默认值 3. 用法描述
5.warmup_proportion:warm up 步数的比例,比如说总共学习100步,warmup_proportion=0.1表示前10步用来warm up,warm up时以较低的学习率进行学习(lr = global_step/num_warmup_steps * init_lr),10步之后以正常(或衰减)的学习率来学习。
6.https://www.cnblogs.com/jiangxinyang/p/10241243.html 里面的分类方法都可以尝试一下!
7. Bert 的 封装性很强,调用一下estimator的train和evaluate函数就搞定了。黑盒的好处是我们可以拿来用,坏处是用了之后调来调去发现这破盒子啥玩意都输出不来,只能破罐子破摔拆盒子才行。这样就有点麻烦了。我的二分类数据结果F值总是0, 也就是训练了半天什么东西都没学得。
- 进行简单调参,lr, batch, epoch, max_length都调了调,我习惯调地差距很大,如果结果有强烈的变化,说明这个按钮是管用的!然而所有的按钮都“坏掉了”。
- 数据输入部分的问题,为了跑的更快,我从训练集中先只截取了几千条用于训练,因为Bert有一个max_length参数,当embedding的维度超过最大长度时会进行自动截断。我认为是把我训练集中的句子都一半一半地输进去导致结果为0的。于是做了个对照组,可以先把短的数据(小于512)挑出,保证数据的正负例均衡度没有那么差,放进去看看效果有什么不同。然而结果并没有什么不同。
Len :70776
Positive : 21653
Negative : 49123 - 最后想是不是迭代次数不够多,我在代码中加入了显示train_loss的步骤,3个epoch+train_batch=16, loss始终没有收敛的迹象。
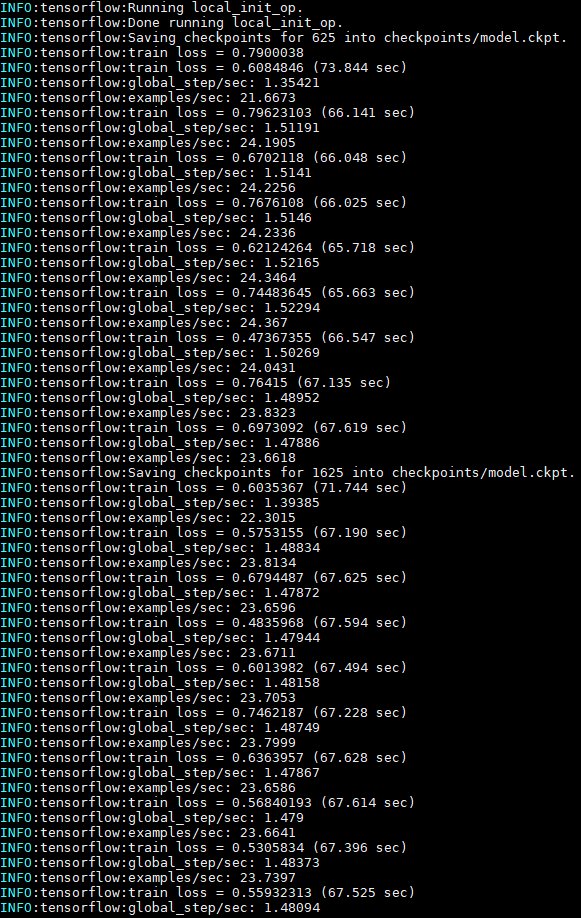
- batch调为32的时候服务器都会OOM,看来是跑不动这些个十几万的数据了。初步分析我认为是文本进行特征提取的步骤出现的问题。BERT的具体原理我也不是很懂。还是再跑几个简单的分类模型好了。