1.pandas需要配合sqlalchemy的使用
import pandas as pd from sqlalchemy import create_engine engine = create_engine("mysql+pymysql://%s:%s@%s:3306/%s?charset=utf8" % (TEST_DB.user, TEST_DB.password, TEST_DB.host, TEST_DB.db)) exec_sql = '' source_table = pd.read_sql(exec_sql, engine)
2.遍历数据
# index代表索引,从0开始 # v代表数据库中的数据 for index,v in source_table.iterrows(): print(index, v) # 精确取出数据,需要注意的是,取出的数据值,是一个series类型数据,不是string,需要string()后才可使用split v["字段名称"]即可
3.更改数据
# 使用iloc方法, source_table.iloc[index,2] = int(result) >>> df = pd.DataFrame(mydict) >>> df a b c d 0 1 2 3 4 1 100 200 300 400 2 1000 2000 3000 4000 **Indexing just the rows** With a scalar integer. >>> type(df.iloc[0]) <class 'pandas.core.series.Series'> >>> df.iloc[0] a 1 b 2 c 3 d 4 Name: 0, dtype: int64 With a list of integers. >>> df.iloc[[0]] a b c d 0 1 2 3 4 >>> type(df.iloc[[0]]) <class 'pandas.core.frame.DataFrame'> >>> df.iloc[[0, 1]] a b c d 0 1 2 3 4 1 100 200 300 400 With a `slice` object. >>> df.iloc[:3] a b c d 0 1 2 3 4 1 100 200 300 400 2 1000 2000 3000 4000 With a boolean mask the same length as the index. >>> df.iloc[[True, False, True]] a b c d 0 1 2 3 4 2 1000 2000 3000 4000 With a callable, useful in method chains. The `x` passed to the ``lambda`` is the DataFrame being sliced. This selects the rows whose index label even. >>> df.iloc[lambda x: x.index % 2 == 0] a b c d 0 1 2 3 4 2 1000 2000 3000 4000 **Indexing both axes** You can mix the indexer types for the index and columns. Use ``:`` to select the entire axis. With scalar integers. >>> df.iloc[0, 1] 2 With lists of integers. >>> df.iloc[[0, 2], [1, 3]] b d 0 2 4 2 2000 4000 With `slice` objects. >>> df.iloc[1:3, 0:3] a b c 1 100 200 300 2 1000 2000 3000 With a boolean array whose length matches the columns. >>> df.iloc[:, [True, False, True, False]] a c 0 1 3 1 100 300 2 1000 3000 With a callable function that expects the Series or DataFrame. >>> df.iloc[:, lambda df: [0, 2]] a c 0 1 3 1 100 300 2 1000 3000 """
4.删除字段
# axis=1代表列 values_table = source_table.drop('字段名', axis=1)
5.数据库更新
.to_sql()更新数据时,con必须使用"sqlalchemy",如果使用pymysql会报错
6.选择某些列
import pandas as pd # 从Excel中读取数据,生成DataFrame数据 # 导入Excel路径和sheet name df = pd.read_excel(excelName, sheet_name=sheetName) # 读取某些列,生成新的DataFrame newDf = pd.DataFrame(df, columns=[column1, column2, column3])
7.读取某些列,并根据某个列的值筛选行
newDf = pd.DataFrame(df, columns=[column1, column2, column3])[(df.column1 == value1) & (df.column2 == value2)]
8.添加新的列
# 第一种直接赋值 df["newColumn"] = newValue # 第二种用concat组合两个DataFrame pd.concat([oldDf, newDf])
9.更改某一列的值
# 第一种,replace df["column1"] = df["column1"].replace(oldValue, newValue) # 第二种,map df["column1"] = df["column1"].map({oldValue: newValue}) # 第三种,loc # 将column2 中某些行(通过column1中的value1来过滤出来的)的值为value2 df.loc[df["column1"] == value1, "column2"] = value2
10.填充缺失值
# fillna填充缺失值 df["column1"] = df["column1"].fillna(value1)
11.过滤出某些列
Examples df = pd.DataFrame(np.array(([1, 2, 3], [4, 5, 6])), index=['mouse', 'rabbit'], columns=['one', 'two', 'three']) df one two three mouse 1 2 3 rabbit 4 5 6 # select columns by name df.filter(items=['one', 'three']) one three mouse 1 3 rabbit 4 6 # select columns by regular expression df.filter(regex='e$', axis=1) one three mouse 1 3 rabbit 4 6 # select rows containing 'bbi' df.filter(like='bbi', axis=0) one two three rabbit 4 5 6
12.mean()用法
Pandas Series.mean()函数返回给定Series对象中基础数据的平均值。
用法: Series.mean(axis=None, skipna=None, level=None, numeric_only=None, **kwargs)
参数:
axis:要应用的功能的轴。
skipna:计算结果时排除NA /null值。
level:如果轴是MultiIndex(分层),则沿特定级别计数,并折叠成标量。
numeric_only:仅包括float,int,boolean列。
**kwargs:要传递给函数的其他关键字参数。
返回:均值:标量或系列(如果指定级别)
# 求和,求平均: import pandas as pd student = pd.read_excel("C:/Users/Administrator/Desktop/Students.xlsx",index_col="ID") temp = student[["Test_1","Test_2","Test_3"]] student["total"] = temp.sum(axis=1)#axis 0为列,1为行 student["avg"] = temp.mean(axis=1) print(student)
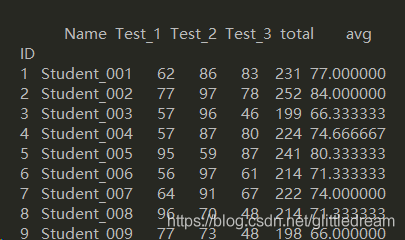
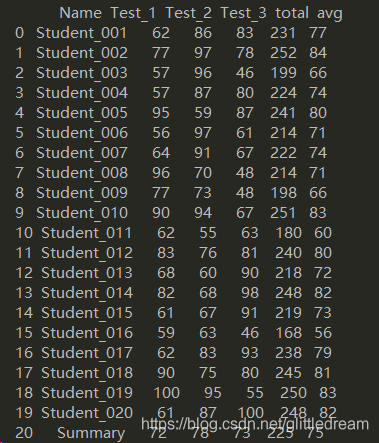
#算各科成绩平均,求和: col_mean = student[["Test_1","Test_2","Test_3","total","avg"]].mean() col_mean["Name"]="Summary" student = student.append(col_mean,ignore_index=True) student[["Test_1","Test_2","Test_3","total","avg"]] = student[["Test_1","Test_2","Test_3","total","avg"]].astype(int) print(student)
转自https://www.cnblogs.com/jiangxinyang/p/9672785.html
转自https://blog.csdn.net/glittledream/article/details/87902161