楔子
到目前为止,我们已经介绍了很多关于解释器方面的内容,本来接下来应该要说内存管理的,但是个人觉得应该对前面的系列做一个总结。而最好的方式,就是使用Python/C API编写扩展模块,个人是这么认为的。我们编写过不少Python的模块,但显然用的都是Python语言,那么问题来了,我们如何使用C语言来编写呢?
使用C为Python编写扩展的话,是需要遵循一定套路的,而这个套路很固定。那么下面我们就来用Python写一个模块,看看这个模块如何使用C语言来实现。
关于扩展模块,这里不得不提一下Cython,使用Python/C API编写扩展是一件不轻松的事情,其实还是C语言本身比较底层吧。而Cython则是帮我们解决了这一点,Cython代码和Python高度相似,而cython编译器会自动帮助我们将Cython代码翻译成C代码,再编译成扩展模块,所以Cython本质上也是使用了Python/C API,只不过它让我们不需要直接面对C,只要我们编写Cython代码即可,会自动帮我们转成C的代码。
所以随着Cython的出现,现在使用Python/C API编写扩展的话算是越来越少了,不过话虽如此,使用Python/C API编写可以极大的帮助我们熟悉Python的底层。
那么废话不多说,直接开始吧。
编写扩展模块的基本骨架
我们先用Python编写一个模块,模块名就叫fubuki吧,也就是创建一个fubuki.py。
def f1():
"""return an integer"""
return 123
def f2(a):
"""return a + 123"""
return a + 123
非常简单的一个模块,里面只有两个简单的函数,但是我们知道当被导入时它就是一个PyModuleObject对象,里面除了我们定义的两个函数之外还有其它的属性,显然这是Python解释器在背后帮助我们完成的。
那么我们如何使用C来进行编写呢?注意接下来,我的这波操作。
/*
编写Python扩展模块,需要引入Python.h这个头文件
这个头文件,在Python安装目录的include目录下,编译的时候会自动寻找
当然这个头文件里面还导入了很多其它的头文件,我们也可以直接拿来用
*/
#include "Python.h"
/*
编写我们之前的两个函数f1和f2,必须返回PyObject *
函数里面至少要接收一个PyObject *self,而这个参数我们是不需要管的,当然不叫self也是可以的
显然跟方面方法里面的self是一个道理,所以对于Python调用者而言,f1是一个不需要接收参数的函数
*/
static PyObject *
f1(PyObject *self)
{
return PyLong_FromLong(123);
}
static PyObject *
f2(PyObject *self, PyObject *a, PyObject *b)
{
long _a, _b;
long result;
_a = PyLong_AsLong(a);
_b = PyLong_AsLong(b);
result = _a + _b;
return PyLong_FromLong(result);
}
/*
定义一个结构体数组,结构体类型为PyMethodDef
PyMethodDef里面有四个成员,分别是:函数名、函数指针(需要转成PyCFunction)、函数参数标识、函数的doc
关于PyMethodDef我们后面会单独说
*/
static PyMethodDef fubuki_function[] = {
{
"f1",
(PyCFunction)f1,
METH_NOARGS, //后面说
"this is a function named f1"
},
{
"f2",
(PyCFunction)f2,
METH_O, //后面说
"this is a function named f2"
},
//结尾要有两个NULL
{NULL, NULL}
};
/*
我们编写的py文件,解释器会自动把它变成一个模块,但是这里我们需要手动定义
定义一个PyModuleDef类型结构体
*/
static PyModuleDef fubuki_module = {
PyModuleDef_HEAD_INIT, //头部信息,Python.h中提供了这个宏
"fubuki", //模块名
"this a module named fubuki", //模块的doc,没有的话直接写成NULL即可
-1, //模块的空间,这个不需要关心,直接写成-1即可
fubuki_function, //上面的那么PyMethodDef结构数组,必须写在这里,不然我们没法使用定义的函数
//下面直接写4个NULL即可
NULL, NULL, NULL, NULL
};
//到目前为止,前置工作就做完了,下面还差两步
/*
扩展库入口函数,这是一个宏,Python的源代码我们知道是使用C来编写的
但是编译的时候为了支持C++的编译器也能编译,于是需要通过extern "C"定义函数
然后这样C++编译器在编译的的时候就会按照C的标准来编译函数,这个宏就是干这件事情的,主要和python中的函数保持一致
*/
PyMODINIT_FUNC
/*
模块初始化入口,注意:模块名叫fubuki,那么下面就必须要写成PyInit_fubuki
*/
PyInit_fubuki(void)
{
// 将使用PyModuleDef定义的模块对象的指针传递进去,然后返回得到Python中的模块
return PyModule_Create(&fubuki_module);
}
整体逻辑还是非常简单的,过程如下:
include "Python.h",这个是必须的定义我们函数,具体定义什么函数、里面写什么代码完全取决于你的业务定义一个PyMethodDef结构体数组定义一个PyModuleDef结构体定义模块初始化入口,然后返回模块对象
那么如何将这个C文件变成扩展模块,显然要经过编译。
from distutils.core import *
setup(
# 打包之后会有一个egg_info,表示该模块的元信息信息,name就表示打包之后的egg文件名
# 显然和模块名是一致的
name="fubiki",
version="1.11", # 版本号
author="古明地盆",
author_email="66666@东方地灵殿.com",
# 关键来了,这里面接收一个类Extension,类里面传入两个参数
# 第一个参数是我们的模块名,必须和PyInit_xxx中的xxx保持一致,否则报错
# 第二个参数是一个列表,表示用到了哪些C文件,因为扩展模块对应的C文件不一定只有一个,我们这里是fubuki.c
ext_modules=[Extension("fubuki", ["fubuki.c"])]
)
当前的py文件名叫做1.py,我们在控制台中直接输入python 1.py install即可。
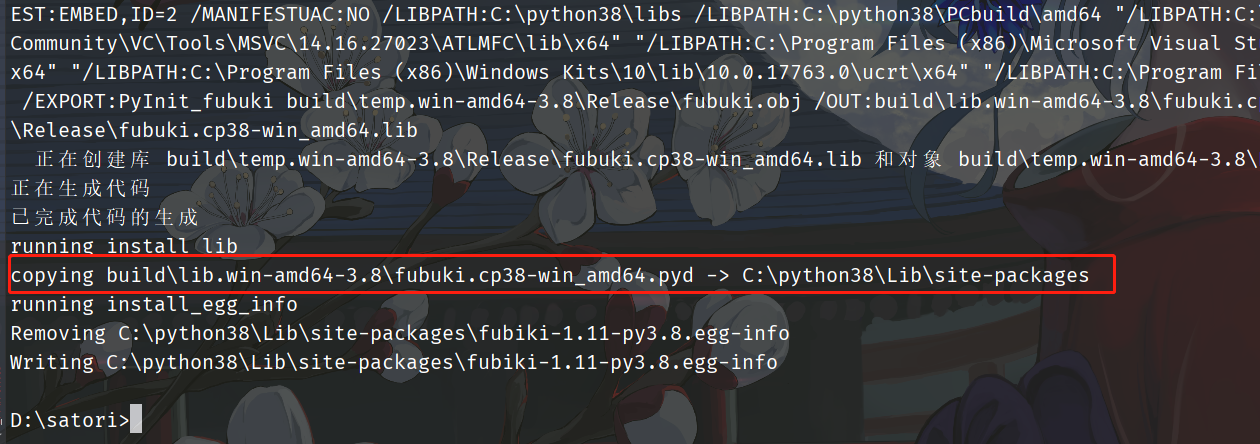
我们看到对应的pyd已经生成了,自动帮我们拷贝到site-packages目录中了。

我们看到了一个fubuki.pyd文件,至于中间的部分就是解释器版本,然后上面的egg-info,指的就是模块fubuki的元信息,我们打开看看。
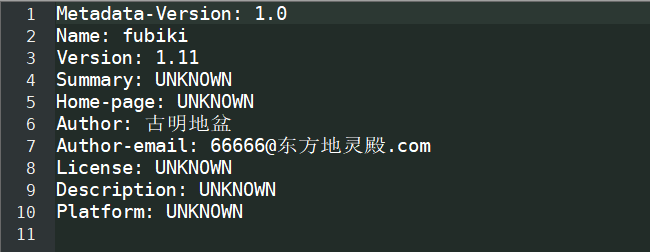
有几个我们没有写,所以是UNKNOW,当然这都不重要,重要的是我们能不能调用了。试一试吧,当然要先把之前写的fubuki.py删掉。
import fubuki
print(fubuki.f1()) # 123
print(fubuki.f2(123)) # 246
最后再看一个神奇的东西,我们知道在pycharm这样的智能编辑器中,通过Ctrl加左键可以调到指定模块的指定位置。

神奇的一幕出现了,我们点击进去居然还能跳转,其实我们在编译成扩展模块移动到site-packages之后,pycharm就自动生成了。我们看到模块注释、函数的注释跟我们在C文件中指定的一样。
函数参数(位置参数)
编写扩展模块的基本骨架按照上面说的那样子做就可以,不过我们还遗留了一个问题,那就是参数。我们看到上面必须定义一个PyMethodDef结构体数组,那么这个PyMethodDef是什么呢?我们之前说过的。
struct PyMethodDef {
/* 内置的函数或者方法名 */
const char *ml_name;
/* 实现对应逻辑的C函数,但是需要转成PyCFunction类型,主要是为了更好的处理关键字参数 */
PyCFunction ml_meth;
/* 参数类型
#define METH_VARARGS 0x0001 扩展位置参数
#define METH_KEYWORDS 0x0002 扩展关键字参数
#define METH_NOARGS 0x0004 不需要参数
#define METH_O 0x0008 需要一个参数
#define METH_CLASS 0x0010 被classmethod装饰
#define METH_STATIC 0x0020 被staticmethod装饰
*/
int ml_flags;
//函数的__dic__
const char *ml_doc;
};
typedef struct PyMethodDef PyMethodDef;
如果不需要参数,那么ml_flags传入一个METH_NOARGS,接收一个参数传入METHOD_O即可,所以我们上面的f1对应的ml_flags是METHOD_NOARGS,f2对应的ml_flags是METHOD_O。
如果是多个参数,那么直接写成METHOD_VARAGRS即可,也就是通过扩展位置参数的方式,但是这要如何解析呢?比如:有一个函数f3接收3个参数,这在C中要如何实现呢?
static PyObject *
f3(PyObject *self, PyObject *args)
{
//目前我们定义了一个PyObject *args,如果是METH_O,那么这个args就是对应的一个参数
//如果METH_VARAGRS,还是只需要定义一个*args即可,只不过此时的*args是一个PyTupleObject,我们需要将多个参数解析出来
//假设此时我们这个函数是接收3个int,然后相加
int a, b, c;
/*
下面我们需要使用PyArg_ParseTuple进行解析,因为我们接收三个参数
这个函数返回一个整型,如果失败会返回0,成功返回非0
*/
if (!PyArg_ParseTuple(args, "iii", &a, &b)){
//失败返回NULL,后面我们会介绍如何在底层返回一个异常
return NULL;
}
return PyLong_FromLong(a + b + c);
}
所以重点就在PyArg_ParseTuple上面,这个函数的原型就是:int PyArg_ParseTuple(PyObject *args, const char *format, ...),我们注意到format,显然类似于printf,里面肯定是一些占位符,那么都支持哪些占位符呢?
i:接收一个Python中的int,然后解析成C的intl:接收一个Python中的int,然后将传来的值解析成C的longf:接收一个Python中的float,然后将传来的值解析成C的floatd:接收一个Python中的float,然后将传来的值解析成C的doubles:接收一个Python中的str,然后将传来的值解析成C的char *u:接收一个Python中的str,然后将传来的值解析成C的wchar_t *O:接收一个Python中的object,然后将传来的值解析成C的PyObject *
占位符比较多,但是我们暂时只需要掌握上面七个即可,下面演示一下。
#include "Python.h"
static PyObject *
f(PyObject *self, PyObject *args)
{
int a;
long b;
float c;
double d; //关于object和字符串我们暂时先不试,留在后面,目前只需要知道这个函数怎么用即可
if (!PyArg_ParseTuple(args, "ilfd", &a, &b, &c, &d)){
return NULL;
}
printf("int: %d, long: %d, float: %f, double: %lf
", a, b, c, d);
return Py_None; //Py_None就是Python中的None
}
static PyMethodDef fubuki_function[] = {
{
"f",
(PyCFunction)f,
METH_VARARGS, //这里记得一定要改成METH_VARARGS,表示接收多个参数
"this is a function named f"
},
{NULL, NULL}
};
static PyModuleDef fubuki_module = {
PyModuleDef_HEAD_INIT,
"fubuki",
"this a module named fubuki",
-1,
fubuki_function,
NULL, NULL, NULL, NULL
};
PyMODINIT_FUNC
PyInit_fubuki(void)
{
return PyModule_Create(&fubuki_module);
}
然后编译成扩展模块,执行一下吧。当然这里编译的过程我们就不显示了,跟之前是一样的。并且为了方便,我们的模块名就不改了,还叫fubuki,但是编译之后的pyd文件内容已经变了,不过需要注意的是,编译之后会有一个build目录,然后会自动把里面的pyd文件拷贝到site-packages中,如果你修改了代码,但是模块名没有变的话,那么编译之后的文件名还和原来一样。如果一样的话,那么它发现已经存在相同文件了,就不会再拷贝了。因此两种做法:要么你把模块名给改了,这样编译会生成新的模块。要么编译之前记得把上一次编译生成的build目录先删掉,我们推荐第二种做法,不然site-packages目录下会出现一大堆我们自己定义的模块。
import fubuki
# 传参不符合,自动给你报错
try:
print(fubuki.f())
except TypeError as e:
print(e) # function takes exactly 4 arguments (0 given)
try:
print(fubuki.f(123))
except TypeError as e:
print(e) # function takes exactly 4 arguments (1 given)
try:
print(fubuki.f(123, "xxx", 123, 123))
except TypeError as e:
print(e) # an integer is required (got type str)
fubuki.f(123, 123, 123, 123) # int: 123, long: 123, float: 123.000000, double: 123.000000
怎么样,是不是很简单呢?当然PyArg_ParseTuple解析失败,Python底层自动帮你报错了,告诉你缺了几个参数,或者类型是哪里错了。
设置异常
下面我们介绍一下如何设置一个异常,我们还是定义一个函数,接收3个object对象。第一个参数类型是int、第二个参数类型是float、第三个参数类型是str。
#include "Python.h"
static PyObject *
f(PyObject *self, PyObject *args)
{
PyObject PyObject *obj1, *obj2, *obj3;
/*
Py_REFCNT: 获取引用计数
Py_TYPE: 获取类型
Py_SIZE: 获取ob_size
*/
int ob_size = Py_SIZE(args);
if (ob_size != 3){
//设置完异常之后直接return NULL即可,PyErr_Format用来设置异常,接收异常类型(PyExc_异常)、异常信息
PyErr_Format(PyExc_TypeError, "function f need takes 3 argument, but got %d", ob_size);
return NULL;
}
//得到三个PyObject *
if (!PyArg_ParseTuple(args, "OOO", &obj1, &obj2, &obj3)){
return NULL;
}
int arg1 = strcmp(Py_TYPE(obj1) -> tp_name, "int") == 0;
if (!arg1){
PyErr_Format(PyExc_TypeError, "arg1 require an integer, got %s", Py_TYPE(obj1) -> tp_name);
return NULL;
}
int arg2 = strcmp(Py_TYPE(obj2) -> tp_name, "float") == 0;
if (!arg2){
PyErr_Format(PyExc_TypeError, "arg2 require a float, got %s", Py_TYPE(obj2) -> tp_name);
return NULL;
}
int arg3 = strcmp(Py_TYPE(obj3) -> tp_name, "str") == 0;
if (!arg3){
PyErr_Format(PyExc_TypeError, "arg3 require an string, got %s", Py_TYPE(obj3) -> tp_name);
return NULL;
}
return PyUnicode_FromString("congratulations~~~");
}
static PyMethodDef fubuki_function[] = {
{
"f",
(PyCFunction)f,
METH_VARARGS, //这里记得一定要改成METH_VARARGS
"this is a function named f"
},
{NULL, NULL}
};
static PyModuleDef fubuki_module = {
PyModuleDef_HEAD_INIT,
"fubuki",
"this a module named fubuki",
-1,
fubuki_function,
NULL, NULL, NULL, NULL
};
PyMODINIT_FUNC
PyInit_fubuki(void)
{
return PyModule_Create(&fubuki_module);
}
编译成扩展模块,调用一下。
import fubuki
# 传参不符合,自动给你报错
try:
print(fubuki.f())
except TypeError as e:
print(e) # function f need takes 3 argument, but got 0
try:
print(fubuki.f(123))
except TypeError as e:
print(e) # function f need takes 3 argument, but got 1
try:
print(fubuki.f(123, "xxx", 123, 123))
except TypeError as e:
print(e) # function f need takes 3 argument, but got 4
try:
print(fubuki.f(123, 123, "xxx"))
except TypeError as e:
print(e) # arg2 require a float, got int
print(fubuki.f(123, 123., "xxx")) # congratulations~~~
传递关键字参数
传递关键字参数的话,那么我们可以通过key=value的方式来实现,那么在C中我们如何解析呢?既然支持关键字的方式,那么是不是也可以实现默认的参数,就是我们不传会使用默认值呢?答案是支持的,我们知道解析位置参数是通过PyArg_ParseTuple,那么解析关键字参数是通过PyArg_ParseTupleAndKeywords
//函数原型
int PyArg_ParseTupleAndKeywords(PyObject *args, PyObject *kw, const char *format, char *keywords[], ...)
我们看到相比原来的PyArg_ParseTuple,多了一个kw和一个char *类型的数组,具体怎么用我们在编写代码的时候说。
#include "Python.h"
static PyObject *
f(PyObject *self, PyObject *args, PyObject *kw)
{
//我们说函数既可以通过位置参数、还可以通过关键字参数传递,那么函数的参数类型就要变成METH_VARARGS | METH_KEYWORDS
//假设我们定义了三个参数,name、age、place,这三个参数可以通过位置参数传递、也可以通过关键字参数传递
//这里我们先只使用纯英文,等到介绍到字符串的Python/C API的时候再说
char *name;
int age = -1;
char *where = "japan";
//告诉python解释器,参数的名字,注意:这里面字符串的顺序就是函数定义的参数顺序
//也是keys后面的变量顺序,其实变量名字叫什么无所谓,但是类型要和format中对应的占位符匹配,只是为了一致我们会起相同的名字
//注意结尾要有一个NULL,否则会报出段错误。
char *keys[] = {"name", "age", "place", NULL}; //这个NULL很重要
//解析参数,我们看到format中本来应该是sis的,但是中间出现了一个|
//这就表示|后面的参数是可以不填的,如果不填会使用我们上面给出的默认值
//因此这里name就是必填的,因为它在|的前面,而age和where可以不填,如果不填就用我们上面给出的默认值
//keys就是定义的参数的名字,后面把参数的指针传进去
if (!PyArg_ParseTupleAndKeywords(args, kw, "s|is", keys, &name, &age, &where)){
return NULL;
}
printf("name: %s, age: %d, place: %s
", name, age, where);
return Py_None;
}
static PyMethodDef fubuki_function[] = {
{
"f",
(PyCFunction)f,
METH_VARARGS | METH_KEYWORDS,
"this is a function named f"
},
{NULL, NULL}
};
static PyModuleDef fubuki_module = {
PyModuleDef_HEAD_INIT,
"fubuki",
"this a module named fubuki",
-1,
fubuki_function,
NULL, NULL, NULL, NULL
};
PyMODINIT_FUNC
PyInit_fubuki(void)
{
return PyModule_Create(&fubuki_module);
}
老规矩,还是编译成扩展模块。
import fubuki
try:
fubuki.f()
except TypeError as e:
print(e) # function missing required argument 'name' (pos 1)
fubuki.f("mea") # name: mea, age: -1, place: japan
fubuki.f("mea", 38) # name: mea, age: 38, place: japan
fubuki.f("mea", 38, "JAPAN") # name: mea, age: 38, place: JAPAN
以上我们便实现了支持关键字参数的函数,我们说使用PyArg_ParseTupleAndKeywords的时候,里面写上了args和kw,这表示既支持位置参数、也支持关键字参数。至于顺序就是代码中的顺序,我们看到如果参数传递的个数不正确,Python会自动提示你。
返回布尔类型和None
我们说函数都必须返回一个PyObject *,如果这个函数没有返回值,那么在Python中实际上返回的是一个None,但是我们不能返回NULL,None和NULL是两码事。在扩展函数中,如果返回NULL就表示这个函数执行的时候,不符合某个逻辑,我们需要终止掉,不能再执行下去了。这是在底层,但是在Python的层面,你需要告诉使用者为什么不能执行了,或者说底层的哪一行代码不满足条件,因此这个时候我们会在return NULL之前需要手动设置一个异常,这样在Python代码中就会报错,才知道为什么底层函数退出了。当然有时候会自动帮我们设置,比如上面的参数解析错误。
但是返回None的话,Python也提供了一个宏,我们直接写Py_RETURN_NONE;即可,表示返回一个None,当然也可以使用之前的return Py_None。如果是bool类型的话,那么就是return Py_True;和return Py_False;,比较简单,就不代码演示了。
引用计数和内存管理
下面来说一个非常关键的地方,就是引用计数和内存管理。我们目前都没有涉及到内存管理的操作,但是我们说Python中的对象都是申请在堆区的,这个是不会自动释放的。
static PyObject *
my_func1(PyObject *self, PyObject *args, PyObject *kw)
{
PyObject *s = PyUnicode_FromString("你好呀~~~");
return Py_None;
}
这个函数不需要参数,如果我们写一个死循环不停的调用这个函数,你会发现内存的占用蹭蹭的往上涨。就是因为这个PyUnicodeObject是申请在堆区的,此时内部的引用计数为1。函数执行完毕变量s被销毁了,但是s是一个指针,这个指针被销毁了是不假,但是它指向的内存并没有被销毁。
static PyObject *
my_func1(PyObject *self, PyObject *args, PyObject *kw)
{
PyObject *s = PyUnicode_FromString("你好呀~~~");
Py_DECREF(s);
return Py_None;
}
因此我们需要手动调用Py_DECREF这个宏,来将s指向的PyUnicodeObject的引用计数减1,这样引用计数就为0了。不过有一个特例,那就是当这个指针作为返回值的时候,我们不需要手动减去引用计数,因为会自动减。
static PyObject *
my_func1(PyObject *self, PyObject *args, PyObject *kw)
{
PyObject *s = PyUnicode_FromString("你好呀~~~");
//如果我们把s给返回了,那么我们就不需要调用Py_DECREF了
//因为一旦作为返回值,那么会自动减去1
//所以C中的对象是由python来管理的,准确的说应该是作为返回值的指针指向的对象是由python来管理的
return s;
}
不过这里还存在一个问题,那就是我们在C中返回的是Python传过来的
static PyObject *
my_func1(PyObject *self, PyObject *args, PyObject *kw)
{
PyObject *s = NULL;
char *keys[] = {"s", NULL};
PyArg_ParseTupleAndKeywords(args, kw, "O", keys, &s);
//传递过来一个PyObject *,然后原封不动的返回
return s;
}
显然上面s指向的内存不是在C中调用api创建的,而是Python创建然后传递过来、解析出来的,也就是说这个s在解析之后已经指向了一块合法的内存。但是内存中的对象的引用计数是没有变化的,虽说有新的变量(这里的s)指向它了,但是这个s是C中的变量不是Python中的变量,因此你可以认为它的引用计数是没有变化的。然后作为返回值返回之后,指向对象的引用计数减一。所以你会发现在Python中,创建一个变量,然后传递到my_func1中,执行完之后再进行打印就会发生段错误,因为对应的内存已经被回收了。如果能正常打印,说明在Python中这个变量的引用计数不为1,可能是小整数对象池、或者有多个变量引用,那么就创建一个大整数或者其他的变量多调用几次,因为作为返回值,每次调用引用计数都会减1。
static PyObject *
my_func1(PyObject *self, PyObject *args, PyObject *kw)
{
//假设创建一个PyListObject
PyObject *l1 = PyList_New(2);
//将l1赋值给l2,但是不好意思,这两位老铁指向的PyListObject的引用计数还是1
PyObject *l2 = l1;
return s;
}
因此我们说,如果在C中创建一个PyObject的话,那么它的引用计数只会是1,因为对象被初始化了,引用计数默认是1。至于传递,无论你在C中将创建PyObject返回的指针赋值给了多少个变量,它们指向的PyObject的引用计数都会是1。因为这些变量是C中的变量,不是Python中的。
因此我们的问题就很好解释了,我们说当一个PyObject *作为返回值的时候,它指向的对象的引用计数会减去1,那么当Python传递过来一个PyObject *指针的时候,由于它作为了返回值,因此引用计数会减1。因此当你在Python中调用扩展函数结束之后,这个变量指向的内存可能就被销毁了。如果你在Python传递过来的指针没有作为返回值,那么怎么引用计数是不会发生变化的,但是一旦作为了返回值,引用计数会自动减1,因此我们需要手动的加1。
static PyObject *
my_func1(PyObject *self, PyObject *args, PyObject *kw)
{
PyObject *s = NULL;
char *keys[] = {"s", NULL};
PyArg_ParseTupleAndKeywords(args, kw, "O", keys, &s);
//这样就没有问题了。
Py_INCREF(s);
return s;
}
因此我们可以得出如下结论:
如果在C中,创建一个PyObject *var,并且var已经指向了合法的内存,比如调用PyList_New、PyDict_New等等api返回的PyObject *,总之就是已经存在了PyObject,那么如果var没有作为返回值,我们必须手动地将var指向的对象的引用计数减1,否则这个对象就会在堆区一直待着不会被回收。可能有人问,如果PyObject *var2 = var,我将var再赋值给一个变量呢?那么只需要对一个变量进行Py_DECREF即可,当然对哪个变量都是一样的,因为在C中变量的传递不会导致引用计数的增加。如果C中创建的PyObject *作为返回值而存在了,那么会自动将指向的对象的引用计数减1,因此此时该指针指向的内存就由Python来管理了,就相当于在Python中创建了一个对象,我们不需要关心。最后关键的一点,如果C中返回的指针指向的内存是Python中创建好的,假设我们在python中创建了一个对象,然后把指针传递过来了,但是我们说这不会导致引用计数的增加,因为赋值的变量是C中的变量。如果C中用来接收参数的指针没有作为返回值,那么引用计数在扩展函数调用之前是多少、调用之后还是多少。一旦作为了返回值,我们说引用计数会自动减1,因此假设你在调用扩展函数之前引用计数是3,那么调用之后你会发现引用计数变成了2。为了防止段错误,一旦作为返回值,我们需要在返回之前手动地将引用计数加1。
C中创建的:不作为返回值,引用计数手动减1、作为返回值,不处理;Python中创建传递过来的,不作为返回值,不处理、作为返回值,引用计数手动加1。
另外关于Py_INCREF和Py_DECREF,它们要求PyObject *不可以为NULL,如果可能为NULL的话,那么建议使用Py_XINCREF和Py_XDECREF。当然虽然我们演示使用的是Py_INCREF和Py_DECREF,但是我们建议实际项目中都使用Py_XINCREF和Py_XDECREF。
小结
这次我们介绍了Python编写扩展模块的基本骨架,至于一些类型对象的API,前面已经剖析过了,所以一些API的调用可以自己去源码中查找,或者查阅官网。只不过最重要的是,我们需要先了解编写扩展所对应的流程是什么,以及函数的位置参数、关键字参数、设置异常、引用计数等等,这些都是贯穿始终的,只有先掌握这些,才能继续往下学习。
后续我们将介绍Python的内存管理。