一、基本数据类型——数字
1、布尔型
- bool型只有两个值:True和False
- 之所以将bool值归类为数字,是因为我们也习惯用1表示True,0表示False。
(1)布尔值是False的各种情况:
bool(0)
bool(None)
bool("")
bool(())
bool([])
bool({})
(2)布尔值python2与python3的区别
在Python2.7 中,True和False是两个内建(built-in)变量,内建变量和普通自定义的变量如a, b, c一样可以被重新赋值,因此我们可以把这两个变量进行任意的赋值。
在Python3.x 中,终于把这个两变量变成了关键字,也就是说再也没法给这两变量赋新的值了,从此True永远指向真对象,False指向假对象,永不分离。
2、整型
Python中的整数属于int类型,默认用十进制表示,此外也支持二进制,八进制,十六进制表示方式。
进制转换
二进制前面以‘0b’标示,八进制前面以‘0o’标示,十六进制以‘0x’标示
1 >>> bin(10) # 转换为二进制 2 '0b1010' 3 >>> oct(10) # 转换为八进制 4 '0o12' 5 >>> hex(10) # 转换为十六进制 6 '0xa'
运算
>>> 5%2 # 取余 1 >>> 16%4 0 >>> 2+3 # 加法 5 >>> 2-3 # 减法 -1 >>> 2*3 # 乘法 6 >>> 3/2 # 除法 1.5 >>> 9//2 # 取整除 4 >>> divmod(16,3) # 返回包含商和余数的元组(a // b, a % b) (5, 1) >>> 2**3 # 幂 8
3、浮点数
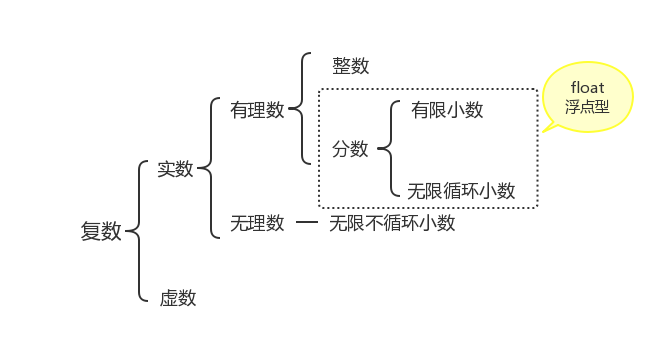
浮点数是属于有理数中某特定子集的数的数字表示,在计算机中用以近似表示任意某个实数。具体的说,这个实数由一个整数或定点数(即尾数)乘以某个基数(计算机中通常是2)的整数次幂得到,这种表示方法类似于基数为10的科学计数法。
在python中,以双精度(64)位来保存浮点数,多余的位会被截掉。
(1)关于小数不精准问题
Python默认的是17位精度,也就是小数点后16位,尽管有16位,但是这个精确度却是越往后越不准的。
首先,这个问题不是只存在在python中,其他语言也有同样的问题
其次,小数不精准是因为在转换成二进制的过程中会出现无限循环的情况,在约省的时候就会出现偏差。
比如:11.2的小数部分0.2转换为2进制则是无限循环的00110011001100110011...
单精度在存储的时候用23bit来存放这个尾数部分(前面9比特存储指数和符号);同样0.6也是无限循环的;
(2)计算需要使用更高的精度(超过16位小数)情况
#借助decimal模块的“getcontext“和“Decimal“ 方法
>>> a = 3.141592653513651054608317828332
>>> a
3.141592653513651
>>> from decimal import *
>>> getcontext()
Context(prec=50, rounding=ROUND_HALF_EVEN, Emin=-999999, Emax=999999, capitals=1, clamp=0, flags=[FloatOperation], traps=[InvalidOperation, DivisionByZero, Overflow])
>>> getcontext().prec = 50
>>> a = Decimal(1)/Decimal(3)#注,在分数计算中结果正确,如果直接定义超长精度小数会不准确
>>> a
Decimal('0.33333333333333333333333333333333333333333333333333')
>>> a = '3.141592653513651054608317828332'
>>> Decimal(a)
Decimal('3.141592653513651054608317828332')
不推荐:字符串格式化方式,可以显示,但是计算和直接定义都不准确,后面的数字没有意义。
>>> a = ("%.30f" % (1.0/3))
>>> a
'0.333333333333333314829616256247'
4、复数
复数complex是由实数和虚数组成的要了解复数,其实关于复数还需要先了解虚数。
虚数(就是虚假不实的数):平方为复数的数叫做虚数。
复数是指能写成如下形式的数a+bi,这里a和b是实数,i是虚数单位(即-1开根)。在复数a+bi中,a称为复数的实部,b称为复数的虚部(虚数是指平方为负数的数),i称为虚数单位。
当虚部等于零时,这个复数就是实数;当虚部不等于零时,这个复数称为虚数。
注,虚数部分的字母j大小写都可以。
二、基本数据类型——字符串
1、字符串定义
字符串是一个有序的字符的集合,用于存储和表示基本的文本信息,' '或'' ''或''' '''中间包含的内容称之为字符串。
2、字符串特性
- 字符串是不可变类型。
- 按照从左到右的顺序定义字符集合,下标从0开始顺序访问,有序。
- 字符串的单引号和双引号都无法取消特殊字符的含义,如果想让引号内所有字符均取消特殊意义,在引号前面加r,如name=r'l hf'
- unicode字符串与r连用必需在r前面,如name=ur'l hf'
3、字符串操作
字符串格式化(format)
''' 1、使用位置参数 位置参数不受顺序约束,且可以为{},参数索引从0开始,format里填写{}对应的参数值。 ''' >>> msg = "my name is {}, and age is {}" >>> msg.format("hqs",22) 'my name is hqs, and age is 22' >>> msg = "my name is {1}, and age is {0}" >>> msg.format("hqs",23) 'my name is 23, and age is hqs' # 传入位置参数列表可用 *列表 的形式 >>> li = ['lary',18] >>> 'my name is {} , age {}'.format(*li) 'my name is lary , age 18' # 使用索引 >>> li = ['larry',12] >>> 'my name is {0[0]}, age {0[1]}'.format(li) 'my name is larry, age 12' ''' 2、使用关键字参数 关键字参数值要对得上,可用字典当关键字参数传入值,字典前加**即可 ''' >>> hash = {'name':'john' , 'age': 23} >>> msg = 'my name is {name}, and age is {age}' >>> msg.format(**hash) 'my name is john,and age is 23' >>> msg.format(name="hqs",age=13) 'my name is hqs,and age is 13' >>> msg.format(age = 33, name = "zr") 'my name is zr, and age is 33' ''' 3、填充与格式化 :[填充字符][对齐方式 <^>][宽度] ''' >>> '{0:*<10}'.format(10) # 左对齐 '10********' >>> '{0:*<10}'.format("hqs") # 左对齐 'hqs*******' >>> '{0:*^10}'.format("hqs") # 居中对齐 '***hqs****' >>> '{0:*>10}'.format(10) # 右对齐 '********10' ''' 4、精度与进制 ''' >>> '{0:.2f}'.format(1/3) # 浮点数 '0.33' >>> '{0:b}'.format(18) # 二进制 '10010' >>> '{0:o}'.format(18) # 八进制 '22' >>> '{0:x}'.format(18) # 十六进制 '12' >>> '{:,}'.format(13111313341313) # 千分位格式化 '13,111,313,341,313'
常用操作
#索引 s = 'hello' >>> s[1] 'e' >>> s[-1] 'o' >>> s.index('e') 1 #查找 >>> s.find('e') 1 >>> s.find('i') -1 #移除空白 s = ' hello,world! ' s.strip() s.lstrip() s.rstrip() s2 = '***hello,world!***' s2.strip('*') #长度 >>> s = 'hello,world' >>> len(s) 11 #替换 >>> s = 'hello world' >>> s.replace('h','H') 'Hello world' >>> s2 = 'hi,how are you?' >>> s2.replace('h','H') 'Hi,How are you?' #切片 >>> s = 'abcdefghigklmn' >>> s[0:7] 'abcdefg' >>> s[7:14] 'higklmn' >>> s[:7] 'abcdefg' >>> s[7:] 'higklmn' >>> s[:] 'abcdefghigklmn' >>> s[0:7:2] 'aceg' >>> s[7:14:3] 'hkn' >>> s[::2] 'acegikm' >>> s[::-1] 'nmlkgihgfedcba'
首尾操作及统计字符
1 >>> name = "HuangQiuShi" 2 >>> name.capitalize() # 首字母大写 3 'Huangqiushi' 4 >>> name.endswith("Li") # 判断字符串是否以 Li结尾 5 False 6 >>> name.endswith("hi") # 判断字符串是否以 hi结尾 7 True 8 9 >>> name.center(50,'-') # 字符串居中显示 10 '-------------------HuangQiuShi--------------------' 11 >>> name.rjust(50,'-') 12 '---------------------------------------HuangQiuShi' 13 >>> name.ljust(50,'-') 14 'HuangQiuShi---------------------------------------' 15 16 >>> name.count("shi") # 统计'shi'出现次数 17 0 18 >>> name.count("i") 19 2
zfill(width)方法: 返回指定长度的字符串,原字符串右对齐,前面填充0
width --指定字符串的长度。原字符串右对齐,前面填充0
>>> str = "example showing how to use zfill" >>> print(str.zfill(20)) example showing how to use zfill >>> print(str.zfill(40)) 00000000example showing how to use zfill >>> print(str.zfill(50)) 000000000000000000example showing how to use zfill
三、基本数据类型——列表
定义列表:[]内以逗号分隔,按照索引,存放各种数据类型,每个位置代表一个元素。
1、列表特性
1.可存放多个值
2.按照从左到右的顺序定义列表元素,下标从0开始顺序访问,有序
3.可修改指定索引位置对应的值,可变
2、列表操作
创建列表
# 列表创建(把逗号分隔的不同的数据项使用方括号括起来即可) list_test = ['阿福','收税','snake']
切片:取多个元素
>>> names = ["Alex","Tenglan","Eric","Rain","Tom","Amy"] >>> names[1:4] #取下标1至下标4之间的数字,包括1,不包括4 ['Tenglan', 'Eric', 'Rain'] >>> names[1:-1] #取下标1至-1的值,不包括-1 ['Tenglan', 'Eric', 'Rain', 'Tom'] >>> names[0:3] ['Alex', 'Tenglan', 'Eric'] >>> names[:3] #如果是从头开始取,0可以忽略,跟上句效果一样 ['Alex', 'Tenglan', 'Eric'] >>> names[3:] #如果想取最后一个,必须不能写-1,只能这么写 ['Rain', 'Tom', 'Amy'] >>> names[3:-1] #这样-1就不会被包含了 ['Rain', 'Tom'] >>> names[0::2] #后面的2是代表,每隔一个元素,就取一个 ['Alex', 'Eric', 'Tom'] >>> names[::2] #和上句效果一样 ['Alex', 'Eric', 'Tom']
追加、插入
>>> list_test.append(2017) >>> list_test ['阿福', '收税', 'snake', 2017] >>> list_test.insert(2,"强行从snake前面插入") >>> list_test ['阿福', '收税', '强行从snake前面插入', 'snake', 2017] >>> list_test.insert(0,"强行插入最前") >>> list_test ['强行插入最前', '阿福', '收税', '强行从snake前面插入', 'snake', 2017]
修改
>>> list_test = ['强行插入最前', '阿福', '收税', '强行从snake前面插入', 'snake', 2017] >>> list_test[2] = "换了一个人" >>> list_test ['强行插入最前', '阿福', '换了一个人', '强行从snake前面插入', 'snake', 2017]
删除
# 删除指定位置元素 >>> del list_test[2] >>> list_test ['强行插入最前', '阿福', '强行从snake前面插入', 'snake', 2017] # 删除指定元素 >>> list_test.remove("snake") >>> list_test ['强行插入最前', '阿福', '强行从snake前面插入', 2017] # 删除列表最后一个值 >>> list_test.pop() 2017 >>> list_test ['强行插入最前', '阿福', '强行从snake前面插入']
扩展
>>> b = [1,3,"asdad"] >>> list_test.extend(b) >>> list_test ['强行插入最前', '阿福', '强行从snake前面插入', 1, 3, 'asdad']
拷贝
>>> list_test_copy = list_test.copy() >>> list_test_copy ['强行插入最前', '阿福', '强行从snake前面插入', 1, 3, 'asdad']
统计
>>> list_test.append("阿福") >>> list_test.count("阿福") 2 >>> list_test ['强行插入最前', '阿福', '强行从snake前面插入', 1, 3, 'asdad', '阿福']
排序&翻转
>>> list_test.sort() # 不同数据类型不能一起排序 Traceback (most recent call last): File "<input>", line 1, in <module> TypeError: '<' not supported between instances of 'int' and 'str' >>> list_test[-3] = '3' # 修改为字符串 >>> list_test[-4] = '1' >>> list_test ['强行从snake前面插入', '强行插入最前', '阿福', '1', '3', 'asdad', '阿福'] >>> list_test.sort() >>> list_test ['1', '3', 'asdad', '强行从snake前面插入', '强行插入最前', '阿福', '阿福'] >>> list_test.reverse() # 翻转 >>> list_test ['阿福', '阿福', '强行插入最前', '强行从snake前面插入', 'asdad', '3', '1']
获取下标
>>> list_test ['阿福', '阿福', '强行插入最前', '强行从snake前面插入', 'asdad', '3', '1'] >>> list_test.index("阿福") 0 >>> list_test.index("asdad") 4