Hadoop是一个可以通过相对简单编程模型实现跨多台计算机集群分布式处理大型数据集的框架。它不是依赖于高额成本的硬件可靠性来提供高可用性,Hadoop的设计能从单个服务器扩展到数千台机器,每个机器提供本地计算和存储。即使每个计算机都可能发生故障,但是hadoop本身具备检测和处理应用层的故障,因此在计算机群集中保证高度可用的服务。
在Centos 7 安装Hadoop 3.1.0的详细步骤如下:
一、安装Hadoop之前,首先保证配置好Java环境。
Hadoop运行需要Java环境,首先确认机器上已经安装JDK及其版本,如果没安装则安装。这里使用JDK 1.8版本。
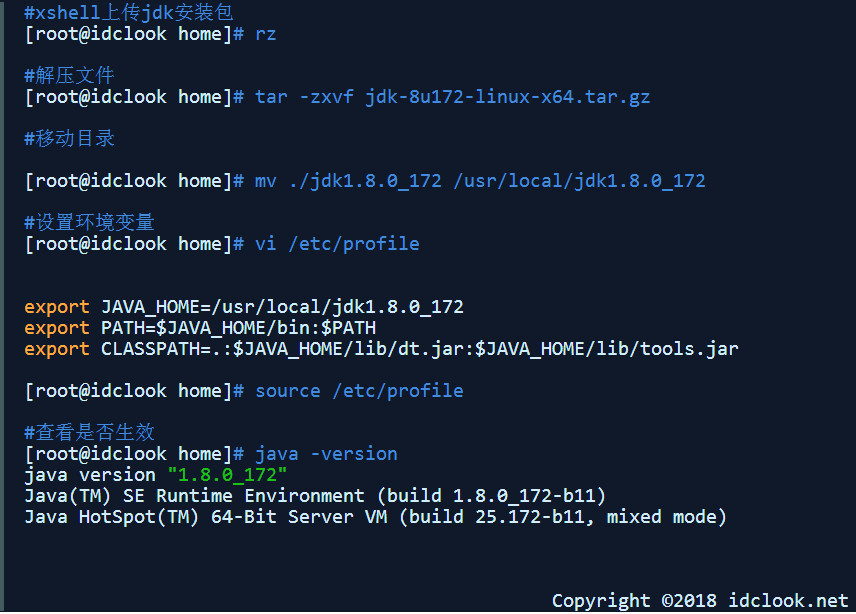
二、安装Hadoop
在官网下载对应Hadoop版本,http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.1.0/hadoop-3.1.0.tar.gz
#设置 Hadoop 环境变量 [root@idclook hadoop]# vi hadoop-env.sh export JAVA_HOME=/usr/local/jdk1.8.0_172 export PATH=$JAVA_HOME/bin:$PATH export HADOOP_CLASSPATH=$JAVA_HOME/lib/tools.jar #编辑/etc/profile #/etc/profile [root@idclook etc]# vi profile # Hadoop path export HADOOP_HOME=/usr/local/hadoop3.1.0 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin [root@idclook etc]# source /etc/profile
#查看hadoop版本,验证是否安装成功 [root@idclook etc]# hadoop version Hadoop 3.1.0 Source code repository https://github.com/apache/hadoop -r 16b70619a24cdcf5d3b0fcf4b58ca77238ccbe6d Compiled by centos on 2018-03-30T00:00Z Compiled with protoc 2.5.0 From source with checksum 14182d20c972b3e2105580a1ad6990 This command was run using /usr/local/hadoop3.1.0/share/hadoop/common/hadoop-common-3.1.0.jar
至此,已经获取一个Hadoop基础环境!