先来看看dom4j中相应XML的DOM树建立的继承关系
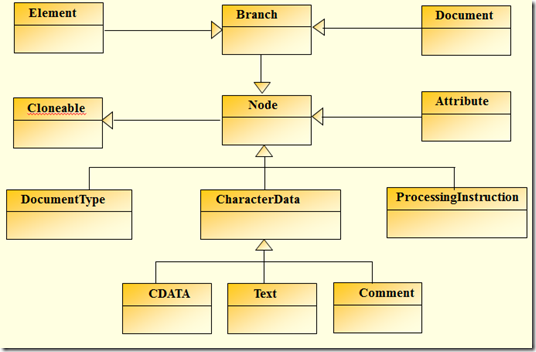
针对于XML标准定义。相应于图2-1列出的内容,dom4j提供了下面实现:
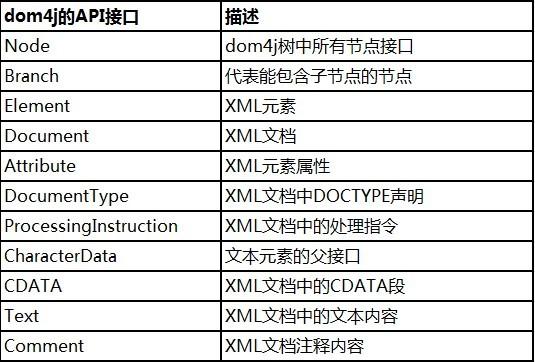
以下给出一个详细事例:
package com.iboxpay.settlement.gateway.common.util;
import java.io.IOException;
import java.io.StringReader;
import java.io.StringWriter;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import com.iboxpay.settlement.gateway.ccb.Constant;
import com.iboxpay.settlement.gateway.common.exception.PackMessageException;
import com.iboxpay.settlement.gateway.common.exception.ParseMessageException;
/**
* DOM4j工具类
* @author caolipeng
*/
public class DomUtil {
/**
* 加入孩子节点元素
* @param parent 父节点
* @param childName 孩子节点名称
* @param childValue 孩子节点值
* @return 新增节点
*/
public static Element addChild(Element parent, String childName,
String childValue) {
Element child = parent.addElement(childName);//加入节点元素
child.setText(childValue == null ?
"" : childValue); //为元素设值
return child;
}
/**
* DOM4j的Document对象转为XML报文串
* @param document
* @param charset
* @return 经过解析后的xml字符串
*/
public static String documentToString(Document document,String charset) {
StringWriter stringWriter = new StringWriter();
OutputFormat format = OutputFormat.createPrettyPrint();//获得格式化输出流
format.setEncoding(charset);//设置字符集,默觉得UTF-8
XMLWriter xmlWriter = new XMLWriter(stringWriter, format);//写文件流
try {
xmlWriter.write(document);
xmlWriter.flush();
xmlWriter.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
return stringWriter.toString();
}
/**
* 去掉声明头的(即<?xml...?>去掉)
* @param document
* @param charset
* @return
*/
public static String documentToStringNoDeclaredHeader(Document document,String charset) {
String xml = documentToString(document, charset);
return xml.replaceFirst("\s*<[^<>]+>\s*", "");
}
/**
* 解析XML为Document对象
* @param xml 被解析的XMl
* @return Document
* @throws ParseMessageException
*/
public final static Element parseXml(String xml)throws ParseMessageException{
StringReader sr = new StringReader(xml);
SAXReader saxReader = new SAXReader();
Document document;
try {
document = saxReader.read(sr);
} catch (DocumentException e) {
throw new ParseMessageException(e);
}
Element rootElement = document.getRootElement();
return rootElement;
}
public final static String getText(Element e, String tag){
Element _e = e.element(tag);
if(_e != null)
return _e.getText();
else
return null;
}
public final static String getTextTrim(Element e, String tag){
Element _e = e.element(tag);
if(_e != null)
return _e.getTextTrim();
else
return null;
}
/**
* 获取节点值.节点必须不能为空,否则抛错
* @param parent
* @param tag
* @return
* @throws ParseMessageException
*/
public final static String getTextTrimNotNull(Element parent, String tag) throws ParseMessageException{
Element e = parent.element(tag);
if(e == null)
throw new ParseMessageException(parent.getName() + " -> " + tag + " 节点为空.");
else
return e.getTextTrim();
}
/**
* 节点必须不能为空,否则抛错
* @param parent
* @param tag
* @return
* @throws ParseMessageException
*/
public final static Element elementNotNull(Element parent, String tag) throws ParseMessageException{
Element e = parent.element(tag);
if(e == null)
throw new ParseMessageException(parent.getName() + " -> " + tag + " 节点为空.");
else
return e;
}
public static void main(String[] args) throws PackMessageException, ParseMessageException {
Document document = DocumentHelper.createDocument();
document.setXMLEncoding("GB2312");
Element root = document.addElement("TX");
DomUtil.addChild(root, "REQUEST_SN", "bankBatchSeqId");
DomUtil.addChild(root, "CUST_ID", "cust_id");
DomUtil.addChild(root, "USER_ID", "user_id");
DomUtil.addChild(root, "PASSWORD", "password");
DomUtil.addChild(root, "TX_CODE", "txCode");
DomUtil.addChild(root, "LANGUAGE", "CN");
Element tx_info = root.addElement(Constant.TX_INFO);
DomUtil.addChild(tx_info, Constant.REQUEST_SN1, "request_sn1");
String xml = DomUtil.documentToStringNoDeclaredHeader(root.getDocument(), "GBK");
System.out.println(xml);
root = parseXml(xml);
System.out.println(root.element("TX_INFO").elementText("REQUEST_SN1"));
}
}
主函数測试结果为:
<TX>
<REQUEST_SN>bankBatchSeqId</REQUEST_SN>
<CUST_ID>cust_id</CUST_ID>
<USER_ID>user_id</USER_ID>
<PASSWORD>password</PASSWORD>
<TX_CODE>txCode</TX_CODE>
<LANGUAGE>CN</LANGUAGE>
<TX_INFO>
<REQUEST_SN1>request_sn1</REQUEST_SN1>
</TX_INFO>
</TX>
request_sn1
博客參考文献:http://www.cnblogs.com/macula/archive/2011/07/27/2118003.html