

要对词去做编码,词与词之间是有关联的,对词组变成一些向量。对于图片是由RGB三个颜色通道组成,像素点是直接由这三个通道表示,颜色的差异度是可以通过RGB三个颜色的差异值体现出来。而文本不一样,它是一些更高层的数据。它是人造出来的一些token。我们希望词在空间当中,显示为一个分布状态。想实现一个单词在一种语言中的分布,与另一种语言中的分布相同。

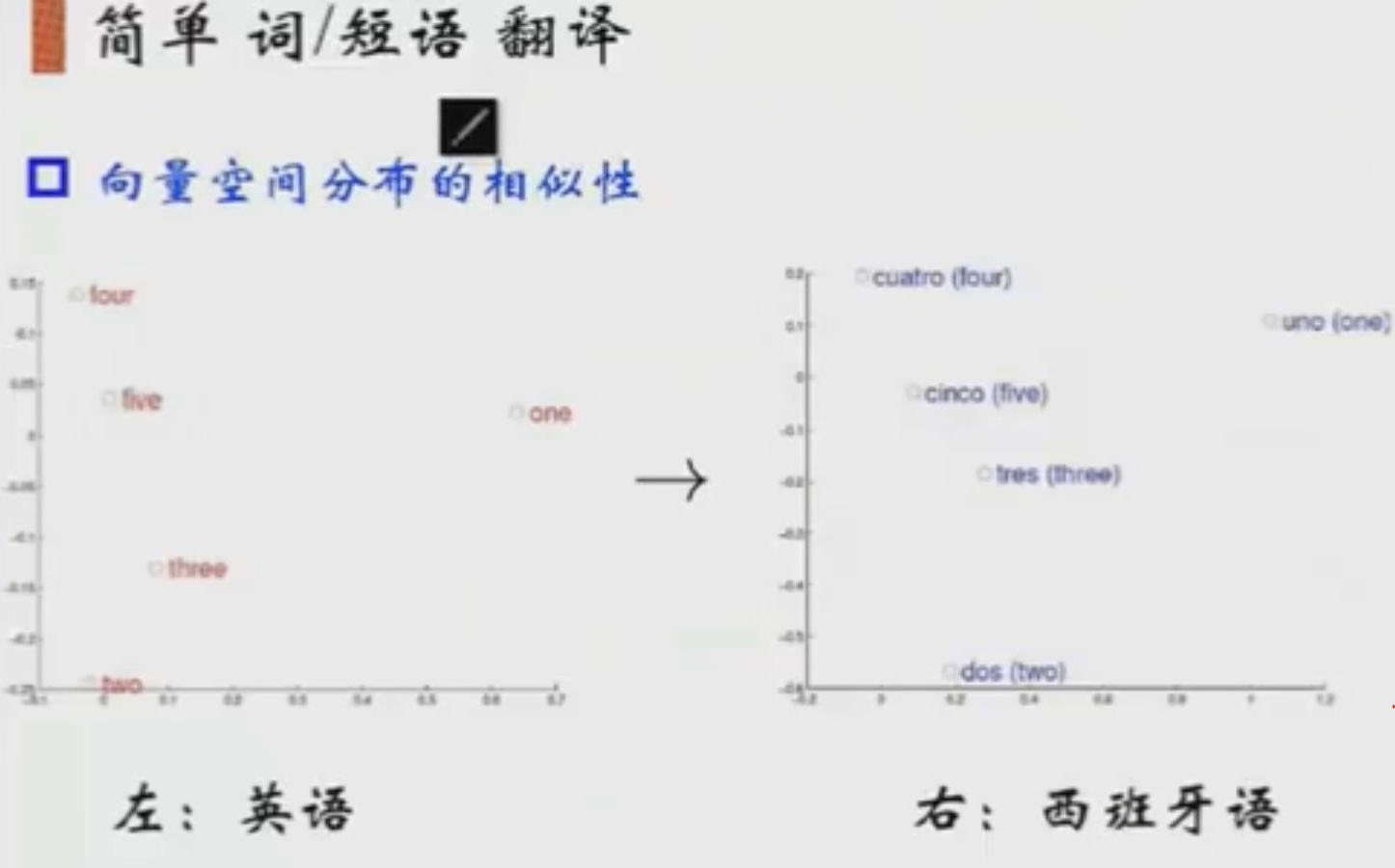
要实现词在空间分布,就要把词映射到空间当中。并且把词与词之间的关系用距离表示,但这样也会出现一些问题。


one-hot:给每个词一个下标,有多少个词,我就开多大的向量空间,并只有这个词出现的位置的对应下标设为1,其他都设为0。one-hot的好处:它可以产生出句子的离散表示。


Bag of wo'r'ds:把句子表示为一个向量,把记录词出现的次数,即counter。每句话的词出现几次就记录几次,likes出现了2次,记录2.但每个词在不同文章中的意义不一样,所以一堆bag of words变为带有权重的词。
Binary weighting:记录词出现的次数,在短文本中相似性,且词比较集中的时候用的比较多。
在文档中出现同样的词, 他们的顺序没有被考虑到。导致john liks marry,和marry likes John是一样的。Bi-gram就是把2个词做出的一个词建索引。虽然它可以保证词的顺序,但词表会膨胀很快。


语言模型:利用贝叶斯公式,并找出词之间的关系的概率。

离散表示的问题:无论是Bag of wrods,Bi-gram等都没有办法去权衡词向量和词向量的关系。如酒店、宾馆、旅社,如果没有背景知识,就很难捕捉文本的含义。

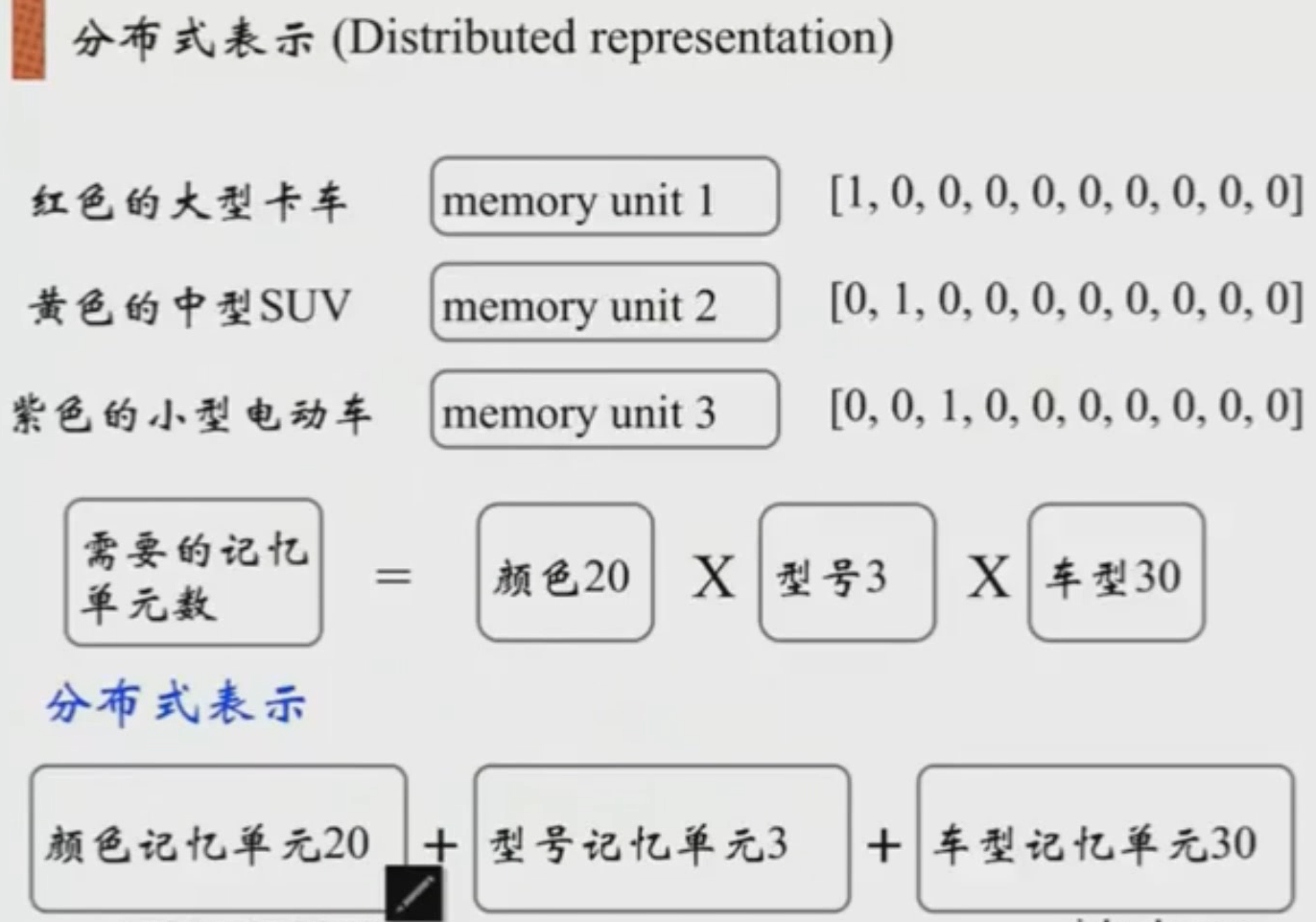
离散表示的每个词只在它自己的轴上表示,而分布式表示是把词分散到每个轴上去表示了,即每个位置上都有连续的值。像离散表示把每个词组或句子当初一个独立的短语或句子,那么这个短语或句子只能占独立的空间。但如果这些短语或句子是有模式的,如红色的大型卡车,利用pattern,把这句子分为红色、大型、卡车,那么我们所需要存储的空间就可以压缩到三维,分别为颜色维度,型号维度,车型维度,他们之间是可以做组合的。这样只要维度分为3个维度,颜色、型号和车型。

基于这样一个概念,我们需要构建一个方法来完成这个词的表示。找到这个词附近的其他词来表示这个词。如同银行给你贷款,就会看看你朋友圈是什么层次的人,根据你的朋友给你定贷款额度。
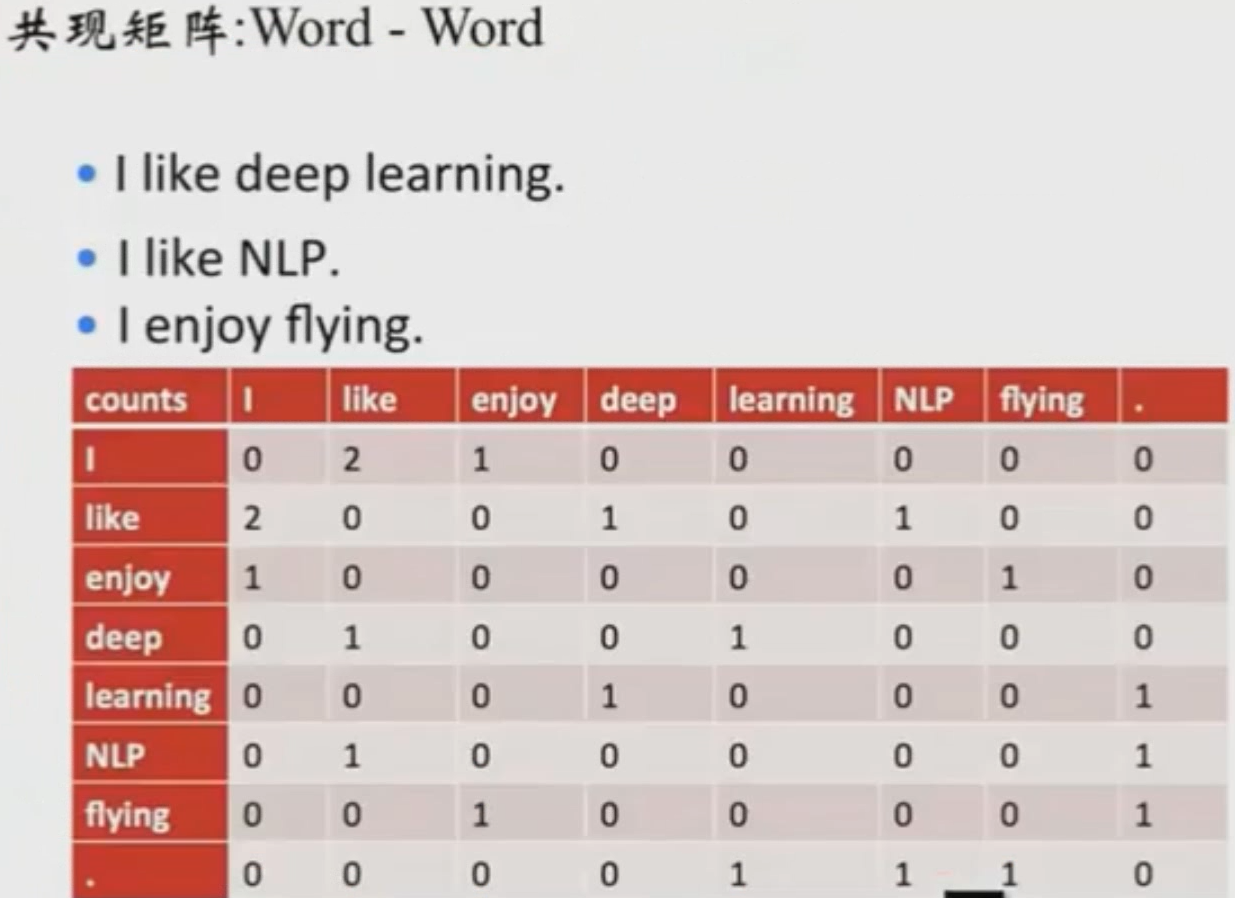
共现矩阵:建立一个共现矩阵,把单词出现的次数记录下来。


SVD降维:分成3个矩阵,
