bugku之秋名山老司机
题目连接:http://123.206.87.240:8002/qiumingshan/
一点进去是这样的

请在两秒内计算这个式子。。。怎么可能算的出来
查看源码,无果。。
burp抓包 无果
再次点进这个题目发现式子会变,于是多刷新几次,出现了这个界面

需要post这个式子的值,但是这个式子我不会算啊,怎么办?百度吧。。
百度后知道这个式子需要用python写一个脚本,但是看了他们写的脚本发现自己看不到,于是去刷一刷python 因为本来就不怎么熟悉 这里说下这次看了python学到的知识:
1.首先发现很烦的一件事就是python3很烦 print 后需要加("")而python2只需要print”“
2.算了直接上图

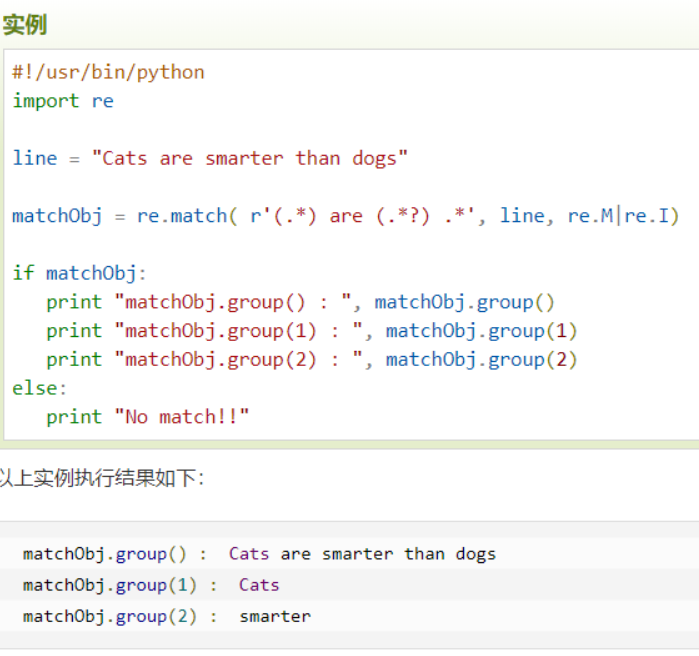
import re # import 是导入模块 相当于就是导入函数库 导入模块过后就可以用相应的模块里的函数 这里的re模块是正则表达式 用于匹配字符串当中的一定字符 但是说匹配这里却用来提取字符
import requests #导入requests模块 请求模块 这个模块还有很多需要我学习
import requests #导入requests模块 请求模块 这个模块还有很多需要我学习
s = requests.Session() # 用s存session session和cookie 都用于身份识别 session本义为对话 这里我自己暂时理解为 把这次对话保存起来并取名s 相当于记录身份
r = s.get("
 http://120.24.86.145:8002/qiumingshan/") #用此身份请求并url
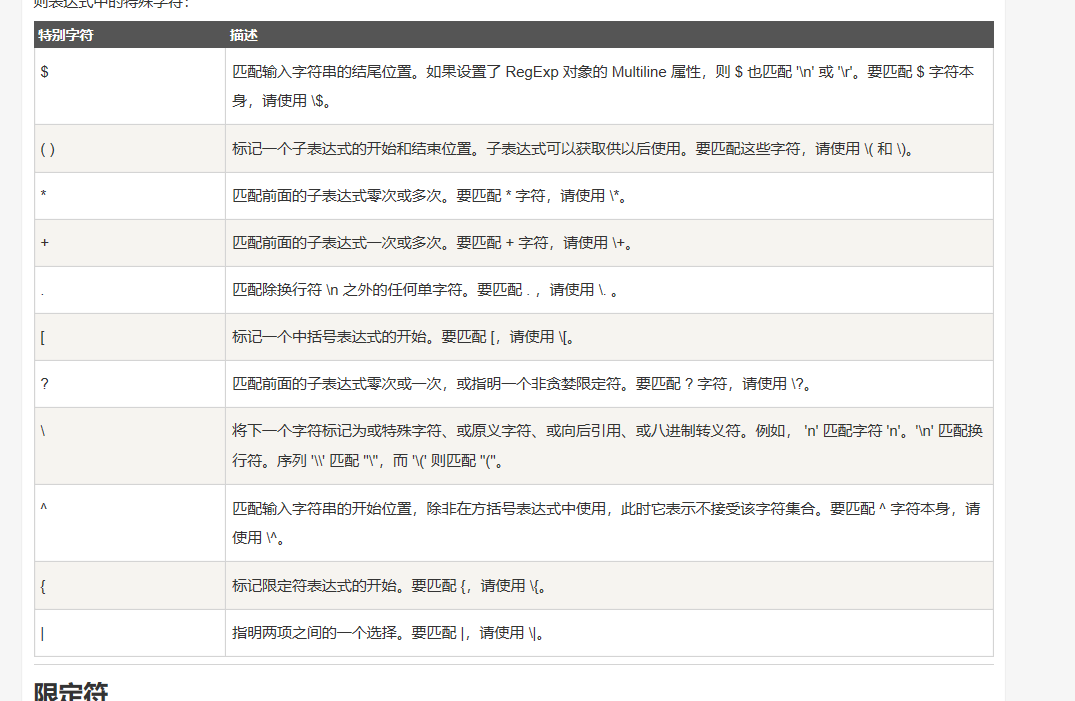
http://120.24.86.145:8002/qiumingshan/") #用此身份请求并urlsearchObj = re.search(r'^<div>(.*)=?;</div>$', r.text, re.M | re.S) #search 是扫描整个字符串并返回成功的匹配值 如果没有匹配则返回none 正则re.search(要匹配的字符,被扫描的字符,功能选择), 这里用这个函数实则是在提取字符,首先看要匹配的字符是这样的 r'^<div>(.*)=?;</div>$',这里的r我实在没有查到是什么意思我看了好几个有些没有这个r,^代表开始,$代表结束,这里则表是从<div>开始到</div>结束,而中间的(.*)这里的.代表任意一个字符加一个*构成.*就多次的任意字符 然后?是?有特殊含义需要匹配?要在前面加一个,这里的=?是源代码中本来就有的,这里打括号是进行分组,第一个()就是第一组第二个()就是第二组(这是我自己的理解) ,r'^<div>(.*)=?;</div>$'表示<div></div>中的所有字符,然后再与r.text相匹配,相当于提取,后面我会带上图上面有一些字符的含义与某两个网站,还有分组。
d = {
"value": eval(searchObj.group(1)) #eval函数是计算值
}
r = s.post("
http://120.24.86.145:8002/qiumingshan/", data=d) #post传值print(r.text) #输出结果

https://blog.csdn.net/github_36362235/article/details/53302787
废话:今天感觉没有学到撒子东西,看了小迪的视频搭环境本来想自己搭一个环境,但是太麻烦所以这个周周六再搭吧,今天安装request用了很久的时间,学习那几个正则也用了很久,希望这些知识不要忘记。明天三节课但是还是要抽出时间来学技术,4.25一定要去面试道格,虽然不一定去的到但是还是尝试,4.27c语言考试,明天要看C语言题库还有复习高数后天要考试,所以明天学技术的时间可能有点少。这个键盘老是掉键真的好烦。 我知道我自己现在的博客还没人看,我以后会多多努力,总有一天我也会像柠檬师傅一样的加油,你是最帮的!
杨艺小猪,以后你一定要及时看我的博客啊,我写的每一篇你都要看,成为我的粉丝吧哈哈哈。