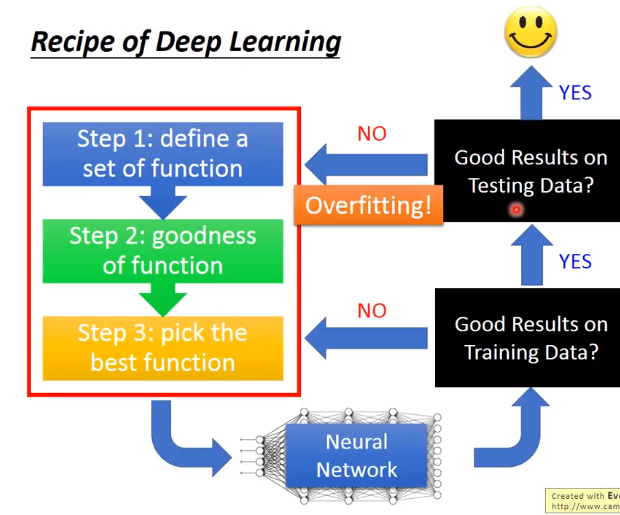
1。 一般的机器学习方法不会在train好的模型上检查training data的结果,因为DNN在training data上都没有办法获得很好的正确率,
所以要先回头看一下要对模型做什么修改,才能使得在training set上取得比较好的正确率。
2。 在training set获得好的结果,但在testing set上获得不好的结果,这个才是overfitting,并不是说在training set获得好的结果就是overfitting。
这个时候要回去做一些工作解决overfitting这个问题。解决overfitting的同时会使得结果在training set上的结果性能变差,这个时候要回到注意1上。
上图中,56层的模型对比20层的模型,无论是在training set还是testing set上表现都要差,这个事情并不是Overfitting的原因,而是没有训练好(没训练好的原因:局部最小值,鞍点,平原)。
但也不是 underfitting,模型的参数不够多,没有能力解决某一个问题。
有意思的观点:56层的模型肯定要比20层的好,原因很简单,如果我56层前面20层和下面的20层一样,后面36层啥事也不做,至少来说他的性能要和下面的一样,因此结论就是56层的模型是没有训练好
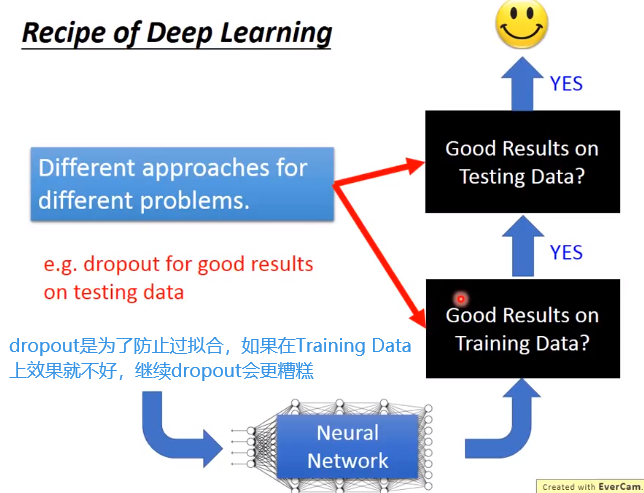
不同问题需要对应的方法来解决
Training data性能差
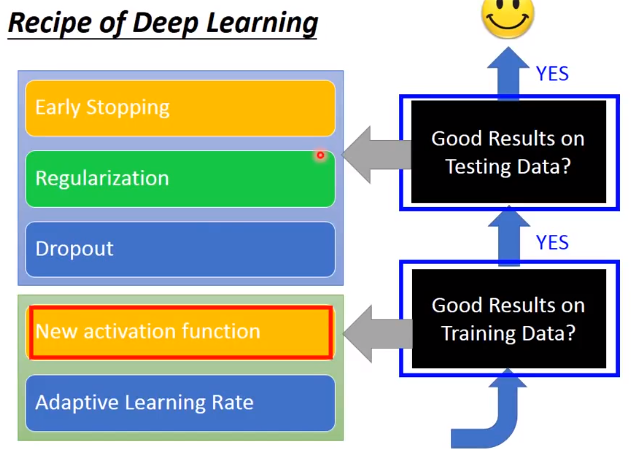
激活函数改进
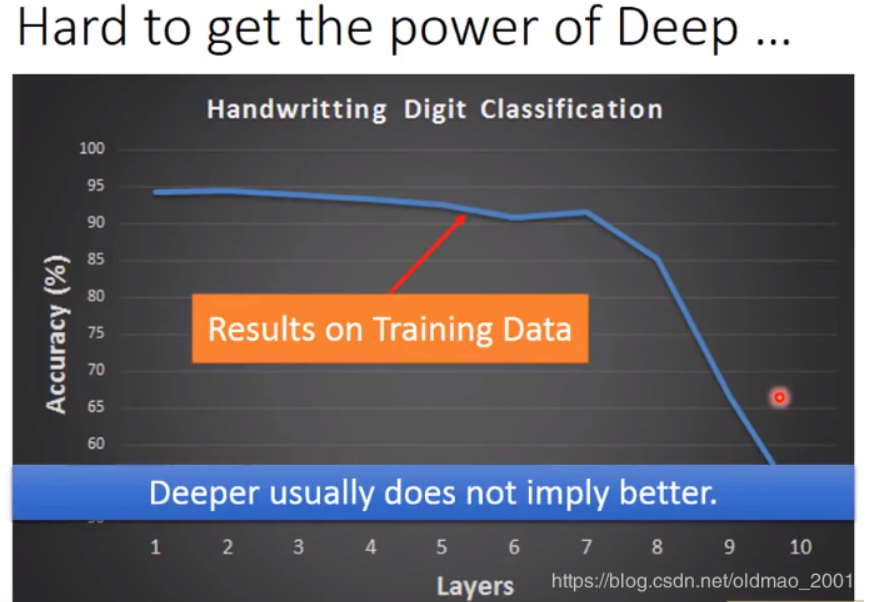
上面这个例子不是overfitting,如果是overfitting那么在training set获得好的结果,但在testing set上获得不好的结果。上面的曲线是training data的,在第七层的时候准确率就坏掉
那么为什么会这样呢?


首先用w变化对C的变化来表示derivatives

每通过一次sigmoid,output的变化都在衰减
因此,对input改变,其实对output(C)的影响很小
梯度消失:在输入层附近梯度小,在输出层梯度大,当参数还没有更新多少时,在输出层已经收敛了,这是激活函数sigmoidsigmoid对值压缩的问题。
也就是一个比较大的input进去,出来的output比较小,所以最后对total loss的影响比较小,趋于收敛。
Relu

z代表input
3.等同于无穷多的sigmoid(bias 不同)叠加的结果
那么如何vanish(消除) gradient problem
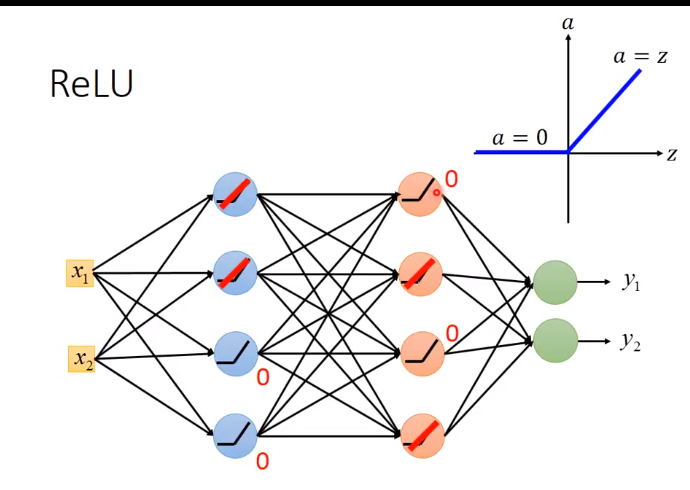
0可以从network 拿掉
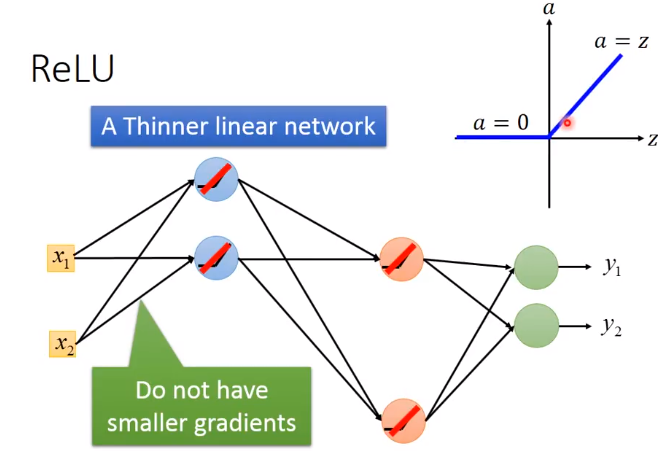
而之前说梯度递减也是因为sigmoid的衰减效果,而我们现在用ReLU它本身不会对增量进行递减,因为现在凡是在网络中work的神经元,其输出都等于其输入,相当于线性函数y=x。
问题:如果网络都用ReLU了,网络变成了线性的了?那NN的效果不会变得很差吗?这与我们使用深层网络的初衷不是违背了吗?
答:其实使用ReLU的NN整体还是非线性的。当每个神经元的操作域(operation region)是想相同的时,它是线性的。即当你对input只做小小的改变,不改变神经元的操作域,那NN就是线性的;
但如果对input做比较大的改变,改变了神经元的操作域,网络的架构也会变化,这样NN就是非线性的了。
另外一个问题:ReLU不能微分呀?怎么做梯度下降呀?
答:当x>0时,ReLU微分就是1,当x<0时,ReLU微分就是0。而x的值一般不太可能恰好是0,所以不在x=0时的微分值也没问题。
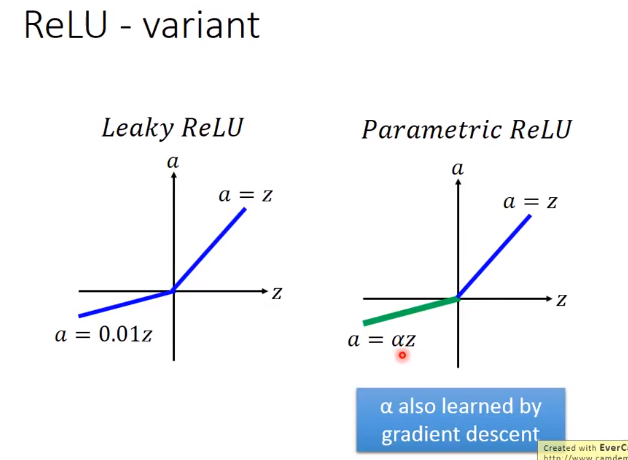
很简单,防止小于零的输入求导后为0。右边的进一步把0.01参数变成一个超参数。
Maxout

解释Relu 是Maxout的一个特例
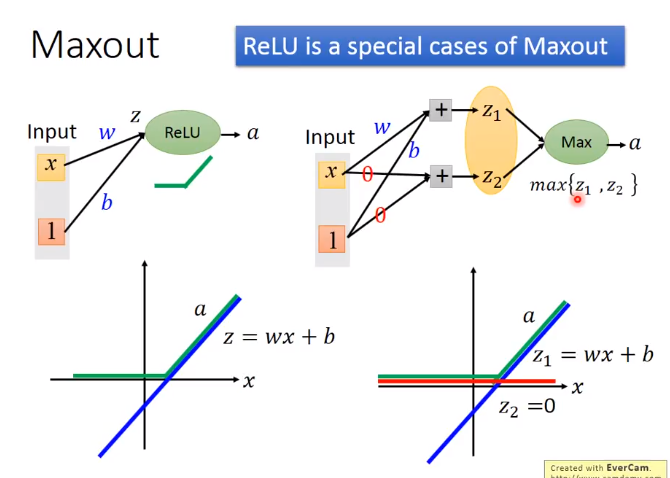
Maxout还有其他功能
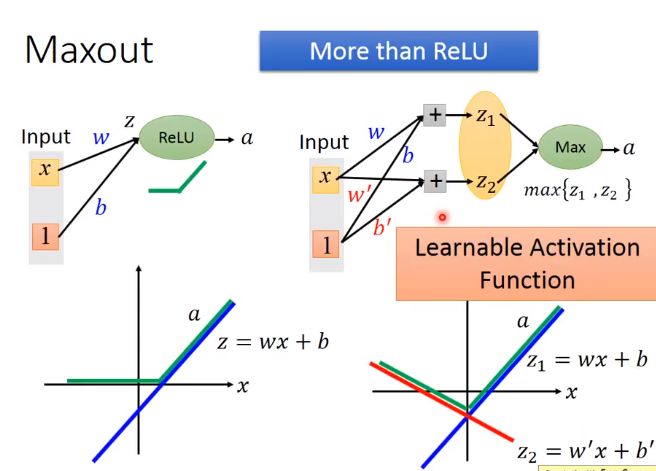

piecewise linear convex function:分段线性凸函数
Training Maxout
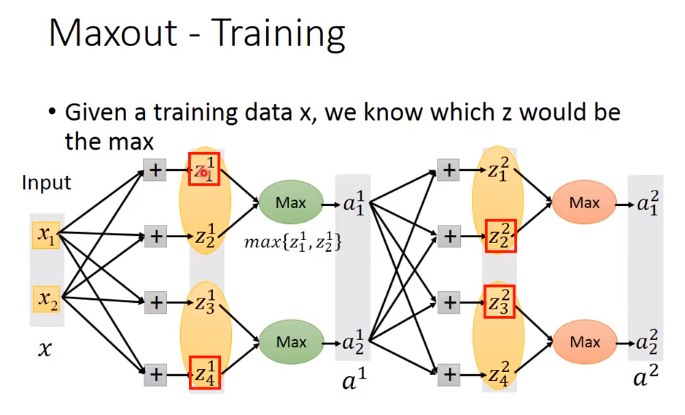
红色框中是group中大的那个,那么这个网络可以变成:
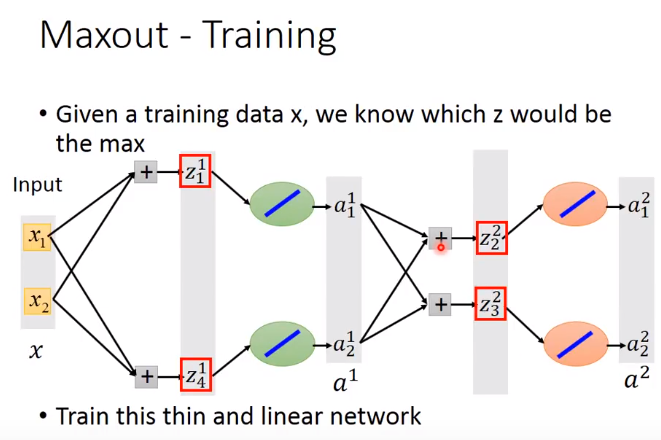
因为小的element是变为0,对网络无影响,可以去掉。这里也是一个thin and linear network。
那些没有被框起来的element是不是就没有办法被吹到?
不会,不同的输入的时候,group中的最大值是不一样的,我们的train set有很多笔data,每次不同的data输入,网络的结构都不一样,每个element都会被train到
Adagrad的优化RMSProp
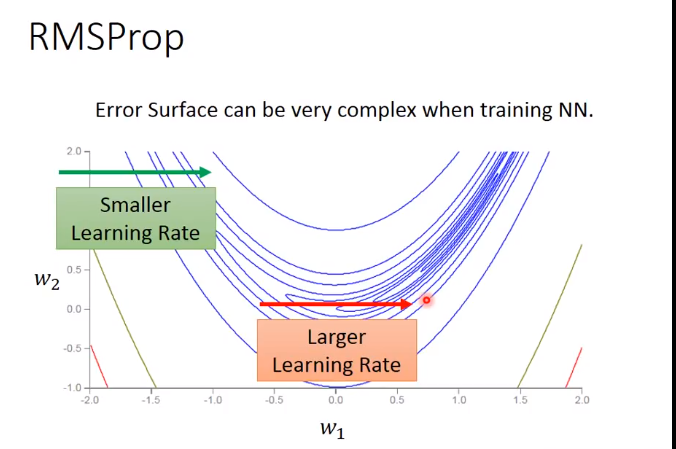

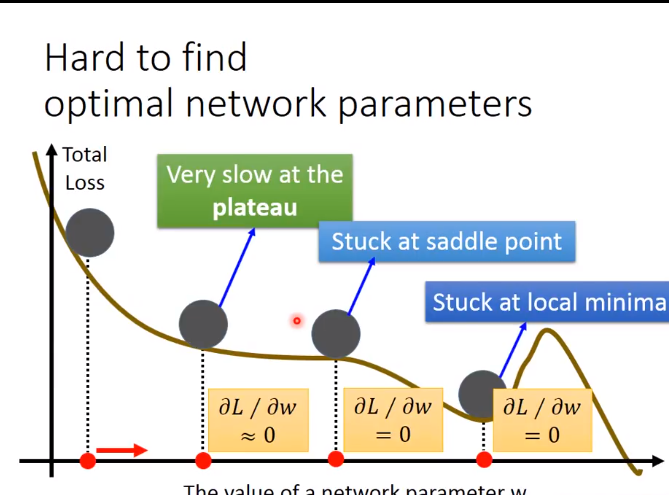
在复杂网络里面出现局部minima的几率很低,因为无论是局部还是全局的minima,在这个点上的各个dimension的偏导都为0,复杂网络中的dimension这么多,
所以同时出现这个情况的几率比中六合彩还低,所以一旦出现,就是全局minima
Momentum 推进力
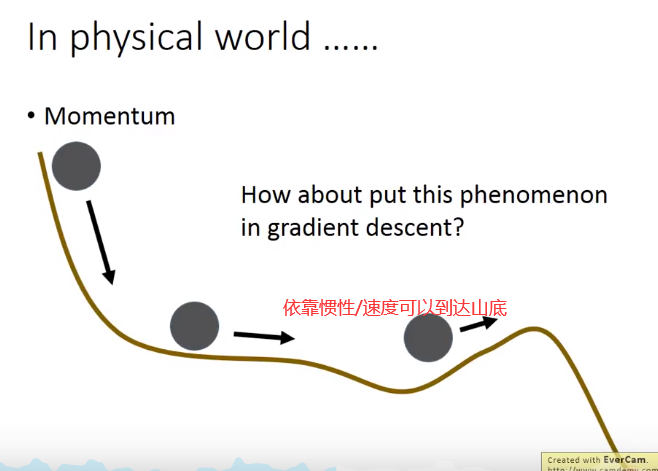


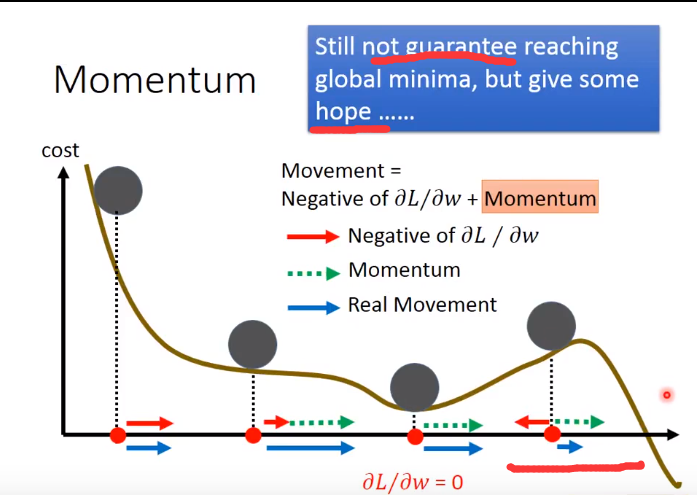
Momentum相当于利用指数加权平均给Loss function加入了一个惯性,RMSprop给△梯度加了摩擦力。
Adam
实际上是RMSProp + Momentum,

torch.optim优化算法理解之optim.Adam()
torch.optim是一个实现了多种优化算法的包,大多数通用的方法都已支持,提供了丰富的接口调用,未来更多精炼的优化算法也将整合进来。
为了使用torch.optim,需先构造一个优化器对象Optimizer,用来保存当前的状态,并能够根据计算得到的梯度来更新参数。
要构建一个优化器optimizer,你必须给它一个可进行迭代优化的包含了所有参数(所有的参数必须是变量s)的列表。 然后,您可以指定程序优化特定的选项,例如学习速率,权重衰减等。
optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum=0.9) optimizer = optim.Adam([var1, var2], lr = 0.0001) self.optimizer_D_B = torch.optim.Adam(self.netD_B.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))
Optimizer还支持指定每个参数选项。 只需传递一个可迭代的dict来替换先前可迭代的Variable。dict中的每一项都可以定义为一个单独的参数组,参数组用一个params键来包含属于它的参数列表。其他键应该与优化器接受的关键字参数相匹配,才能用作此组的优化选项。
optim.SGD([ {'params': model.base.parameters()}, {'params': model.classifier.parameters(), 'lr': 1e-3} ], lr=1e-2, momentum=0.9)
如上,model.base.parameters()将使用1e-2的学习率,model.classifier.parameters()将使用1e-3的学习率。0.9的momentum作用于所有的parameters。
优化步骤:
所有的优化器Optimizer都实现了step()方法来对所有的参数进行更新,它有两种调用方法:
(1)optimizer.step()
这是大多数优化器都支持的简化版本,使用如下的backward()方法来计算梯度的时候会调用它。
for input, target in dataset:
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
(2) optimizer.step(closure)一些优化算法,如共轭梯度和LBFGS需要重新评估目标函数多次,所以你必须传递一个closure以重新计算模型。 closure必须清除梯度,计算并返回损失。
for input, target in dataset:
def closure():
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
return loss
optimizer.step(closure)Adam算法:https://blog.csdn.net/kgzhang/article/details/77479737前面是train data 效果不好的方法,下面开始讲test data 出现问题时的方法
Early Stop
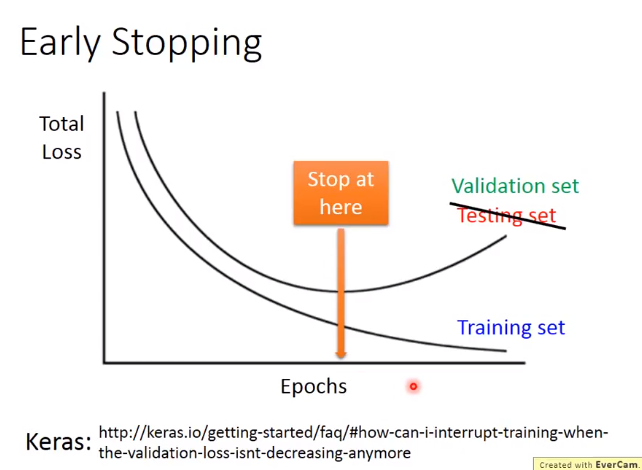
Regulation


每次都会让wt小些
1-lam*theta <1 (1-lam*theta)wt离0会越来越近
Regularization虽然在传统机器学习中有不错的表现,但在DNN中效果不怎么样,因为在DNN中初始化参数的时候参数会比较小(接近0),然后随着训练后慢慢变化(离0越来越远),
而Regularization如上图所示,它算法思想是希望参数不要离0太远,这个效果在DNN中等同于减少参数更新次数一样样。所以在SVM中是把Regularization显式写到算法中的,因为SVM可能是一次(没有迭代)就解出结果。
意思就是说DNN天生可以迭代,如果希望参数离0近一点,可以用减少更新次数来达到同样效果。

正则化:减弱权重差异,来削弱某些突出特征的显著程度,进而减少模型复杂性
L1:wt>0,就会减去lam*theta.wt<0,就会加上lam*theta。加减的是常量,
那么最后保留的有很多接近0的值,也会有很多大的值,分布离谱。L1可以产生稀疏模型(有些稀疏等于0)
L2:wt较大时,wt下降的也会快些。((1-lam*theta)*wt大些)削弱特征特别强的权重以减少过拟合
相反wt很小时,下降的会很慢。((1-lam*theta)*wt小些)因此最后会保留大都是很小的值

Dropout

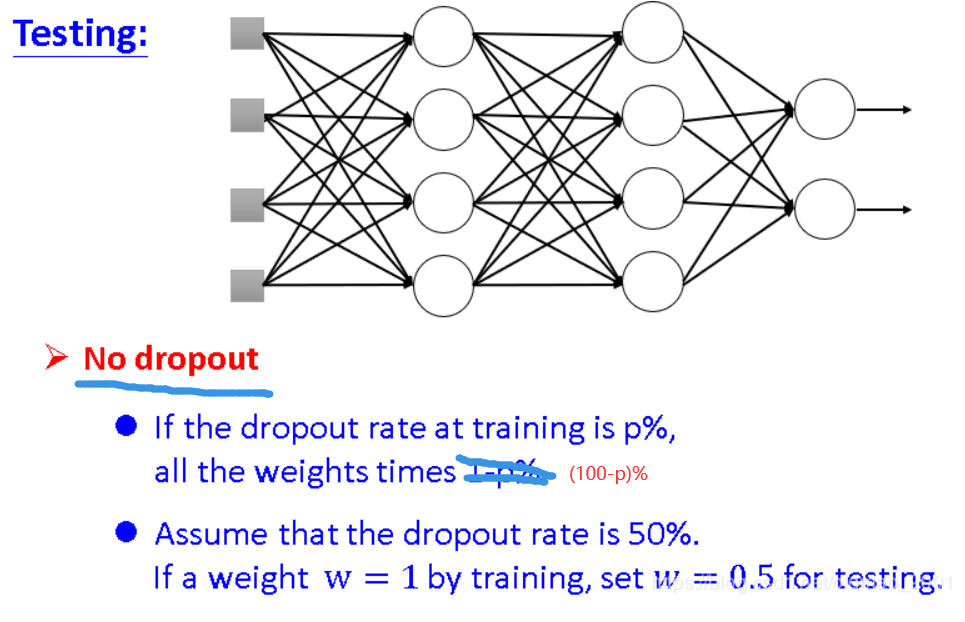
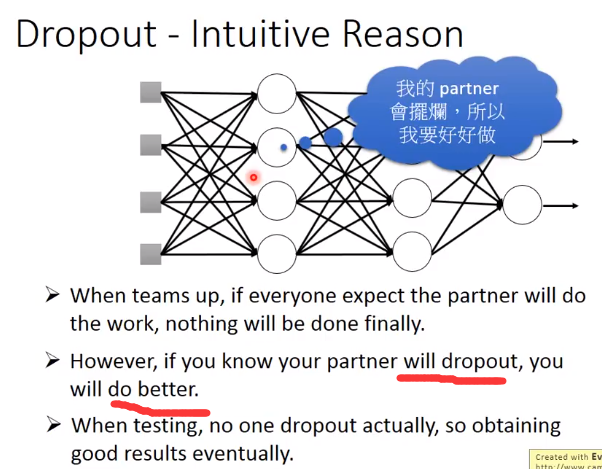
解释Dropout
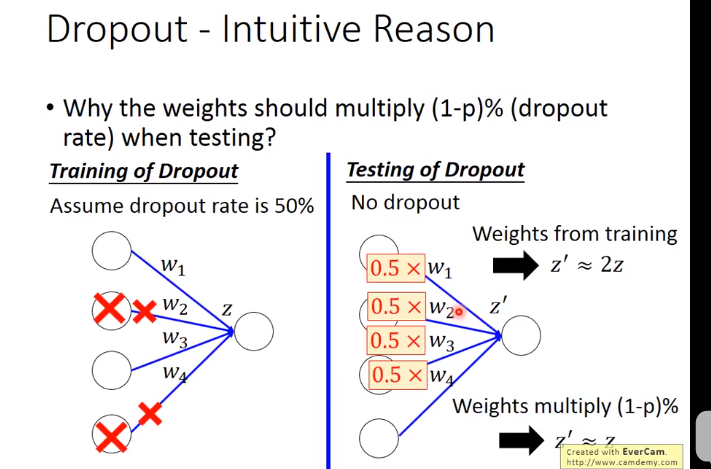
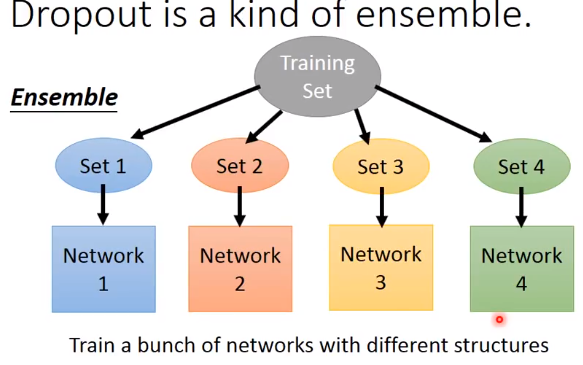
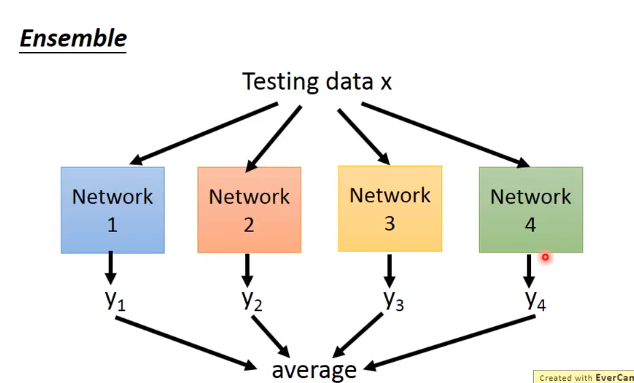
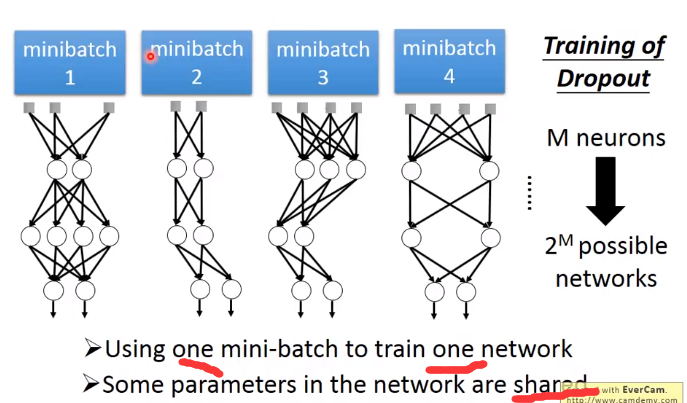

下面举个例子来解释dropout
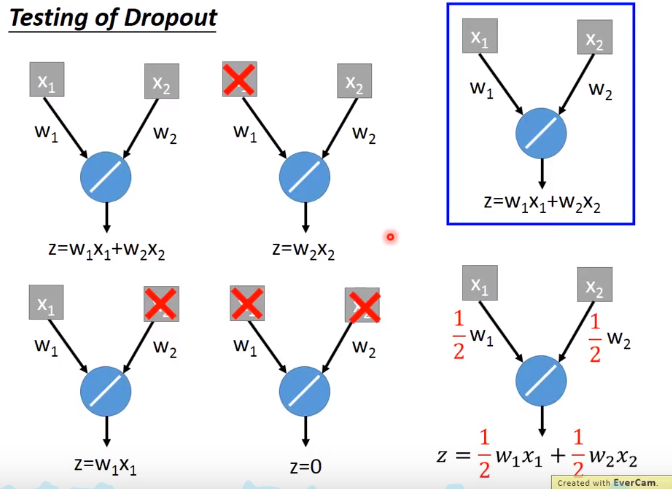
左边=(w1x1+w2x2+w2x2+w1x2+0)/4=(w1x1+w2x2)/2=右边
这里等于关系是因为激活函数是线性函数(ReLU,Maxout的时候dropout比较好用),如果是sigmoid函数就变成约等于
下面详细解释Dropout的特点
转载自: https://blog.csdn.net/program_developer/article/details/80737724
(1)Dropout出现的原因
在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象。
在训练神经网络的时候经常会遇到过拟合的问题,过拟合具体表现在:模型在训练数据上损失函数较小,预测准确率较高;但是在测试数据上损失函数比较大,预测准确率较低。
过拟合是很多机器学习的通病。如果模型过拟合,那么得到的模型几乎不能用。
为了解决过拟合问题,一般会采用模型集成的方法,即训练多个模型进行组合。此时,训练模型费时就成为一个很大的问题,不仅训练多个模型费时,测试多个模型也是很费时。
综上所述,训练深度神经网络的时候,总是会遇到两大缺点:
(1)容易过拟合
(2)费时
Dropout可以比较有效的缓解过拟合的发生,在一定程度上达到正则化的效果。
(2) 什么是Dropout
Dropout可以作为训练深度神经网络的一种trick供选择。在每个训练批次中,通过忽略一半的特征检测器(让一半的隐层节点值为0),可以明显地减少过拟合现象。
这种方式可以减少特征检测器(隐层节点)间的相互作用,检测器相互作用是指某些检测器依赖其他检测器才能发挥作用。
Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,
因为它不会太依赖某些局部的特征,如下图所示
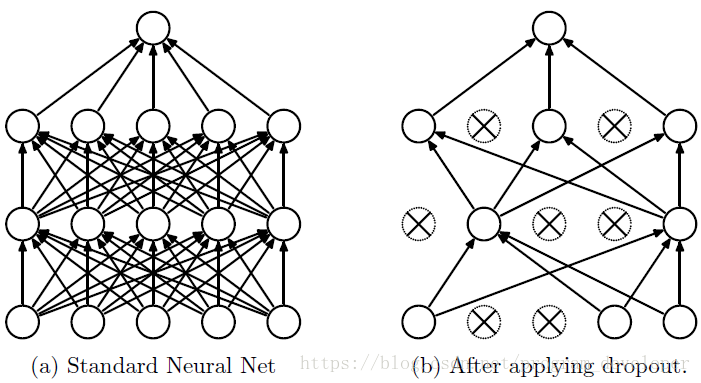
(3) Dropout具体工作流程
假设我们要训练这样一个神经网络,如下图所示。
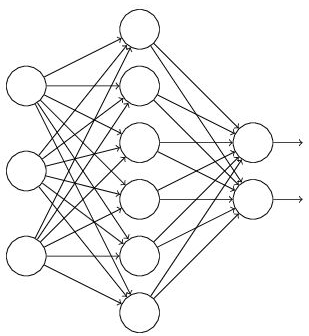
输入是x输出是y,正常的流程是:我们首先把x通过网络前向传播,然后把误差反向传播以决定如何更新参数让网络进行学习。使用Dropout之后,过程变成如下:
(1)首先随机(临时)删掉网络中一半的隐藏神经元,输入输出神经元保持不变(下图中虚线为部分临时被删除的神经元)
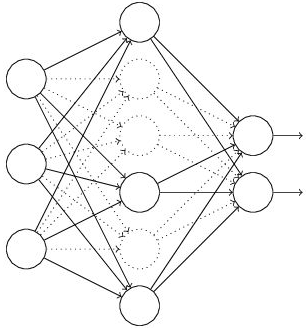
(2) 然后把输入x通过修改后的网络前向传播,然后把得到的损失结果通过修改的网络反向传播。一小批训练样本执行完这个过程后,
在没有被删除的神经元上按照随机梯度下降法更新对应的参数(w,b)。
(3)然后继续重复这一过程:
- . 恢复被删掉的神经元(此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新)
- . 从隐藏层神经元中随机选择一个一半大小的子集临时删除掉(备份被删除神经元的参数)。
- . 对一小批训练样本,先前向传播然后反向传播损失并根据随机梯度下降法更新参数(w,b)(没有被删除的那一部分参数得到更新,删除的神经元参数保持被删除前的结果)。
不断重复这一过程。
(4) Dropout在神经网络中的使用
在训练模型阶段,无可避免的,在训练网络的每个单元都要添加一道概率流程,如下图所示。
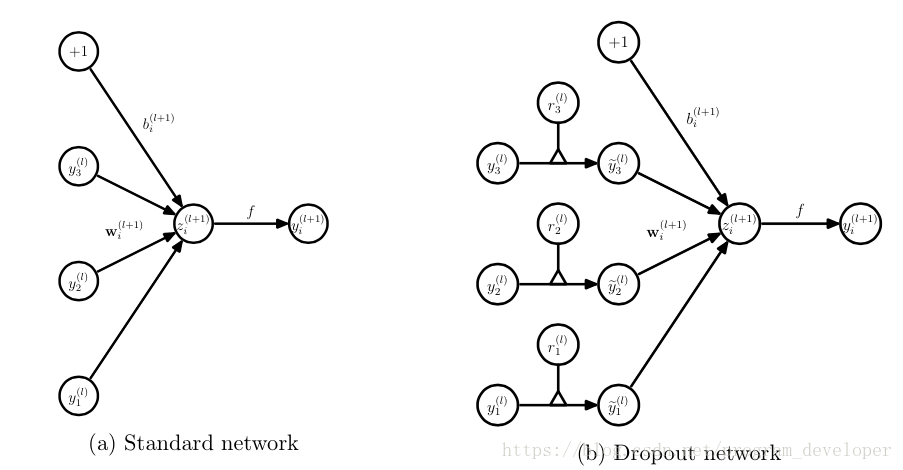
对应的公式变化如下:
- . 没有Dropout的网络计算公式:
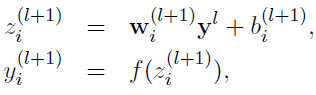
采用Dropout的网络计算公式:
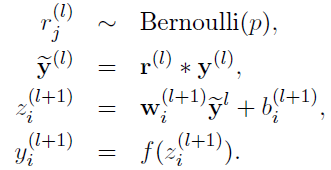
上面公式中Bernoulli函数是为了生成概率r向量,也就是随机生成一个0、1的向量。 具体参考:https://www.cnblogs.com/tingtin/p/12286578.html
代码层面实现让某个神经元以概率p停止工作,其实就是让它的激活函数值以概率p变为0。
比如我们某一层网络神经元的个数为1000个,其激活函数输出值为y1、y2、y3、......、y1000,我们dropout比率选择0.4,
那么这一层神经元经过dropout后,1000个神经元中会有大约400个的值被置为0。
注意: 经过上面屏蔽掉某些神经元,使其激活值为0以后,我们还需要对向量y1……y1000进行缩放,也就是乘以1/(1-p)。
这里为什么要*1/(1-p):在源代码中,p为丢弃概率,那么1-p就为保留概率,缩放的时候某个点的输出期望为E(x) = (1-p)(x/(1-p)) + p * 0 = x,因此输出的时候就不用特殊处理。
如果你在训练的时候,经过置0后,没有对y1……y1000进行缩放(rescale),那么在测试的时候,就需要对权重进行缩放,操作如下。
在测试模型阶段
预测模型的时候,每一个神经单元的权重参数要乘以概率p。
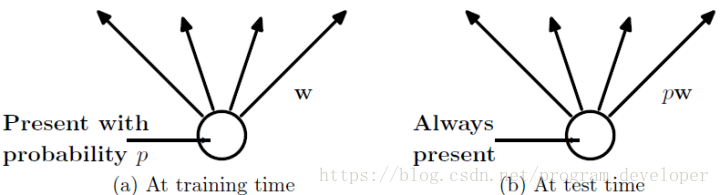
测试阶段Dropout公式:
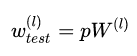
(5) 为什么说Dropout可以解决过拟合?
(1)取平均的作用: 先回到标准的模型即没有dropout,我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,
此时我们可以采用 “5个结果取均值”或者“多数取胜的投票策略”去决定最终结果。例如3个网络判断结果为数字9,那么很有可能真正的结果就是数字9,
其它两个网络给出了错误结果。这种“综合起来取平均”的策略通常可以有效防止过拟合问题。因为不同的网络可能产生不同的过拟合,
取平均则有可能让一些“相反的”拟合互相抵消。dropout掉不同的隐藏神经元就类似在训练不同的网络,随机删掉一半隐藏神经元导致网络结构已经不同,
整个dropout过程就相当于对很多个不同的神经网络取平均。而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。
(2)减少神经元之间复杂的共适应关系: 因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。
这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况 。
迫使网络去学习更加鲁棒的特征 ,这些特征在其它的神经元的随机子集中也存在。换句话说假如我们的神经网络是在做出某种预测,
它不应该对一些特定的线索片段太过敏感,即使丢失特定的线索,它也应该可以从众多其它线索中学习一些共同的特征。
从这个角度看dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高。
我们对keras中Dropout实现函数做一些修改,让dropout函数可以单独运行。
# coding:utf-8 import numpy as np # dropout函数的实现 def dropout(x, level): if level < 0. or level >= 1: #level是概率值,必须在0~1之间 raise ValueError('Dropout level must be in interval [0, 1[.') retain_prob = 1. - level # 我们通过binomial函数,生成与x一样的维数向量。binomial函数就像抛硬币一样,我们可以把每个神经元当做抛硬币一样 # 硬币 正面的概率为p,n表示每个神经元试验的次数 # 因为我们每个神经元只需要抛一次就可以了所以n=1,size参数是我们有多少个硬币。 random_tensor = np.random.binomial(n=1, p=retain_prob, size=x.shape) #即将生成一个0、1分布的向量,0表示这个神经元被屏蔽,不工作了,也就是dropout了 print(random_tensor) x *= random_tensor print(x) x /= retain_prob print(x) return x #对dropout的测试,大家可以跑一下上面的函数,了解一个输入x向量,经过dropout的结果 x=np.asarray([1,2,3,4,5,6,7,8,9,10],dtype=np.float32) dropout(x,0.4)
[1 1 1 1 0 1 1 1 0 0]
[1. 2. 3. 4. 0. 6. 7. 8. 0. 0.]
[ 1.6666666 3.3333333 5. 6.6666665 0. 10.
11.666666 13.333333 0. 0. ]
函数中,x是本层网络的激活值。Level就是dropout就是每个神经元要被丢弃的概率。 注意: Keras中Dropout的实现,是屏蔽掉某些神经元,使其激活值为0以后,对激活值向量x1……x1000进行放大,也就是乘以1/(1-p)。 思考:上面我们介绍了两种方法进行Dropout的缩放,那么Dropout为什么需要进行缩放呢? 因为我们训练的时候会随机的丢弃一些神经元,但是预测的时候就没办法随机丢弃了。如果丢弃一些神经元,这会带来结果不稳定的问题,
也就是给定一个测试数据,有时候输出a有时候输出b,结果不稳定,这是实际系统不能接受的,用户可能认为模型预测不准。
那么一种”补偿“的方案就是每个神经元的权重都乘以一个p,这样在“总体上”使得测试数据和训练数据是大致一样的。
比如一个神经元的输出是x,那么在训练的时候它有p的概率参与训练,(1-p)的概率丢弃,那么它输出的期望是px+(1-p)0=px。
因此测试的时候把这个神经元的权重乘以p可以得到同样的期望。 总结: 当前Dropout被大量利用于全连接网络,而且一般认为设置为0.5或者0.3,
而在卷积网络隐藏层中由于卷积自身的稀疏化以及稀疏化的ReLu函数的大量使用等原因,Dropout策略在卷积网络隐藏层中使用较少。
总体而言,Dropout是一个超参,需要根据具体的网络、具体的应用领域进行尝试。