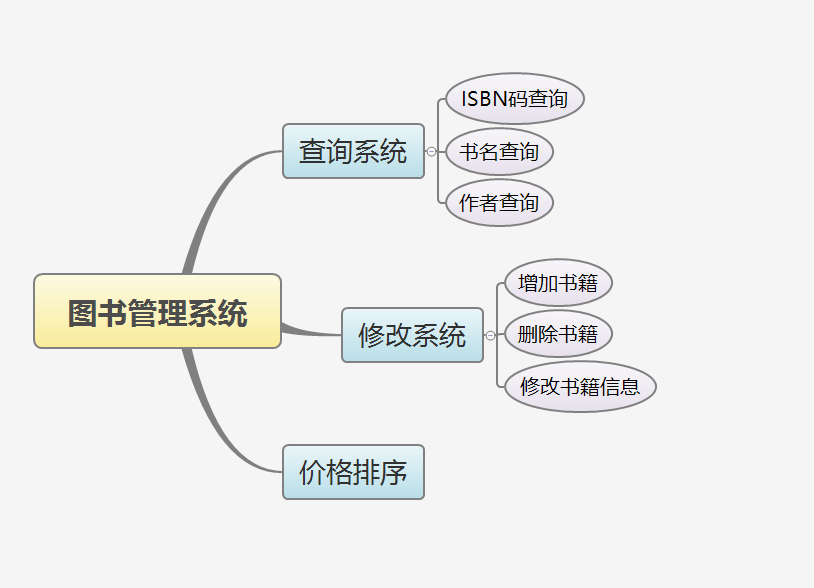
1.思维导图
2.数据结构
2.1结构体
typedef struct BOOK
{
string ISBN,book,author;
double price;
}BOOK;
typedef struct node
{
BOOK message;
struct node *next;
}List,*Link;
2.2为什么选择这样的数据结构
这样的数据结构使程序逻辑条理显得更加清晰,两个结构体分工明确
一开始只定义了一个 BOOK的结构体,结构体成员除了书籍信息还包括BOOK型的结构指针,这样使原来的BOOK结构体拥有两个结构体的作用,结构体功能不够明确
3.关键代码
3.1主要函数声明
bool insert(Link &L,Link newbook);//增加书籍
void insert_menu();//重载增加书籍函数
bool del_book(Link &L,string Isbn);//删除书籍
void del_book_menu();//删除书籍菜单
void findmenu();//查找目录
void find(Link L,string search,int chose);//查找书籍
Link find(Link &L,string name);//重载的查找函数,用于定位需修改的书籍
void findshow(int n,Link p);//显示查找到的书籍信息
void findshow(string search);//提示查找的书籍不存在
void changebook();//修改书籍信息函数
void put_file(Link L);//将书籍信息输出到文件
void in_file(Link &L);//将书籍信息从文件读取到链表
3.2 主要功能函数
生成/保存书籍链表
void put_file(Link L)//将书籍信息输出到文件
{
ofstream outfile("books.txt");
Link p,tail=L,r;
for(p=L->next;p;)
{
r=p->next;
outfile<<p->message.ISBN<<" "<<p->message.book<<" "<<p->message.author<<" "<<p->message.price<<endl;
p=r;
}
outfile.close();
}
void in_file(Link &L)//将书籍信息从文件读取到链表
{
ifstream infile("books.txt");
L=new List;
L->next=NULL;
Link p,tail=L;
p=new List;
p->next=NULL;
while((infile>>p->message.ISBN>>p->message.book>>p->message.author>>p->message.price)>0)
{ //这么写可以防止文件为空时发生错误 (这里貌似并没有什么卵用)
tail->next=p;
tail=p;
p=new List;
p->next=NULL;
}
infile.close();
}
查找类函数
void findmenu()//查找目录
{
int chose=1;
while(chose==1)
{
system("cls");
printf("请选择查找类型:
");
printf("1:按ISBN码查找
");
printf("2:按书名查找
");
printf("3:按作者查找
");
char search[60];
while(1)
{
int chose_1;
cin>>chose_1;
switch(chose_1)
{
case 1:cout<<"输入查找的ISBN码:"<<endl;break;
case 2:cout<<"输入查找的书名:"<<endl;break;
case 3:cout<<"输入查找的作者:"<<endl; break;
default:cout<<"操作错误,请重新输入:"<<endl;break;
}
if(0<chose_1&&chose_1<4) break;
}
cin>>search;
find(L_book,search,chose);
printf("
输入 1 继续查找,其他任意数字返回上一级
");
cin>>chose;
system("cls");
}
}
void find(Link L,string search,int chose)//查找书籍
{
Link p,tail=L;
int cnt=0;
for(p=L->next;p;p=p->next)
{
if(chose==1&&p->message.ISBN==search)//ISBN 码查找
{
cnt++;
findshow(cnt,p);
break;
}
if(chose==2&&p->message.book==search) //书名查找
{
cnt++;
findshow(cnt,p);
break;
}
if(chose==3&&p->message.author==search)//作者查找
{
cnt++;
findshow(cnt,p);
}
}
if(cnt==0) findshow(search);
}
void findshow(int n,Link p)
{
cout<<n<<" "<<p->message.ISBN<<" "<<p->message.book<<" "<<p->message.author<<" "<<p->message.price<<endl;
}
void findshow(string search)
{
cout<<search<<" 不存在"<<endl;
}
Link find(Link &L,string name)//重载的查找函数,用于定位需修改的书籍
{
Link p,tail=L;
for(p=L->next;p;p=p->next)
{
if(name==p->message.book)
return p;
tail=p;
}
return NULL;
}
一开始字符串用的是字符数组,在查找时,只能调用strcmp()函数,较为不方便,后来改成string字符串,这样就能直接用"==,>,<"这些比较字符进行比较了,而且,string 字符串还可以直接用"+"在字符串尾部追加字符串和字符,都十分方便,除此之外string字符串还有很方便的操作,具体的C++里的STL里都有相关描述。
插入函数
bool insert(Link &L,Link newbook)//插入书籍 ,按价格升序插入
{
Link p,tail=L;
p=L->next;
for(p=L->next;p;p=p->next)
{
if(p->message.ISBN==newbook->message.ISBN)// 以ISBN码判断书籍是否已存在
{
return false;
break;
}
if(p->message.price>=newbook->message.price)//插入书籍
{
newbook->next=p;
tail->next=newbook;
break;
}
tail=p;
}
if(p==NULL) //尾部插入
tail->next=newbook;
return true;
}
void insert_menu()//插入书籍,输入增加的书目信息
{
printf("请输入增加的书籍书目:");//可批量增加书籍
int n;
cin>>n;
Link p;
printf("请输入待增加书籍的所有信息:");
while(n--)
{
p=new List;
p->next=NULL;
cin>>p->message.ISBN>>p->message.book>>p->message.author>>p->message.price;
if(insert(L_book,p)==0)
cout<<"Error insert, "<<p->message.book<<" exited!"<<endl;
else
cout<<p->message.book<<" 已存入"<<endl;
}
Sleep(2000);
}
这里讲一下插入的思路吧,就是遍历链表,比较新书的价格,然后把要插入的书籍插入在价格比它高的第一本书前面,但是这样的话,如果遍历完链表,没有找到价格新插入的书籍价格高的书,插入就失败了,所以后面加了个判断指针是否为空的语句来避免这种情况。(本来想调用STL 里的llist()和sort(),但list()双向链表排序貌似时间复杂度还蛮高的,所以直接有序插入了)
关于stl_list的sort算法
原文地址
这边的话一般sort()使用的是快排,把需要排序的序列一分为二,然后各自递归调用mergesort,再使用Merge算法用O(n)的时间将已排完序的两个子序列归并,从而总时间效率为nlg(n)。list_sort所使用的mergesort形式上大不一样:将前两个元素归并,再将后两个元素归并,归并这两个小子序列成为4个元素的有序子序列;重复这一过程,得到8个元素的有序子序列,16个的,32个的。。。,直到全部处理完。主要调用了swap和merge函数,而这些又依赖于内部实现的transfer函数(其时间代价为O(1))。该mergesort算法时间代价亦为nlg(n),计算起来比较复杂。list_sort中预留了64个temp_list,所以最多可以处理2^64-1个元素的序列,这应该足够了:)
删除函数
void del_book_menu()//删除书籍界面
{
system("cls");
printf("请输入删除的书籍数量:");//可批量删除书籍
int n;
cin>>n;
cout<<"请输入所有待删除书籍的ISBN码:";
string Isbn;
while(n--)
{
cin>>Isbn;
if(del_book(L_book,Isbn))
cout<<"IBSN码为 "<<Isbn<<" 的书籍已删除"<<endl;
else
cout<<"IBSN码为 "<<Isbn<<" 的书籍不存在"<<endl;
}
Sleep(2000);
}
bool del_book(Link &L,string Isbn)//删除书籍
{
Link p,tail=L;
for(p=L->next;p;p=p->next)
{
if(p->message.ISBN==Isbn)
{
tail->next=p->next;
delete p;
break;
}
tail=p;
}
if(p==NULL) //删除书籍不存在
return false;
else return true;
}
修改函数
void changebook()//修改书籍
{
int chose=1;
Link p;
while(chose==1) //循环操作
{
system("cls");
char name[60];
cout<<"输入要修改书籍的书名"<<endl;
cin>>name;
p=find(L_book,name);
if(p=NULL)
cout<<"该书不存在"<<endl;
else
{
printf("%s %s %s %.2f
",p->message.ISBN,p->message.book,p->message.author,p->message.price);
printf("请选择需要修改的信息:
");
printf("1:修改ISBN码
");
printf("2:修改书名
");
printf("3:修改作者
");
printf("4:修改价格
");
printf("5:修改该书所有信息(ISBN 书名 作者 价格)
");
while(1)
{
int chose_1;
cin>>chose_1;
switch(chose_1) //按选择修改书籍指定信息
{
case 1:
cout<<"输入修改后的ISBN码:"<<endl;
cin>>p->message.ISBN;break;
case 2:
cout<<"输入修改后的书名:"<<endl;
cin>>p->message.book;break;
case 3:
cout<<"输入修改后的作者:"<<endl;
cin>>p->message.author;break;
case 4:
cout<<"输入修改后的价格:"<<endl;
cin>>p->message.price;break;
case 5:cout<<"输入修改后的所有该书信息(ISBN 书名 作者 价格)"<<endl;
cin>>p->message.ISBN>>p->message.book>>p->message.author>>p->message.price;break;
default:cout<<"操作错误,请重新输入:"<<endl;break;
}
if(0<chose_1&&chose_1<=5) break;
}
cout<<"修改成功!"<<endl;
}
printf("
输入 1 修改其他书籍,其他任意数字返回上一级
");
cin>>chose;
}
}
4.待提高的地方
4.1 查找的算法不够优化。
采用单链表遍历的方式查找书籍,只能将链表遍历一遍,逐个比较查找到所搜索的书籍,如果书目数量太大,查找速度就会很慢;思考了下老师所说的字典序查找,可将书目信息按拼音字母进行分级分类,查找时根据分级的信息科较快的定位到所查找的书籍。这样查找速度应该会快很多
4.2 文件操作过于频繁。
起初的代码只有两次文件操作,程序开始运行时执行一次读取文件的操作,和结束程序保存数据到文件的操作,但这样如果非正常关闭程序,会使之前的操作数据全部丢失,因此改为每次循环保存一次,但这样的话,如果书籍信息太多,却会大大降低运行速度
在修改过程中,老师一直强调要减少函数之间的依赖性,可以把函数分成 菜单函数和业务函数 ,菜单函数 主要负责输入和输出,也就是运行程序时,我们所能看到的部分,而 业务函数 则负责内部操作,实现的功能,并不能直观的看到,是一个纯粹的功能函数
下面以 查找函数 为例:
一开始的代码
void find(Link L,char *search,int chose)//查找书籍
{
Link p,tail=L;
int cnt=0;
for(p=L->next;p;p=p->next)
{
if(chose==1&&strcmp(p->message.ISBN,search)==0)
{
cnt++;
printf("%d %s %s %s %.2f
",cnt,p->message.ISBN,p->message.book,p->message.author,p->message.price);
break;
}
if(chose==2&&strcmp(p->message.book,search)==0)
{
cnt++;
printf("%d %s %s %s %.2f
",cnt,p->message.ISBN,p->message.book,p->message.author,p->message.price);
break;
}
if(chose==3&&strcmp(p->message.author,search)==0)
{
cnt++;
printf("%d %s %s %s %.2f
",cnt,p->message.ISBN,p->message.book,p->message.author,p->message.price);
}
}
if(cnt==0)
printf("该书不存在
");
}
这里就把查找和输出完全糅合在一起,函数能使用的范围有很大程度的限制,而业务函数因为功能纯粹能减小这样限制。
下面附上主函数
int main()
{
in_file(L_book);
int chosen;
while(1)
{
system("cls");
printf("请选择操作:
");
printf("1:查阅书籍
");
printf("2:增加书籍
");
printf("3:删除书籍
");
printf("4:修改书籍
");
cin>>chosen;
switch(chosen)
{
case 1: findmenu();break;
case 2: insert_menu();break;
case 3: del_book_menu();break;
case 4: changebook();break;
default: printf("输入错误,请重新输入
");Sleep(1200);system("cls");
break;
}
put_file(L_book);
}
}