一、面向对象基础
0、类和对象
对象:是具体的事物 xiaoming xiaohong 类:是对对象的抽象(抽象 抽出象的部分)Person
先有具体的对象,然后抽象各个对象之间象的部分,归纳出类通过类再认识其他对象。
【生活案例】
类是一个图纸 对象是根据该图纸制造多个实物
类是一个模具 对象是使用模具制造的多个铸件(月饼模子 )
类是上海大众汽车,对象就是大家购买的一辆辆具体上海大众汽车

1、内存分析
(1)程序执行过程


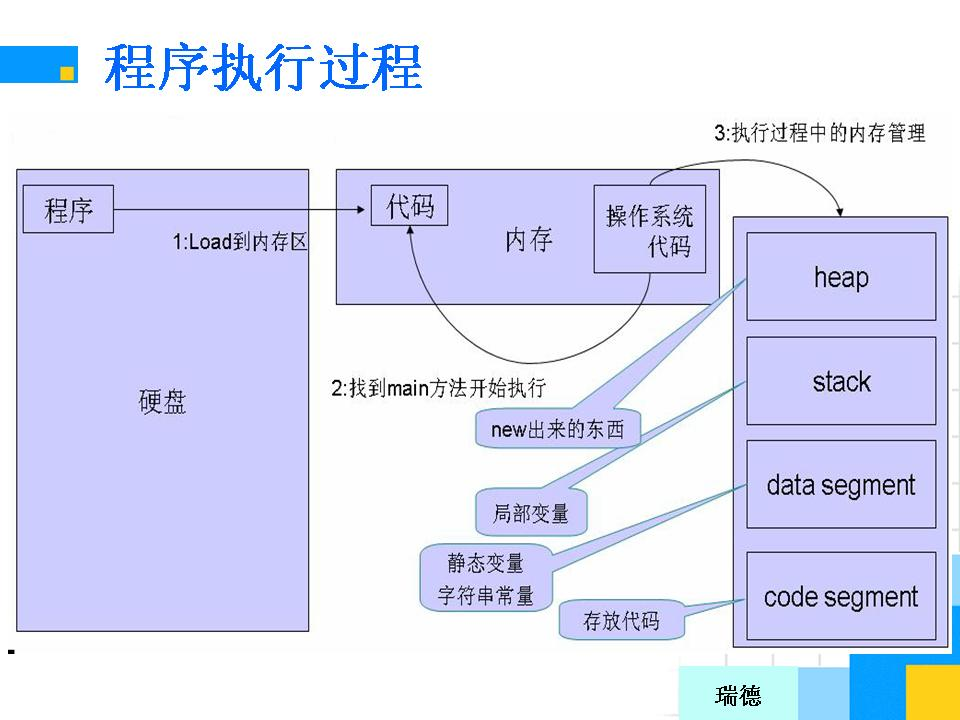
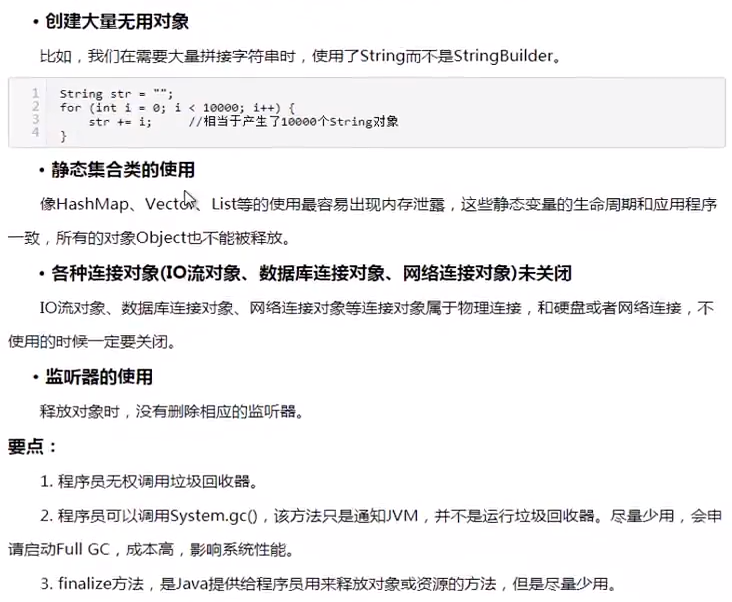
(2)容易造成内存泄漏的操作
2、构造器

3、this

4、static关键字
static修饰的成员变量和方法,从属于类。
普通变量和方法,从属于对象。
① 静态方法不能访问非静态成员【非静态成员必须有具体的类对象才可以访问】
② 非静态方法可以访问静态成员


class TS2{ public int i = 20; private static TS2 ts = new TS2(); // 限制通过new生成类对象 private TS2() { } public static TS2 getTS2() { //static是一定不能省略的,因为不能创建对象,只能由类来访问,所以得设置成静态方法 return ts; } } public class TestStatic2 { public static void main(String[] args) { // TODO Auto-generated method stub // TS2 ts = new TS2(); //error,因为构造方法是private类型的,不能直接通过new构造新对象 TS2 ts0 = TS2.getTS2(); TS2 ts1 = TS2.getTS2(); ts0.i = 99; System.out.printf("%d ",ts1.i); //99,证明 ts0和ts1是同一个对象 if(ts0 == ts1) { System.out.println("ts0和ts1相等"); //ts0和ts1相等 }else { System.out.println("ts0和ts1相等"); } } }
5、参数值传递

6、package(同一个包里不能有同名的类)




二、面向对象进阶
0、继承使用要点
(1)Java中只有单继承:Java中类没有多继承,接口有多继承。
(2)如果定义一个类时,没有调用extends,则它的父类是:java.lang.Object。
(3)使用ctrl+T方便查看类的继承层次结构。
(4)instanceof:是二元运算符,左边是对象,右边是类;当对象是右面类或子类所创建对象时,返回true,否则返回false。
1.1、方法重载 overload:
指在一个类中,多个方法的方法名相同,但是参数列表不同。参数列表不同指的是参数个数、参数类型或者参数的顺序不同。
 【选择困难症】
【选择困难症】
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------

1.2、方法重写 overdide:
在Java程序中,类的继承关系可以产生一个子类,子类继承父类,它具备了父类所有的特征,继承了父类所有的方法和变量。
子类可以定义新的特征,当子类需要修改父类的一些方法进行扩展,增大功能,程序设计者常常把这样的一种操作方法称为重写或覆盖。
/** 1>定义:在子类中重新定义父类中已有的方法 2> “==”:具有相同的方法名称、参数列表。 3> “<=”:返回值类型和声明异常类型,子类小于等于父类。
4> “>=”:重写方法时,子类不能使用比父类中被覆盖的方法更严格的访问权限(便于实现多态),也就是说不能低于父类设置的访问权限。 */

2、“==”和equals和hashCode有什么区别
2.1 “==”:代表比较双方是否相同。如果是基本类型则表示值相等,如果是引用类型则表示地址相等即是同一个对象。
2.2 equals:实际是上是Object类中定义的一个方法【public boolean equals(Object obj)】,提供定义 “对象内容相等” 的逻辑。一般都会重写equals方法。
具体来说,如果两个变量是基本数据类型,可以(只能)直接使用==来比较其对应的值是否相等。
(1)如果一个变量指向的数据是对象(引用类型),那么涉及到了两块内存,对象本身占用一块内存(堆内存),变量也占用一块内存(栈内存)。
这时候如果用==表示:这两个对象是否指向同一个对象(即指向同一块存储空间——堆内存)。但是如果要比较这两个对象的内存(占内存)是否相等,==运算符就无法实现了。
(2)在没有覆盖equals方法的情况下,equals方法与==运算符一样,比较的是引用。
equals方法的特殊之处在于它可以被覆盖,通过覆盖的方法让它不是比较引用而是比较数据内容,例如String类的equals方法就是用于比较两个独立的对象的内容是否相同,即堆中的内容是否相同。
public static void main(String[] args)
{
String s1=new String("hello");
String s2=new String("hello");
String s3=s1;
System.out.println(s1==s2); //false,说明只能比较堆内存中存储的值
System.out.println(s1==s3); //true
System.out.println(s1.equals(s3)); //true
System.out.println(s1.equals(s2)); //true
}
2.3 hashCode()方法:也是从Object类中继承过来的,也用来鉴定两个对象是否相等。
Object类的hashCode方法返回:对象在内存中的地址转换成的一个int值,如果没有重写hashCode方法,任何对象的hashCode方法都是不相等的。
(1)在HashMap中,由于key是不可以重复的,在判断key是否重复就使用了hashCode方法,并且也用到了equals方法,此处不可以重复指的是equals方法和hashCode方法只要有一个不等就可以了。
(2)一般在覆盖equals方法的同时也要覆盖hashCode方法,否则就会违反Object hashCode的通用约定,从而导致该类无法无所有基于散列值的集合类(HashMap、HashSet和HashTable)结合在一起正常运行。
// 原因:
(1)如果只覆盖了equals方法而没有覆盖hashCode方法,则两个不同的实例 A 和 B,虽然equals结果相等,但是却会有不同的‘HashCode,这样HashMap中会同时存在A和B,而实际上我们需要HashMap里面只能保存其中一个。
比如你只覆盖了equals方法而没有覆盖hashCode方法,那么HashMap在第一步寻找链表的时候会出错,有同样值的两个对象Key1和Key2并不会指向同一个链表或桶,因为你没有提供自己的hashCode方法,那么就会使用Object的hashCode方法,
该方法是根据内存地址来比较两个对象是否一致,由于Key1和Key2有不桶的内存地址,所以会指向不同的链表,这样HashMap会认为key2不存在,虽然我们期望Key1和Key2是同一个对象;
(2)反之如果只覆盖了hashCode方法而没有覆盖equals方法,那么虽然第一步操作会使Key1和Key2找到同一个链表,但是由于equals没有覆盖,那么在遍历链表的元素时,key1.equals(key2)也会失败(事实上Object的equals方法也是比较内存地址),
从而HashMap认为不存在Key2对象,这同样也是不正确的。
3、super
super是直接父类对象的引用。可以通过super来访问父类中被子类覆盖的方法或属性。
(1)每个子类构造方法的第一条语句,都是隐含地调用super()。依次向上追溯每个父类,如果没有这种形式的构造函数,那么在编译的时候会报错。
流程就是:先向上追溯到Object的构造方法 ,然后再依次向下执行类的初始化块和构造方法,直到当前子类为止。【静态初始化块调用顺序 同理】
(2)如果显式的写出super();语句,则必须保证该语句是第一条语句,否则会报错。
(3)super();如果不写,则编译器会自动添加,所以此时如果父类没有无参的构造函数就会出错。
(4)既可以显式写super();前提是父类必须有无参的构造函数;也可以显式写super(实参); 前提是父类必须有带参的构造函数。
(5)调用父类的构造函数的语句必须借助于super, 不能直接写父类的类名。

4、封装——使用访问控制符实现
(1)【高内聚、低耦合】:①类的内部操作细节 自己完成,不允许外部干涉;②仅暴漏少量的方法给外部使用,尽量方便外部调用。
(2)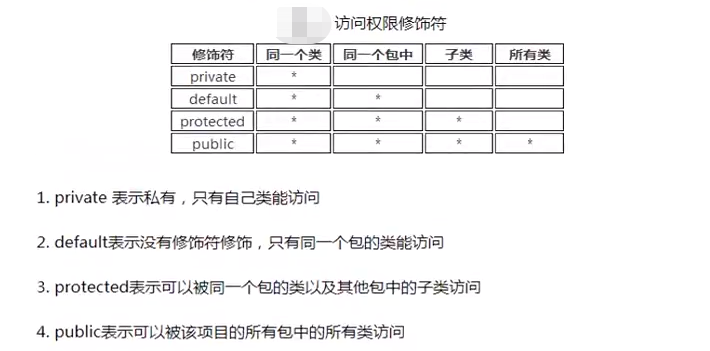
(3)使用细节——类的属性的处理:
1> 一般使用private访问权限
2> 提供相应的get/set方法来访问相关属性,这些方法通常是public修饰的,以提供属性的赋值与独取值操作(注意:Boolean变量的get方法是is 开头的)
3> 一些只用于本类的辅助性方法可以用private修饰,希望其他类调用的方法用public修饰
5、多态
(1)指的是同一个方法调用,由于对象不同可能会有不同的行为。现实生活中,同一个方法,具体实现会完全不同。
(2)多态的要点:
① 多态是方法的多态,不是属性的多态(多态与属性无关)。
② 多态的存在要有3个必要条件(继承 + 方法重写 + 父类引用指向子类对象)
③ 父类引用指向子类对象后,用该父类引用调用子类重写的方法,此时多态就出现了。

public class TestPoly{ //多态必备:继承 + 方法重写 + 父类引用指向子类对象 public static void main(String[] args) { Animal a = new Animal(); AnimalCry(a); Dog d = new Dog(); AnimalCry(d); // 多态 <=> Animal a = new Dog(); Animal c = new Cat(); // 自动向上转型 AnimalCry(c); // c.nianren(); 出错,因为在编译器里认为c 是Animal型 Cat c2 = (Cat)c; //强制向下转型 c2.nianren(); } static void AnimalCry(Animal a) { a.shout(); } } class Animal{ public void shout() { System.out.println("叫了一声"); } } class Dog extends Animal{ public void shout() { System.out.println("汪汪汪"); } } class Cat extends Animal{ public void shout() { System.out.println("喵喵喵"); } public void nianren() { System.out.println("粘人的小猫咪"); } }
【运行结果:】
叫了一声
汪汪汪
喵喵喵
粘人的小猫咪
6、final关键字的作用
(1)修饰变量:被他修饰的变量不可改变。一旦赋了初值,就不能被重新赋值。
(2)修饰方法:该方法不可以被子类重写。但是可以被重载。
(3)修饰类:修饰的类不能被继承。比如:Math、String等。
7、抽象abstract —— 意义:为子类提供统一的、规范的模板,子类必须实现
(1)有抽象方法的类只能定义为抽象类
(2)抽象类不能实例化,即不能用new来实例化抽象类
(3)抽象类可以包含属性、方法、构造方法。但是构造方法不能用来new实例,只能用来被子类调用
(4)抽象类只能被继承
(5)抽象方法必须被子类实现
8、接口 interface
(1)接口就是规范,定义的是一组规则。 里边所有的方法都是抽象方法,全面专业的实现了:规范和具体实现的分离。
(2)定义接口的详细说明:

(3)要点

(4)为什么需要接口?接口和抽象类的区别?

(5)接口相关规则

9、内部类 —— 将一个类定义置入另一个类定义中就叫作“内部类” outer$inner.class
(1)内部类分类:
成员内部类:静态内部类 + 非静态内部类
(局部)方法内部类
匿名内部类
(2)类中定义的内部类特点

(3)匿名内部类

public class TestInner { public static void main(String[] args) { // 创建内部类对象 Outer.Inner inner = new Outer().new Inner(); inner.show(); } } class Outer{ private int age = 10; public void testOuter() { System.out.println("Outer.testOuter!"); } class Inner{ int age = 20; public void show() { int age = 30; System.out.println("外部类的成员变量age:"+Outer.this.age); System.out.println("内部类的成员变量age:"+this.age); System.out.println("局部变量age:"+age); } } } //运行结果 外部类的成员变量age:10 内部类的成员变量age:20 局部变量age:30
10、String类 —— 不可变字符序列
11、数组
(1)相同类型数据的集合。
(2)foreach循环:专门用于读取数组或集合中所有的元素,即对数组进行遍历。
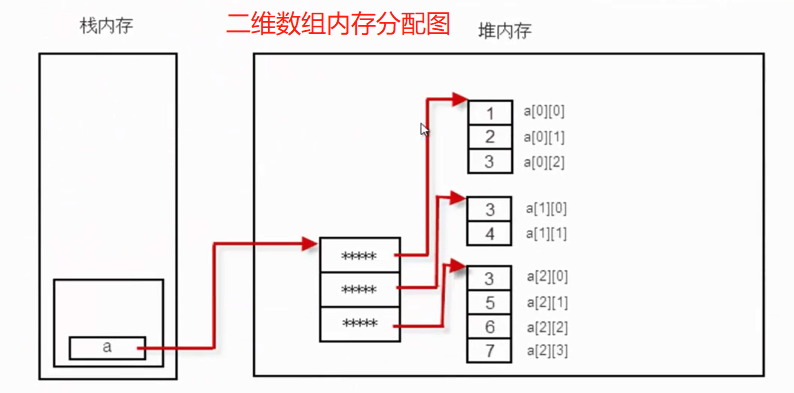
拓展:
1、集合框架的线程安全性
- A,Vector相当于一个线程安全的List
- B,HashMap是非线程安全的,其对应的线程安全类是HashTable
- C,Arraylist是非线程安全的,其对应的线程安全类是Vector
- D,StringBuffer是线程安全的,相当于一个线程安全的StringBuilder
- E,Properties实现了Map接口,是线程安全的
2、基于分代的垃圾收集算法
设计思路:把对象按照寿命长短来分组,分为年轻代和年老代,新创建的对象被分在年轻代,如果对象经过几次回收后仍然存活,那么再把这个对象划分到年老代。
年老代的收集频率不像年轻代那么频繁,这样就减少了每次垃圾回收时所要扫描的对象的数量,从而提高了垃圾回收效率。
把堆划分为若干个子堆,每个堆对应一个年龄代:
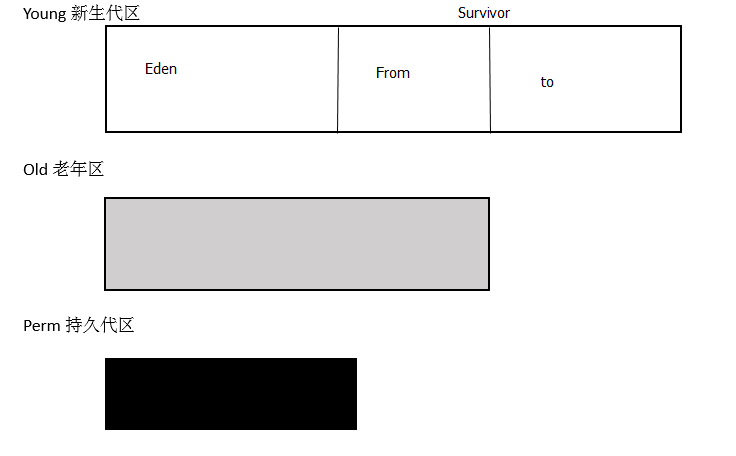
// JVM将整个堆划分为Young区、Old区和Perm区,存放不同年龄的对象,这个三个区存放的对象有如下区别: Young区:又分为Eden区和两个Survivor区,其中所有新创建的对象都在Eden区,当Eden区满后会触发minor GC将Eden区仍然存活的对象复制到其中一个Survivor区中,
另外一个Survivor区中的存活对象也复制到这个Survivor中,以保证始终有一个Survivor区是空的。 Old区:存放的是Young区的Survivor满后触发的minor GC后仍然存活的对象,当Eden区满后会将对象存放到Survivor区中,如果Survivor区仍然存不下这些对象,
GC收集器会将这些对象直接存到Old区,如果在Survivor区中的对象足够老,也直接存放到Old区,如果Old区也满了,将会触发Full GC,回收整个堆内存。 Perm区:存放的主要是类的Class对象,Perm区的垃圾回收也是由Full GC触发的。
3、finally块中的代码什么被执行?
若try{}里面有一个return语句,finally块里的代码也是在return之前执行的。
如果try-finally或者catch-finally中都有return,那么finally块中的return语句会覆盖别的return语句,最终返回到调用者的是finally中的return的值。
4、运行时异常和普通异常区别
Java提供了两种错误的异常类,分别为Error和Exception,且他们有共同的父类Throwable。
Error表示程序在运行期间出现了非常严重的错误,并且错误是不可恢复的。例如OutMemoryError、ThreadDeath、方法调用栈溢出 等都属于错误。当这些异常发生时,JVM一般会选择将线程终止。
Exception表示可恢复的异常,是编译器可以捕捉到的。它有两种类型:检查异常和运行时异常
- 检查异常:最常见的IO异常和SQ异常,这种异常都发生在编译阶段,编译器强制程序去捕获此类型的异常,果没有try……catch也没有throws抛出,编译是通不过的。
- 运行时异常:编译器没有强制对其进行捕获处理,如果不对这种异常进行处理,当出现这一种异常时,会有JVM处理,例如NullPointException空指针异常,ClassCastException类转换异常,ArrayIndexOutBoundsException数组越界异常,算术异常等。
5、多线程同步的实现方法
1、synchronize关键字
在Java中,每个对象都与一个对象锁与之相关联,该锁表明对象在任何时候只允许被一个线程所拥有,当一个线程调用对象的一个synchronize代码时,需要先获取这个锁,然后去执行相应的代码,执行结束后吗,释放锁。
2、wait方法与notify方法
线程调用对象的wait方法,进入等待状态,释放对象锁,并且可以调用notify方法通知正在等待的其他的线程。


public class WaitAndNotify { class TestWait extends Thread { public void run() { test("wait线程"); } } class TestNotify extends Thread { public void run() { test("notify线程"); } } public void exe() { TestWait tw = new TestWait(); TestNotify tn = new TestNotify(); tn.start(); tw.start(); } // 监视器 public synchronized void test(String str) { for (int i = 0; i < 10; i++) { if (i == 5) { try { wait(); } catch (InterruptedException e) { e.printStackTrace(); } } else { notify(); } System.out.println(str + "-------------" + i); } } public static void main(String[] args) { new WaitAndNotify().exe(); } }
3、Lock
Lock接口和它的一个实现类ReentrantLock(重入锁)。
lock(): 以阻塞的方式获取锁,即若获取到锁,立即返回,如果别的线程持有锁,当前线程等待,直到获取锁后返回。
tryLock(): 以非阻塞的方式获取锁,只是尝试性的去获取一下锁,如果获取到锁,返回true,否则返回false
6、sleep方法与wait方法的区别
sleep和wait均是使线程暂停执行的方法,区别在于:
1、原理不同。sleep方法是Thread类的静态方法,是线程用来控制自身流程的,它会使线程暂停执行一段时间,而把执行机会让给其他线程,等到计时时间一到,此线程就会自动“苏醒”。wait方法是Object类的方法,用于线程间的通信,这个方法会使得拥有该对象锁的进程等待,直到其他线程调用notify方法时才醒来。
2、对锁的处理机制不同。由于sleep方法的主要作用是让线程暂停执行一段时间,时间一到则自动恢复,不涉及线程间的通信,因此调用sleep方法不会释放锁。而调用wait方法后,线程会释放掉它所占用的锁,从而使线程所在对象中其他synchronize数据可被别的线程使用。
3、使用区域不同。wait方法必须放在同步控制方法或同步语句块中使用,而sleep()可以在任何地方使用。
7、synchronize与Lock区别
1、用法不同。synchronize既可以加在方法上,也可以加载特定代码中,括号表示需要锁的对象。
Lock需要显示的指定起始位置和终止位置。synchronize是托管给JVM执行的,Lock的锁定是通过代码实现的。
2、锁机制不一样。synchronize获取锁和释放锁的方式都在在块结构中,当获取多个锁时,必须以相反的顺序释放,并且是自动释放的。
Lock则需要开发人员手动去释放,并且必须在finally块中释放,否则会引起死锁问题的发生。
8、join()方法的作用
join方法的作用是:让调用该方法的线程在执行完run()方法后,再执行join方法后面的代码(插队)。例如可以通过线程A的join方法来等待线程A的结束。
9、Http中get与post方法的区别
get方法的作用主要用来获取服务器端资源信息,如同数据库中查询操作一样,不会影响到资源本身的状态。
post方法提供了比get方法更加强大的功能,它除了能够从服务器端获取资源外,同时还可以向服务器上传数据。
-—— get方法主要用来从服务器上获取数据,也可以像服务器上传数据,但是不建议,原因如下:
(1)采用get方法向服务器上传数据时,一般将数据添加到URL后面,并且二者用“?”连接,各个变量之间用“&”连接。由于URL对长度的限制,此种方法能上传的数据量非常小。
post方法传递数据通过http请求的附件进行的,传送的数据量更大。
(2)get方法上传数据被彻底暴露在url中,本身存在安全隐患。
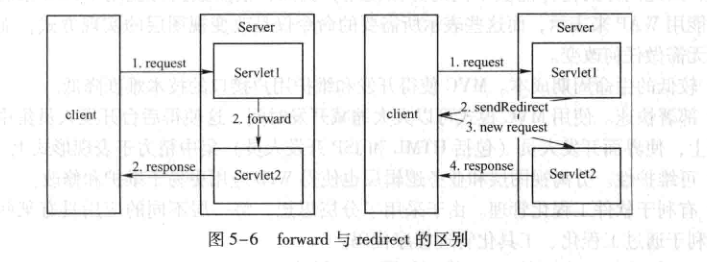
10、Servlet中forward和redirect有什么区别
1、forward是服务器内部的重定向(转发),服务器直接访问目标地址的url,把那个url的响应读取过来,而客户端并不知道。
(1)在客户端浏览器的地址栏不会显示转向后的地址。
(2)是一次请求,由于在整个定向的过程中用的是同一个Request,因此forward会将Request的信息带到被定向的jsp或Servlet中使用,资源可以共享。
(3)不能访问外部服务器(站点)资源
2、redirect是客户端的重定向,是完全的跳转,即客户端浏览器会获取到跳转后的地址,然后重新发送请求,比forward多一次网络请求。
(1)在客户端浏览器的地址栏显示转向后的地址。
(2)是两次请求,不能使用request对象共享资源。
(3)可以访问其他服务器(站点)资源
11、getparameter和getattribute的区别
(1)作用范围
request.getParameter()方法:传递的数据,会从Web客户端传到Web服务器端,代表HTTP请求数据,取得通过类似post,get等方式传入的数据(String类型)。
request.setAttribute()和getAttribute()方法:传递的数据只会存在于Web容器内部,在具有转发关系的Web组件之间共享,仅仅是请求处理阶段。这两个方法能够设置Object类型的共享数据。
(2)返回类型
- request.getAttribute()方法返回request、sessiont范围内存在的对象,
- request.getParameter()方法是获取http提交过来的数据(String)。
12、JDK1.8中的ConcurrentHashMap
与jdk1.7相比,jdk1.8中主要做了2方面的改进:
改进一:取消segments字段,直接采用transient volatile HashEntry<K,V>[] table保存数据,采用table数组元素作为锁,从而实现了对每一行数据进行加锁,进一步减少并发冲突的概率。
改进二:将原来table数组+单链表的数据结构,改为table数组+单链表+红黑树结构。
采用单链表方式,查询某个节点的时间复杂度为O(n),因此,对于个数超过8的列表,jdk1.8中采用了红黑树的结构,查询时间复杂度可以降低到O(logN)。
HashEntry 类的 value 域被声明为 Volatile 型,Java 的内存模型可以保证:某个写线程对 value 域的写入马上可以被后续的某个读线程“看”到。
在 ConcurrentHashMap 中,不允许用 null作为键和值,当读线程读到某个 HashEntry 的 value 域的值为 null 时,便知道产生了冲突——发生了重排序现象( 对链表的结构性修改都可能会导致value为null ),
需要加锁后重新读入这个 value 值。这些特性互相配合,使得读线程即使在不加锁状态下,也能正确访问 ConcurrentHashMap。