该作业要求来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2696
一.列表,元组,字典,集合分别如何增删改查及遍历。
1.列表:

2.元组:

3.字典:
d={'a':10,'b':20,'c':30}

4.集合:

二.总结列表,元组,字典,集合的联系与区别。参考以下几个方面:
(1)括号
列表[]; 元组(); 字典{};集合()或者{}
(2)有序无序
列表和元组有序,字典和集合无序
(3)可变不可变
列表,字典可变,元组不可变,集合可变也可不变
(4)重复不可重复
列表,元组,字典可重复,集合不可重复
(5)存储与查找方式
列表:存储在连续的内存地址中,利用下标索引号查找。
元组:偏移存取,可以进行索引查找
字典:键-值存储方式 ,通过键查找值
集合:存储的元素是无序且不重复 ,可以通过in或not in查找
三.词频统计
-
1.准备utf-8编码的文本文件 file
2.通过文件读取字符串 str
3.对文本进行预处理
4.分解提取单词 list
5.单词计数字典 set , dict
6.按词频排序 list.sort(key=lambda),turple
7.排除语法型词汇,代词、冠词、连词等无语义词
8.输出TOP(20)
- 可视化:词云
代码完整附说明如下所示:

#打开小说文件
f = open("D:\World.txt", 'r') #定义数组
stop={'a','the','and','i','you','in','but','not','with','by','its','for','of','an','to','my','myself','we','our','ours','ourelves','about','no','nor'} #读取文件
def gettext(): sep=",.? ?':' !--!_:" text=f.read().lower() for c in sep: textx=text.replace(c,' ') return textx #对文件进行分解 bList=gettext().split() print(bList) #把分解后的词语放在一个集合中
bSet=set(bList) print(bSet)
#把停用词放在集合中
bStop=set(stop) #去处停用词
bSet=bSet-bStop print(bSet) #定义字典对单词进行统计
bDict={} for word in bSet: bDict[word]=bList.count(word) print(bDict) print(bDict.items()) word=list(bDict.items()) #对统计结果进行排序
word.sort(key=lambda x:x[1],reverse=True) print(word)
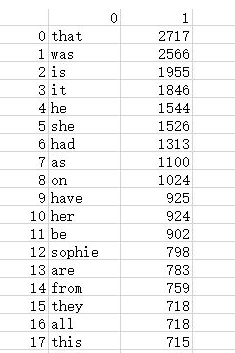
#输出前20的单词 for i in range(20): print(word[i])
#对结果输出到text.csv中
import pandas as pd
pd.DataFrame(data=word).to_csv("D:\text.csv",encoding='utf-8')
如图为运行结果显示

如图为输出到csv的统计结果