一、spring
- Spring aop(面相切面编程),ioc(控制反转) di(依赖注入)的理解
http://blog.csdn.net/jy_he/article/details/51768337
http://blog.csdn.net/zhangliangzi/article/details/51550912
这个面相切面编程真的不想了解了。说说ioc和di。
ioc和di是同一个东西在不同角度进行分析,在一个项目开发中我们需要把bean放到spring容器中,当我们需要使用这些bean的时候,就由spring容器来帮我们注入,即通过控制反转和依赖注入。都是通过反射机制来实现的。
IOC,控制反转,顾名思义就是控制器和传统的方式不同。这里有spring容器替你管理和创建相应的对象,即由IOC容器帮找到相应依赖的对象并注入,而不是传统的放心对象主动去找。IOC容器就是一个对象制造工厂,你不需要关系对象的创建和销毁,IOC包办了。
另一种解释:就是指对 对象的创建、维护、销毁等生命周期的控制由程序控制改为由IOC容器控制,需要某个对象时就直接通过名字去IOC容器中获取。
Di,即由Spring容器动态注入到依赖组件中
一句话总结:Ioc和di是指,对象的控制权交给了ioc容器管理,用到的时候由ioc容器注入到组件中
Ioc和di的意义:但它的存在使我们不需要很多代码、不需要考虑对象间复杂的耦合关系就能从IOC容器中获取合适的对象,而且提供了对 对象的可靠的管理,极大地降低了开发的复杂性
- spring注解
l http://note.youdao.com/noteshare?id=aca1a0f4bc7595f8b304db29098279a8&sub=BED48DA216E7427B966FCAC72F18EE5A
(1) @Autowired默认按照byType方式进行bean匹配,@Resource默认按照byName方式进行bean匹配
(2) @Autowired是Spring的注解,@Resource是J2EE的注解
@Controller,用以标记控制层组件
@servier,用于标记服务层组件
@Repository 用于标记数据库访问层,即DAO层
@Component 泛指组件,当无法归类到以上三层的时候,可以用这个注解
l 当@Autowired标注的bean接口有多个实现的时候,怎么指定使用哪个实现类?用注解@Qualifier,类似如下
@Autowired
@Qualifier("redisCacheServiceImpl")
private CacheService cacheService;
Spring默认的bean name是类名首字母小写
二、spring mvc
- Springmvc原理
(1) 客户端发送一个http请求到服务端,web服务端对http进行解析,如果匹配到dispatcherServelet的请求映射路径,web将请求转交给dispatcheservelet
(2) Dispatchservelet根据请求的信息以及handlermapping中配置的信息找到处理请求的处理器
(3) Dispathservelet根据handlermapping找到对应的handler,再有具体的handleradapter对handler进行具体的调度
(4) Handler处理完后由具体的ModelAndView()对象返回给dispatchserverlet
(5) 通过viewResoler将逻辑视图转为真正的view
(6) Dispacher通过model解析出ModelAndView()中的参数进行解析最终展现出完整的view并返回给客户端

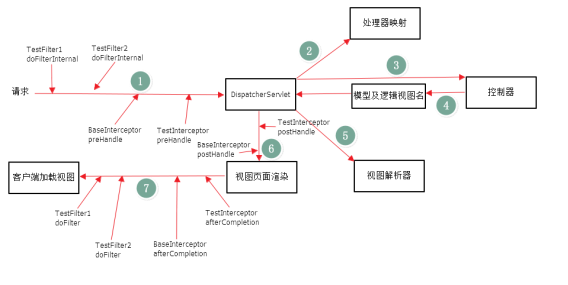
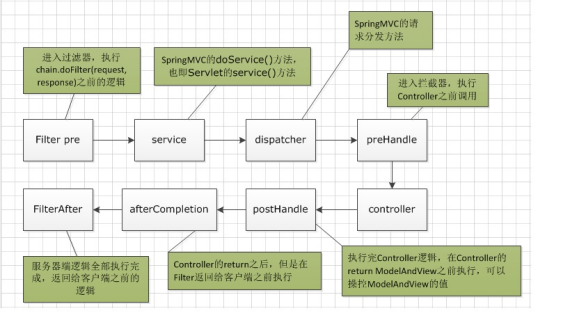
- 拦截器和过滤器
过滤器依赖servlet容器实现。在实现上基于函数回调,可以对几乎所有的请求进行过滤,但过滤实例只能在容器初始化时调用
拦截器,依赖web框架,在实现上基于JAVA反射机制,缺点是只能对controller进行拦截,不能直接对访问静态资源的请求进行拦截。
拦截器可以在方法前后,异常前后等调用。过滤器只能在请求前和请求后各调用一次;拦截器是被包裹在过滤器中的
过滤器和拦截器的执行顺序如下
三、mybatis
- mybatis缓存和代理机制。mybatis和hibernate的比较
http://blog.csdn.net/lu930124/article/details/50991899
l mybatis提供了一级缓存和二级缓存,用来提高查询性能。
一级缓存是SQLSession级别的缓存,Mybatis默认开启一级缓存,是基于hashmap的本地缓存。不同的SQLSession之间的缓存数据区域互不影响。同一个SQLSession执行两次相同的sql查询语句,第二次直接从缓存中拿数据。执行insert、update和delete会清除缓存。
二级缓存是mapper级别的缓存,同样是基于hashmap进行存储,多个SQLSession可以共享二级缓存,其作用域是 mapper 的同一个 namespace。不同的 SqlSession 两次执行相同的 namespace 下的 sql 语句,会执行相同的 sql,第二次查询只会查询第一次查询时读取数据库后写到缓存的数据,不会再去数据库查询。
二级缓存是mapper级别的缓存,多个SQLSession共享
如下图
代理模式,即只需要程序员编写Mapper接口(相当于DAO),由mybatis框架根据接口定义创建接口的动态代理对象,代理对象的方法体同DAO接口实现类方法。
Mapper接口开发需要遵循以下规范:
1、 Mapper.xml文件中的namespace与mapper接口的类路径相同。
2、 Mapper接口方法名和Mapper.xml中定义的每个statement的id相同
3、 Mapper接口方法的输入参数类型和mapper.xml中定义的每个sql 的parameterType的类型相同
4、 Mapper接口方法的输出参数类型和mapper.xml中定义的每个sql的resultType的类型相同
写mapper.xml文件,然后写mapper.java的接口文件,然后加载mapper.xml文件。mybatis官方推荐使用mapper代理方法开发mapper接口,程序员不用编写mapper接口实现类,使用mapper代理方法时,输入参数可以使用pojo包装对象或map对象,保证dao的通用性。就是代理到mapper.xml文件吧?
l Mybaits和hibernate的比较
相同点:都是ORM框架。
不同点:mybaits是通过mapper.xml维护映射关系,程序员手动编写的sql比hibernate的hql语句更加灵活,sql调优更容易,hibernate太重,sql调优麻烦;但是hibernate的hql的数据移植行好。:mybatis和hibernate都可以使用第三方缓存,而hibernate相比maybatis有更好的二级缓存机制
总结下来就是:
(1) mybatis是通过mapper.xml维护映射关系。Hibernate用hql语句,成本高,但是移植性好,那我们搞java的不太注重这个移植性问题了。Mybaits的sql调优更容易。
- Mybatis
是数据持久层框架。可以使用mybatis generator自动生成mapper和对应的配置文件。有2种基本用法:
(1) 使用注解
(2) 使用xml配置文件
基本使用是DAO层定义接口,接口的实现写在Mapper中和xml的配置文件名称相关,一一对应
四、dubbo
- Dubbo基本原理&rpc框架基本原理
Provider,服务提供方,生产者。
Consumer,服务消费方,消费者
Registry,服务注册与发现的注册中心
Monitor,监控中心,作用于服务治理
Container, 运行的服务器
调用关系说明:
0. 服务容器负责启动,加载,运行服务提供者。
1. 服务提供者在启动时,向注册中心注册自己提供的服务。
2. 服务消费者在启动时,向注册中心订阅自己所需的服务。
3. 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
4. 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
5. 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
- Zookeeper
Zookeeper是一个分布式应用协调服务。用来解决分布式系统中常见的一些数据管理问题,如统一命名服务、状态同步服务、集群管理、分布式应用配置。zookeeper维护的是一个类似文件系统的数据结构。客户端监听他关心的节点,当目录节点发生变化时,zookeeper会通知客户端。paxos算法实现,原理我不知道。
五、MQ
- 到家消息队列(dmq)
应用场景有,异步处理、应用解耦、流量削峰、日志处理、消息通讯。
主要组成有队列管理器、消息、队列、通道
Redis实现消息队列的原理是利用redis list中的lpush和rpop实现fifo消息队列。
(1) 消息顺序,消息队列一般是不支持消息顺序的,非要实现也可以,保证a消息ack后,再发b消息,但对吞吐量有影响,所以这种情况用rpc服务更合适
(2) 消息重复,这个一般是业务方自己进行幂等性处理,例如用数据库幂等表记录mq id,如果mq id存在则不处理,不存在和存入
(3) 事物消息,RocketMQ实现了事物消息
到家的消息队列原理

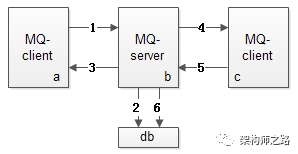
上图是一个MQ的核心架构图,基本可以分为三大块:
(1)发送方 -> 左侧粉色部分
(2)MQ核心集群 -> 中间蓝色部分,包括zk、db和后台管理等,mq核心集群对消息落地(落db)后对发送方callback,落地后发送给接收方,接收方收到后发送ack,mq serve收到ack将落地的消息进行删除。
发送方消息丢失,没有收到callback,则重发,mqserve这时候对接收方重发。下半场的消息必答会重发,接收方自己做幂等性处理。接收方最好不要对mq id做幂等,因为不知道
上半场是mq id,下半场是业务方自己去重,如orderid
(3)接收方 -> 右侧黄色部分
六、ES
ES是一个基于Lucene构建的开源、分布式、RESTful的全文本搜索引擎。
1,es的工作过程实现是如何的?如何实现分布式的啊
Elasticsearch中通过分区实现分布式,数据写入的时候根据_routing规则将数据写入某一个Shard中,这样就能将海量数据分布在多个Shard以及多台机器上,已达到分布式的目标。
2,es在数据量很大的情况下(数十亿级别)如何提高查询效率啊?
3,es的查询是一个怎么的工作过程?底层的lucence介绍一下呗?倒排索引知道吗?
对于Search类请求,查询的时候是一起查询内存和磁盘上的Segment,最后将结果合并后返回。这种查询是近实时(Near Real Time)的。
对于Get类请求,查询的时候是先查询内存中的TransLog,如果找到就立即返回,如果没找到再查询磁盘上的TransLog,如果还没有则再去查询磁盘上的Segment。这种查询是实时(Real Time)的。
7、MAVEN
1、maven如何用git命令查看依赖树?
mvn dependency:tree
maven会根据传递依赖自动将jar引用的包下载下来,如果自动下载的jar包和已存在的jar相同,则可能发生版本冲突;