目录
引子
继 Scalable Frontend 1 — Architecture Fundamentals 第二篇。
原文:Scalable Frontend #2 — Common Patterns
正文

模式应该很好的适应,就像玩积木。
让我们继续前端可扩展性的讨论!在上一篇文章中,我们讨论了前端应用程序的架构基础,但仅限于概念。现在我们要用实际的代码亲自实践一下。
常见模式(Common patterns)
我们如何实现第一篇文章中提到的架构?和我们以前做的相比有什么不同?我们如何将所有这些与依赖注入结合起来?
无论你使用哪个库来抽象视图或管理状态,在前端应用程序中有一些反复出现的模式。现在我们将要谈谈其中的一些,所以系好安全带,准备开车了!
用例(Use cases)
我们选择 用例 作为第一种模式,因为在架构方面,它们是我们与软件交互的方式。用例在一个高层次上讲述我们的应用程序做了什么;它们是我们特性的配方;是应用层的主要单元。它们定义应用程序本身。
用例通常也称为 互动者 ,它负责执行与其它层之间的交互。他们:
- 被输入层调用,
- 应用它们的算法,
- 使定义域层和基础设施层交互,不必关心它们内部的工作方式,并且,
- 将结果状态返回给输入层。结果状态表明用例是成功还是由于内部错误、验证失败、前置条件等等而失败。
了解结果状态是很有用的,因为它有助于确定要为结果响应什么操作,从而允许 UI 中有更丰富的信息,这样用户就可以知道在失败情况下发生了什么错误。但这里有一个重要细节:结果状态的逻辑应该在用例内部,而不是输入层——因为这个不是输入层的责任。这意味着输入层 不 应该接收从用例传递来的通用错误对象,并求助于使用 if 语句来找出失败的原因,比如检查 error.message 属性或使用 instanceof 查询错误的类。
这让我们碰到一个棘手的事实:从用例中返回 promise 可能不是最佳的设计决策,因为 promise 只有两种可能的结果:成功和失败,需要我们借助 catch() 语句找到失败的原因。这是否意味着在软件中我们应该忽略 promise ?不!只要输入层对此一无所知,就完全可以从我们代码的其它部分返回 promise ,比如操作、存储库和服务。克服这个限制的一个简单方法是,对用例的每个可能结果状态提供一个回调。
用例的另一个重要特征是,它们应该遵循层与层之间的边界:不知道什么入口点在调用它们,即使在只有一个入口点的前端也是如此。这意味着我们不应该在用例中接触浏览器全局变量、DOM 特定值、或任何其它低级别对象。例如:我们不应该接收 <input/> 元素的实例作为参数,然后读取它的值;输入层应该负责提取这个值并将它传递给用例。
没有什么能比举例说明更清楚:
export default ({ validateUser, userRepository }) => async (userData, { onSuccess, onError, onValidationError }) => {
if(!validateUser(userData)) {
return onValidationError(new Error('Invalid user'));
}
try {
const user = await userRepository.add(userData);
onSuccess(user);
} catch(error) {
onError(error);
}
};
const createUserAction = (userData) => (dispatch, getState, container) => {
container.createUser(userData, {
// notice that we don't add conditionals to emit any of these actions
onSuccess: (user) => dispatch(createUserSuccessAction(user)),
onError: (error) => dispatch(createUserErrorAction(error)),
onValidationError: (error) => dispatch(createUserValidationErrorAction(error))
});
};
注意,在 userAction 中,我们不会对 createUser 用例的响应做出任何断言;我们相信用例会为每个结果调用正确的回调。而且,即使 userData 对象中的值来自 HTML 输入,用例对此一无所知。它只接收提取的数据并将其转发。
就是这样了!用例不应该做更多的事了。你能看出现在测试它们有多容易吗?我们只要注入我们想要的模拟依赖项,并测试用例是否针对每种情况调用了正确的回调。
实体、值对象和聚合(Entities, value objects, and aggregates)
实体是我们定义域层的核心:它们代表我们软件处理的概念。假设我们正在构建一个 博客引擎应用程序;在这种情况下,如果引擎允许,我们可能会有一个 User 实体、一个 Article 实体,甚至一个 Comment 实体。实体只是保存那些概念的数据和行为的对象,而不考虑技术。实体不应被视为模型或活动记录设计模式的实现;它们对数据库、AJAX 或持久化一无所知。它们只是代表了这个概念以及围绕这个概念的业务规则。
举个例子,如果我们博客引擎的一个用户在评论一篇关于暴力的文章时有年龄限制,我们会有一个 user.isMajor() 方法将在 article.canBeCommentedBy(user) 内部调用,用这样的方式把年龄分类规则保持在 user 对象内,年龄限制规则保持在 article 对象内。AddCommentToArticle 用例将把用户实例传递给 article.canBeCommentedBy ,执行它们之间 交互 的将是这个用例。
有一个方法可以识别你代码库中那些是一个实体:如果一个对象表示一个定义域概念,并且它有一个标识符 属性(例如 id、slug 或文档编号),那么它就是一个实体。这个标识的存在很重要,因为它是实体与值对象的区别所在。
虽然实体具有标识符属性,但值对象的标识由其所有属性的值组合而成。想不明白?想象一个颜色对象。当用一个对象来表示一种颜色时,我们通常不会给这个对象一个 id ;我们给它 red、green 和 blue 的值,正是这三个属性的组合标识了这个对象。如果我们改变 red 属性的值,我们现在可以说它代表另一种颜色,但用 id 标识的用户不会发生这样的情况。如果我们修改 name 属性的值,但保持相同的 id ,我们认为仍然是同一个用户,对吧?
在本节的开头,我们说过在实体中包含业务规则和行为的方法是很常见的。但在前端,将业务规则作为实体对象的方法并不总是行得通。想想函数式编程:我们没有实例方法,或者 this ,或者可变性——使用普通的 JavaScript 对象代替自定义类的实例,这是可以很好地处理单向数据流的典范。当使用函数式编程时,实体中包含方法还有意义吗?当然没有。那么我们该如何创建具有这类限制的实体呢?我们通过函数的方式。
我们将有个 User 模块导出命名为 isMajor(user) ,代替 User 类实例方法 user.isMajor(),它接受一个具有用户属性的对象,并将其视为来自 User 类的 this 。参数不需要是特定类的实例,只要它具有与用户相同的属性。这一点很重要:属性( User 实体的预期参数)应该以某种方式格式化。你可以使用纯 JavaScript 工厂函数来实现,或者更明确地使用 Flow 或 TypeScript 。
让我们来看一个前后对照,以便更容易理解。
// User.js
export default class User {
static LEGAL_AGE = 21;
constructor({ id, age }) {
this.id = id;
this.age = age;
}
isMajor() {
return this.age >= User.LEGAL_AGE;
}
}
// usage
import User from './User.js';
const user = new User({ id: 42, age: 21 });
user.isMajor(); // true
// if spread, loses the reference for the class
const user2 = { ...user, age: 20 };
user2.isMajor(); // Error: user2.isMajor is not a function
// User.js
const LEGAL_AGE = 21;
export const isMajor = (user) => {
return user.age >= LEGAL_AGE;
};
// this is a user factory
export const create = (userAttributes) => ({
id: userAttributes.id,
age: userAttributes.age
});
// usage
import * as User from './User.js';
const user = User.create({ id: 42, age: 21 });
User.isMajor(user); // true
// no problem if it's spread
const user2 = { ...user, age: 20 };
User.isMajor(user2); // false
当处理像 Redux 这样的状态管理器时,你可以更容易支持不变性,因此不能通过创建浅拷贝扩展对象并不是一件好事。使用函数方法将强制解耦,并且我们仍然能够扩展对象。
所有这些规则都适用于值对象,但它们还有另一个重要作用:它们有助于使我们的实体不那么臃肿。在实体中有许多属性彼此不直接相关是很常见的,这可能是我们能够将其中一些属性提取到值对象的一个迹象。例如,假设我们有个 Chair 实体,拥有属性 id、cushionType、cushionColor、legsCount、legsColor、legsMaterial 。注意到 cushionType、cushionColor 和 legsCount、legsColor、legsMaterial 没有关联,因此在提取一些值对象后,我们的椅子将简化为三个属性:id、cushion 和 legs 。现在我们可以继续为 cushion 和 legs 添加属性,而不会使 Chair 更加臃肿。

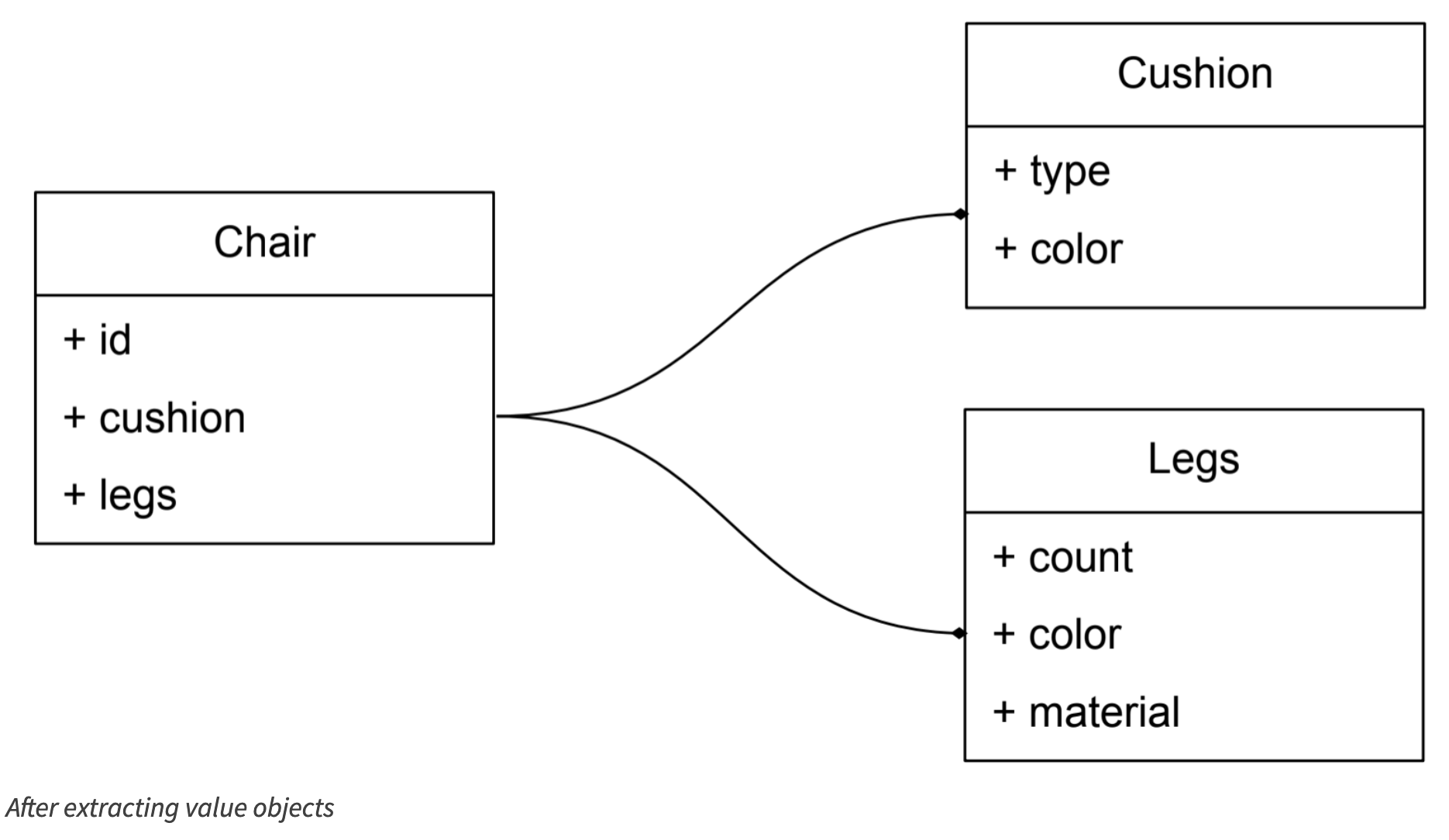
但仅仅从实体中提取值对象并不总是足够的。你会注意到,往往会有与次要实体关联,又代表了主要概念的主要实体,作为一个 整体 主要实体依赖这些次要实体,而这些次要实体单独存在是没有意义的。现在你脑子里肯定有些混乱,所以让我们把它弄清楚。
想想购物车。购物车可以用 Cart 实体来表示,由 lineItems 组成,lineItems 也是实体,因为它们有自己的 id 。lineItems 只能通过主实体 cart 对象进行交互。想知道给定的产品是否在购物车内吗?调用 cart.hasProduct(product) 方法,而不是类似 cart.lineItems.find(...) 直接查找 lineItems 的属性。这种对象之间的关系称之为 聚合(aggregate)。提供聚合的主要实体(在这个例子中指 cart 对象)称为 聚合根(aggregate root)。表示聚合概念的实体及其所有组件只能通过 cart 访问,但聚合中的实体可以从外部引用对象。我们甚至可以说,在单个实体单独能够表示整个概念的情况下,该实体也是由单个实体及其值对象(如果有的话)组成的聚合。因此,当我们说“聚合”时,从现在起,你必须把它理解为适当的聚合或单一实体聚合。
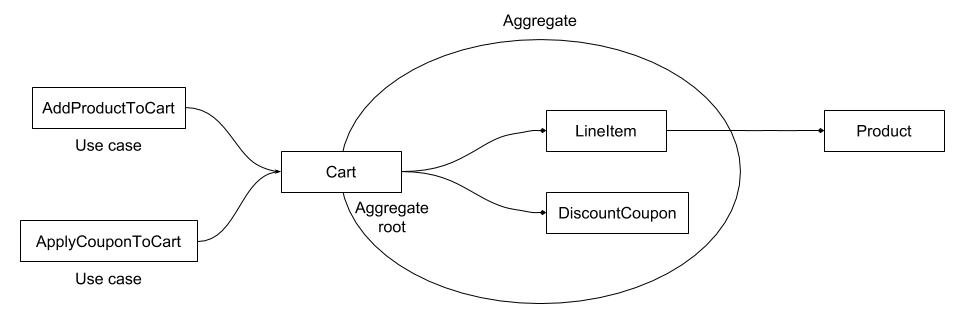
无法从外部访问聚合的内部实体,但次要实体可以访问聚合外部的东西,比如产品
在我们的代码库中定义好实体、聚合和值对象,并以定义域层的行家如何引用它们来命名,这是非常有价值的(没有其它意思)。所以在把代码扔到其它地方之前,一定要注意是否可以用它们抽象出一些东西。另外,一定要理解实体和聚合,因为它对下一个模式很有用!
存储库(Repositories)
你注意到我们还没谈到持久化吗?考虑它很重要,因为它强调了我们从一开始就谈到的内容:持久化是一个实现细节,一个次要的关注点。只要负责处理这些内容的部分被合理地封装并且不影响你的其余代码,那么你可以将这些内容持久化到软件中的任何地方。在大多数分层的架构中,这是存储库的责任,存储库位于基础设施层中。
存储库是用于持久化和读取实体的对象,因此它们应该执行使它们 看起来像 集合的方法。如果你有一个 article 对象并且想要持久化它,那么你可能会有一个 ArticleRepository ,它有一个 add(article) 方法,该方法将文章作为一个参数,把文章持久化到 某个地方 ,然后返回一个带有持久化只读属性(例如 id )的文章副本。
我说过我们会有一个 ArticleRepository ,但我们如何持久化其它对象?我们是否应该有一个不同的存储库来持久化用户?我们应该有多少个存储库,它们的粒度应该有多大?冷静点,规则并不难掌握。你还记得聚合吗?那是我们界定的地方。经验法则是代码库的每个聚合都有一个对应存储库。我们还可以为次要实体创建存储库,但仅在必要时。
好吧,好吧,听起来很像在谈论后端。存储库在前端做什么?我们那里没有数据库!这里的关键是:停止将存储库与数据库相关联。存储库是关于整体的持久化,而不仅仅是关于数据库。在前端,存储库处理来自 HTTP APIs、LocalStorage、IndexedDB 等等数据源。在上一个示例中,我们的 ArticleRepository#add 方法将一个 Article 实体作为输入,将其转换为 API 期望的 JSON 格式,对 API 进行 AJAX 调用,然后将 JSON 响应映射回 Article 实体的实例。
注意到这些很好,例如,如果 API 还在开发中,我们可以通过实现一个名为 LocalStorageArticleRepository 的 ArticleRepository 来模拟它,它与 LocalStorage 通信而不是 API 。当 API 准备好后,我们创建另一个名为 AjaxArticleRepository 的实现,替换 LocalStorage ——只要它们共享同一个 接口 ,并且注入一个不会暴露底层技术的通用名称,比如 articleRepository 。
我们在这里使用的术语 interface ,表示一个对象应该实现的方法和属性集,所以不要把它与图形用户界面(又称 GUIs )混淆。如果你使用的是原生 JavaScript ,那么接口将只是概念性的;它们将是虚构的,因为该语言不支持接口的显式声明,但是如果你使用的是 TypeScript 或 Flow ,它们是可以的。

服务(Services)
这个不是最后的模式。它之所以在这里,因为它应该被视为“最后的手段”。当你无法将一个概念融入到前面的任何一种模式中时,那么你就应该考虑创建一个服务。任何一段可重用基础代码被抛出到所谓的“服务对象”中是很常见的,这只是一堆没有封装概念的可重用逻辑。始终要意识到这一点,不要让这种情况发生在你的代码库中,并且抵制创建服务而不是用例的冲动,因为它们不是一回事。
简单来说:服务对象执行的程序,不适合定义域的对象。例如,支付网关。
让我们想象一下,我们正在构建一个电子商务,我们需要与支付网关的外部 API 通信,以获取购买的授权令牌。支付网关不是一个定义域的概念,因此它非常适合 PaymentService 。向其中添加不会透露技术细节的方法,例如 API 响应的格式化,然后你就有了一个具有良好封装的,用来进行软件和支付网关之间通信的通用对象。
就这些了,没有什么秘密。尝试将你的定义域概念与上述模式相匹配,如果它们都不起作用,那么只好考虑使用服务。它包含了代码库的所有层!
文件组织(File organization)
许多开发人员误解了架构和文件组织之间的区别,认为后者定义了应用程序的架构。或认为有良好的组织,应用程序也能很好地扩展,这完全是一种误导。即使使用了最完美的文件组织,你的代码库仍然存在性能和可维护性问题,因此这是本文的最后一个主题。让我们解释清楚组织到底是什么,以及如何将其与架构结合使用,以实现可读和可维护的项目结构。
大体上,组织是你如何在视觉上分离应用程序的各个部分,而架构是如何在 概念 上分离应用程序。你完全可以保持相同的架构,并且在选择组织方案时仍有多种选择。不过,组织你的文件以反映架构的各个层,有利于代码库的读者,这是个好主意,这样他们只要通过查看文件树就可以了解发生了什么。
没有完美的文件组织,所以根据你的品味和需要明智地选择。这里有两种方式对于突出本文中讨论的层次特别有用。让我们逐一看看。
第一种方式是最简单的,它以 src 文件夹作为根目录,然后按照你的架构理念划分层次。例如:
.
|-- src
| |-- app
| | |-- user
| | | |-- CreateUser.js
| | |-- article
| | | |-- GetArticle.js
| |-- domain
| | |-- user
| | | |-- index.js
| |-- infra
| | |-- common
| | | |-- httpService.js
| | |-- user
| | | |-- UserRepository.js
| | |-- article
| | | |-- ArticleRepository.js
| |-- store
| | |-- index.js
| | |-- user
| | | |-- index.js
| |-- view
| | |-- ui
| | | |-- Button.js
| | | |-- Input.js
| | |-- user
| | | |-- CreateUserPage.js
| | | |-- UserForm.js
| | |-- article
| | | |-- ArticlePage.js
| | | |-- Article.js
当使用这种组织与 React 和 Redux 配合时,经常会看到 components、containers、reducers、actions 等等这样文件夹。我们倾向更进一步,在同一个文件夹中对类似的职责进行分组。例如,我们的组件和容器都将放入 view 文件夹中,actions 和 reducer 将放入 store 文件夹中,因为它们遵循了将因同样原因而改变的事情集中起来的规则。以下是这种组织方式的一些立场:
- 你不应该有反映技术角色的文件夹,如“controllers”、“components”、“helpers”等;
- 实体位于
domain/<concept>文件夹,其中“concept”是实体所在聚合的名称,并通过domain/< concept>/index.js文件导出; - 当一个单元可能适合两个不同的概念时,选择一个如果概念不存在,那么给定单元就不存在的概念;
- 可以在同一层的概念之间导入文件,只要不会导致耦合。
第二种方式以 src 文件夹作为根目录,按照功能划分文件夹。假设我们正在处理文章和用户;在这种情况下,我们将有两个功能文件夹来组织它们,然后第三个文件夹用于处理共同的事情,例如通用 Button 组件,甚至可以有一个仅用于 UI 组件的功能文件夹:
.
|-- src
| |-- common
| | |-- infra
| | | |-- httpService.js
| | |-- view
| | | |-- Button.js
| | | |-- Input.js
| |-- article
| | |-- app
| | | |-- GetArticle.js
| | |-- domain
| | | |-- Article.js
| | |-- infra
| | | |-- ArticleRepository.js
| | |-- store
| | | |-- index.js
| | |-- view
| | | |-- ArticlePage.js
| | | |-- ArticleForm.js
| |-- user
| | |-- app
| | | |-- CreateUser.js
| | |-- domain
| | | |-- User.js
| | |-- infra
| | | |-- UserRepository.js
| | |-- store
| | | |-- index.js
| | |-- view
| | | |-- UserPage.js
| | | |-- UserForm.js
这种组织方式的立场与第一个基本相同。对于这两种情况,你应该将依赖容器放在 src 文件夹的根目录中。
再说一次,这些选项可能不适合你的需求,因此可能不是你理想的组织方式。所以,花时间尝试移动文件和文件夹,直到你实现一个让你更容易找到所需文件的方案。这是发现什么更适合你的团队的最佳方法。请注意,仅仅将代码分离到文件夹并不能使应用程序更易于维护!你在代码中分离责任时,需要保持相同的心态。
接下来
哇!相当多的内容,对吧?没关系,我们在这里讲了很多模式,所以不要强迫自己在一次阅读中理解所有。请随意重新阅读和检查本系列的第一篇文章和我们的示例,直到你对架构及其实现的轮廓感到更清晰为止。
在下一篇文章中,我们还将讨论一些实际的例子,但重点完全放在状态管理上。
如果你想看到此架构的真正实现,请查看 blog engine application 应用程序的代码。请记住没有什么是一成不变的,在接下来的文章中,我们还会讨论一些模式。
推荐链接
- Mark Seemann — Functional architecture — The pits of success
- Scott Wlaschin — Functional Design Patterns