sscanf() - 从一个字符串中读进与指定格式相符的数据。
不多说了,看看下面这些介绍和列子吧!
函数原型:
Int sscanf( string str, string format, mixed var1, mixed var2 ... );
int scanf( const char *format [,argument]... );
sscanf与scanf类似,都是用于输入的,只是后者以屏幕(stdin)为输入源,前者以固定字符串为输入源。
其中的format可以是一个或多个
%[a-z] 表示匹配a到z中任意字符,贪婪性(尽可能多的匹配)
%[aB'] 匹配a、B、'中一员,贪婪性
%[^a] 匹配非a的任意字符,贪婪性
1. 常见用法。
char buf[512] = {0};sscanf("123456 ", "%s", buf);
printf("%s ", buf);
结果为:123456
sscanf("123456 ", "%4s", buf);
printf("%s ", buf);
结果为:1234
sscanf("123456 abcdedf", "%[^ ]", buf);
printf("%s ", buf);
结果为:123456
4. 取仅包含指定字符集的字符串。如在下例中,取仅包含1到9和小写字母的字符串。
sscanf("123456abcdedfBCDEF", "%[1-9a-z]", buf);
printf("%s ", buf);
结果为:123456abcdedf
5. 取到指定字符集为止的字符串。如在下例中,取遇到大写字母为止的字符串。
sscanf("123456abcdedfBCDEF", "%[^A-Z]", buf);
printf("%s ", buf);
结果为:123456abcdedf
sscanf("iios/12DDWDFF@122", "%*[^/]/%[^@]", buf);
printf("%s ", buf);
结果为:12DDWDFF
7、给定一个字符串““hello, world”,仅保留world。(注意:“,”之后有一空格)
结果为:world
%*s表示第一个匹配到的%s被过滤掉,即hello被过滤了
如果没有空格则结果为NULL。
8、 char *s="1try234delete5"
则: sscanf(s, "1%[^2]234%[^5]", s1, s2);
scanf的format中出现的非转换字符(%之前或转换字符之后的字符),即此例中的1234用来跳过输入中的相应字符;
‘[]’的含义与正则表达式中相同,表示匹配其中出现的字符序列;^表示相反。使用[ ]时接收输入的变量必须是有足够存储空间的char、signed char、unsigned char数组。记住[也是转换字符,所以没有s了。
char s1[4],s2[4],s3[4],s4[4],s5[4],s6[4],s7[4];
sscanf(test,"%[^,],%[^,],%[^,],%[^,],%[^,],%[^,],%[^,]",s1,s2,s3,s4,s5,s6,s7);
printf("sssa1=%s",s1);
printf("sssa2=%s",s2);
printf("sssa3=%s",s3);
printf("sssa4=%s",s4);
printf("sssa5=%s",s5);
printf("sssa6=%s",s6);
printf("sssa7=%s",s7);
9、一个提取用户个人资料中邮件地址的例子
#include<cstdlib>
#include<cstdio>
using namespace std;
int main()
{
char a[20]={0};
char b[20]={0};
//假设email地址信息以';'结束
sscanf("email:jimmywhr@gmail.com;","%*[^:]:%[^;]",a);
//假设email地址信息没有特定的结束标志
sscanf("email:jimmywhr@gmail.com","%*[^:]:%s",b);
printf("%s
",a);
printf("%s
",b);
system("pause");
return 0;
} 关键是"%*[^:]:%[^;]"和"%*[^:]:%s"这两个参数的问题
%*[^:] 表示满足"[]"里的条件将被过滤掉,不会向目标参数中写入值。这里的意思是在
第一个':'之前的字符会在写入时过滤掉,'^'是表示否定的意思,整个参数翻译
成白话就是:将在遇到第一个':'之前的(不为':'的)字符全部过滤掉。
: 自然就是跳过':'的意思。
%[^;] 拷贝字符直到遇到';'。
%[ ] 的用法:%[ ]表示要读入一个字符集合, 如果[ 后面第一个字符是”^”,则表示反意思。
%[a-z] 读取在 a-z 之间的字符串,如果不在此之前则停止,如
%[^a-z] 读取不在 a-z 之间的字符串,如果碰到a-z之间的字符则停止,如
%*[^=] 前面带 * 号表示不保存变量。跳过符合条件的字符串。
%[^=] 读取字符串直到碰到’=’号,’^’后面可以带更多字符,如:
Sprintf()字符串格式化命令
Sprintf
函数声明:int sprintf(char *buffer, const char *format [, argument1, argument2, …])
用途:将一段数据写入以地址buffer开始的字符串缓冲区
所属库文件: <stdio.h>
参数:(1)buffer,将要写入数据的起始地址;(2)format,写入数据的格式;(3)argument:要写的数据,可以是任何格式的。
返回值:实际写入的字符串长度
说明:此函数需要注意缓冲区buffer溢出,要为写入的argument留足长度,可以用来代替itoa,即把整数转化为字符串。
Snprintf
函数声明:int snprintf(char *str, size_t size, const char *format, …)
用途:sprintf的安全模式,比sprintf多一个参数size。将一段数据写入以地址str开始的字符串缓冲区。字符串长度最大不超过长度size。如果超过或等于,则只写入size-1个,后面补个'�'。
所属库文件:<stdio.h>
参数:(1)str,将要写入数据的起始地址;(2)size,写入数据的最大长度(实际写入肯定小于等于此值,包括'�');(3)format,写入数据的格式;(4)argument(省略号),要写的数据
例如:
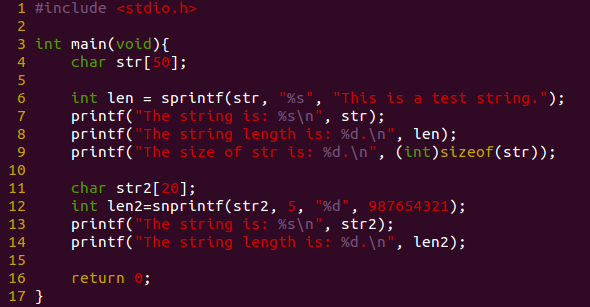
运行后结果为
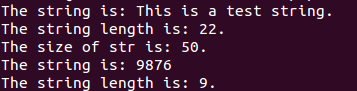
需要注意的是,snprintf返回值是format过后字符串的长度,并不是实际拷进字符串缓冲区的长度。
C语言常用函数strlen的使用方法
函数声明:extern unsigned int strlen(char *s);
所属函数库:<string.h>
功能:返回s所指的字符串的长度,其中字符串必须以’�’结尾
参数:s为字符串的初始地址
使用举例:
代码如下
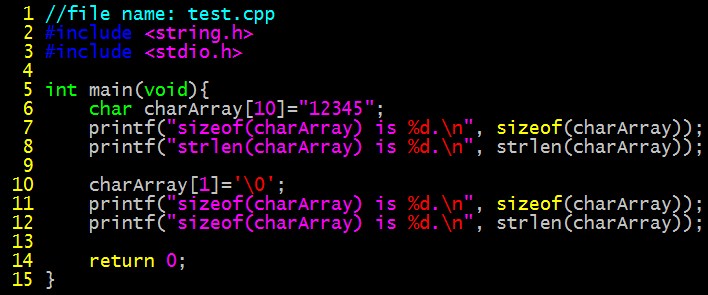
编译运行结果

说明:
函数strlen比较容易理解,其功能和sizeof很容易混淆。其中sizeof指的是字符串声明后占用的内存长度,它就是一个操作符,不是函数;而strlen则是一个函数,它从第一个字节开始往后数,直到遇见了’�’,则停止。
C语言常用函数memset的使用方法
函数声明:void *memset(void *s, int ch, size_t n);
用途:为一段内存的每一个字节都赋予ch所代表的值,该值采用ASCII编码。
所属函数库:<memory.h> 或者 <string.h>
参数:(1)s,开始内存的地址;(2)ch和n,从地址s开始,在之后的n字节长度内,把每一个字节的值都赋值为n。
使用举例:
代码如下
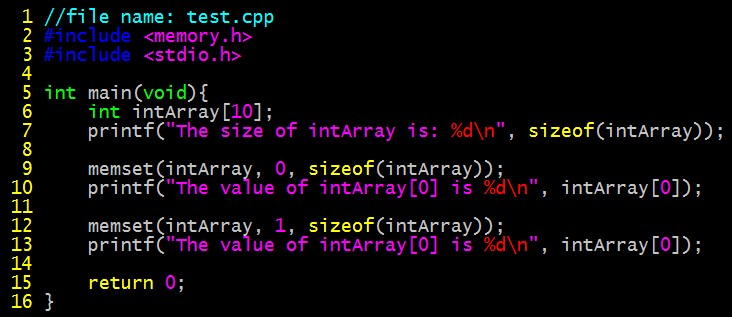
编译运行结果

说明:
该函数最常用的用途就是将一段新分配的内存初始化为0。例如我们代码的第9-10行。
需要注意的是,函数第二个参数的值代表的是即将设置的每个字节的值,因此对于第二个参数不是0的情况要格外小心。例如我们代码的第12-13行。intArray[0]本来是一个四字节的整数,它的每一个字节都将变成1。第12行运行完毕,intArray[0]的内容如下
(二进制)00000001 00000001 00000001 00000001 = (十进制)16843009
这也是为什么第13行输出的结果是16843009。