大家都知道大名鼎鼎的Selenium,是一个用于Web应用程序自动化测试工具。可以帮助测试人员解决回归测试和多浏览器兼容性测试的问题,通过自动化脚本来提升测试效率,今天本文来介绍下Selenium的另外的一个应用小场景,网页内容爬取。
说到爬虫,大家应该并不陌生,Python下面用requests库就可以实现,但是如果你对接口测试只是不是很熟悉,用Selenium来简单爬取下页面上的内容也是一个很便捷的方案,毕竟Selenium入门上手还是很简单的。
Selenium环境不会搭建的小伙伴请自行百度下环境搭建的步骤,本文不对基础环境搭建进行讲解哦。
下面我们以Testfan社区(ask.testfan.cn)为例,介绍下如何使用Selenium自动化工具实现简单的爬虫功能,我们先用Python脚本实现下,Java代码类似,主要借鉴代码逻辑思路即可。我们的需求是把testfan社区文章模块下的前面N页的文章爬取下来(文章标题和每个文章的url,文章模块的地址是http://ask.testfan.cn/articles)
首先我们分析下testfan社区文章模块的url格式,我先随便翻几页看看:

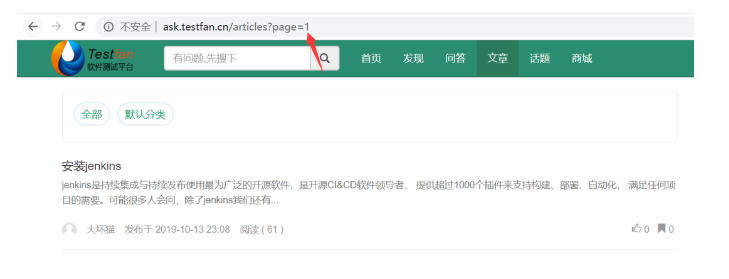
上面的图,这是第2页
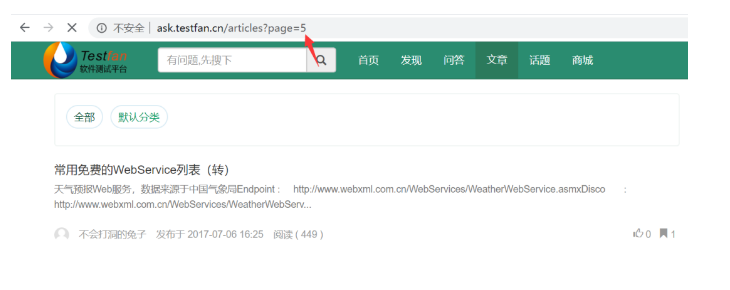
上面的图,这是第5页
分析上面2个页面的url,我们发现http: // ask.testfan.cn /articles?page= 2 //此处的page=2是控制的翻页的页码,也就是说如果我想看第1的文章,那我把page=2改成page=1就可以了,以此类推
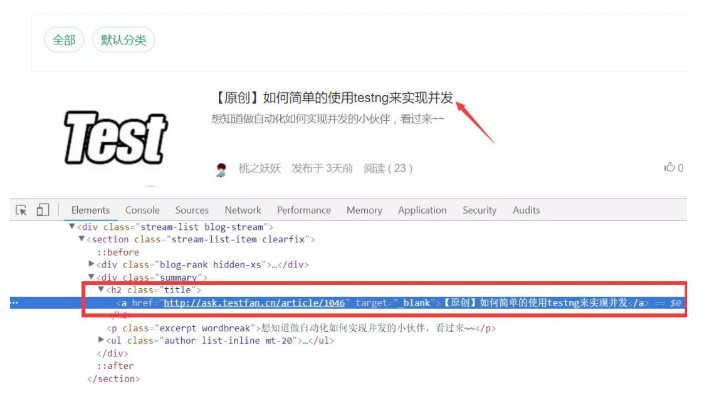
接下来我们分析下每页中的文章标题在dom里的位置和结构,我们想获取每个文章的标题文本和文章的url链接,此处的定位方式很多,自己练习下,本文代码案例采用css定位方式。

咱们接着说,css去描述完文章标题所在的链接元素是这样的(是不是很简洁,一下子能定位到当前页的几十个文章):".title > a",然后获取链接元素的href属性和元素的文本信息即可。
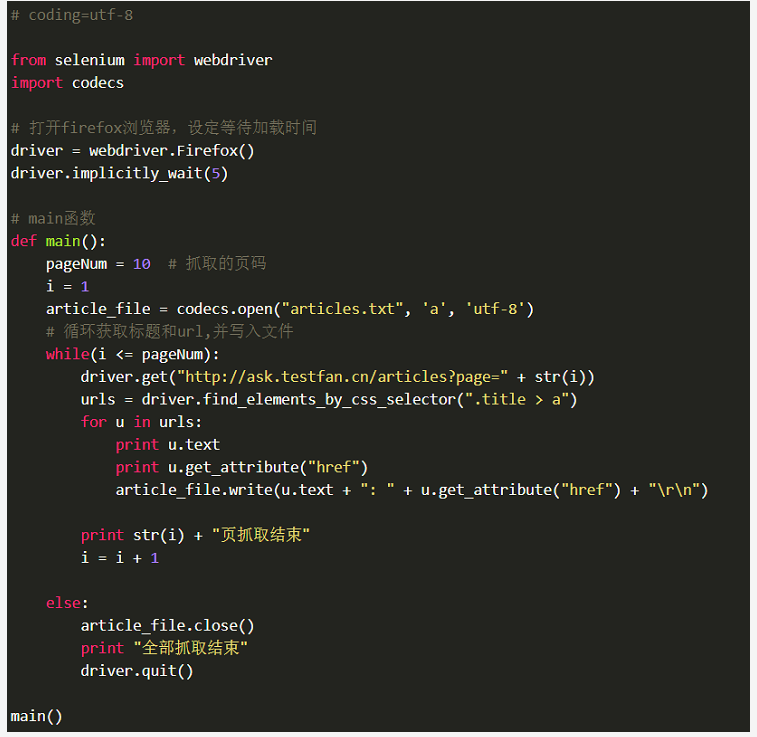
剩下的就是循环打印当前页每个文章的标题和URL并保存到文件中了,当搞定当前页面后,更新下一个页面的URL再继续就可以了。
代码实现逻辑参考如下:
有的同学会说那Selenium基于实体浏览器基于页面回放可能爬取速度会比较慢一些,这里推荐2个虚拟浏览器(无界面的), HtmlUnit和PhantomJS,他们都不是真正的浏览器,运行时不会渲染页面显示内容,但是支持页面元素查找,js的执行等;由于不进行css和gui渲染,运行效率要比真实的浏览器要快很多。
那下面这个代码案例就是Java脚本配合HtmlUnitDriver提高运行效率后代码,逻辑和上面的Python+FF浏览器是一样的,大家自行参考逻辑即可
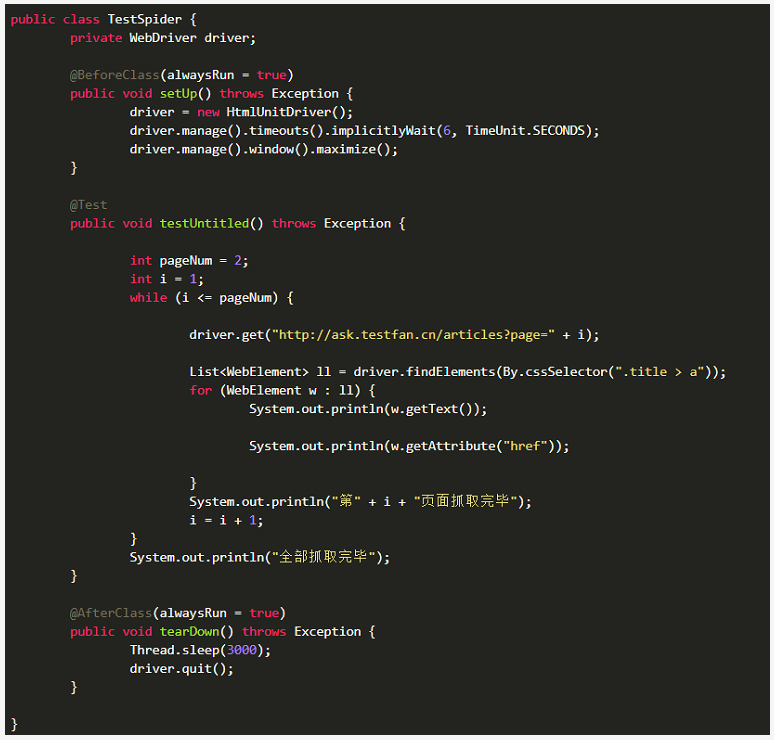
写在最后,爬虫有风险,爬取须谨慎!