1、grep----文本搜索
grep (global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。用于过滤/搜索的特定字符。可使用正则表达式能多种命令配合使用,使用上十分灵活。
语法:
grep [OPTIONS] [PATTERN] [FILE...]
也可以结合管道符“|”使用
[OPTIONS]常用选项:
-i 忽略大小写(ignore)
-n 显示匹配内容所在行号(num)
-c 如果匹配成功,则将匹配到的总行数打印出来(count)
-E 等于egrep,能使用扩展(Extend)正则表达式
-F 不支持正则,按字面意思匹配
-A n 显示匹配到的字符串所在的行及其后n行(After)
-B n 显示匹配到的字符串所在的行及其前n行(Before)
-C n 显示匹配到的字符串所在的行及其前后n行(Context)
-o 只显示被模式匹配到的字符串
-v 反向匹配,也就是对匹配取反(invert)
-f 指定需要匹配的文件(file)
-r 递归搜索
-w 匹配单词(word)
-l 如果匹配成功,则只将文件名打印出来,失败则不打印,通常-rl一起用,grep -rl 'root' /etc
[PATTERN]常用模式:
- 直接输入要匹配的字符串,如 匹配一下hello.c文件中printf的个数:
grep -c "printf" hello.c - 使用基本正则表达式
- 使用扩展正则表达式,需用egrep或-E选项
实例:

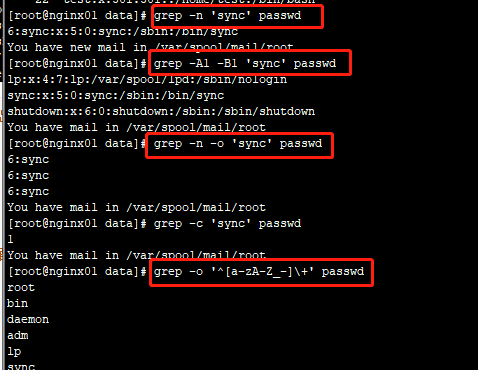
#匹配指定内容并且打印出行号,如sync(结果会打印出整行)
grep -n 'sync' passwd
#将匹配行的前一行和后一行内容都打印出来
grep -A1 -B1 'sync' passwd
#只输出文件中匹配到的部分 -o 选项(结果会打印匹配到的字符串)
grep -n -o 'sync' passwd
#统计文件或者文本中包含匹配字符串的行数-c 选项c
grep -c 'sync' passwd
#仅输出用户名(第1列),如cut命令
grep -o '^[a-zA-Z_-]+' passwd
2、sed----文件编辑
sed 是stream editor的缩写 ,不同于vim,是 非交互流式文本编辑器;
工作原理:在处理文本时是逐行读取文件内容到模式空间(pattern space),读到匹配的行就根据指令做操作,不匹配就跳过处理
语法:
sed [options] “pattern sed-commands” [file]
[OPTIONS]常用选项:
-e<script>或--expression=<script> 以选项中指定的script来处理输入的文本文件。
-f<script文件>或--file=<script文件> 以选项中指定的script文件来处理输入的文本文件。
-h 显示帮助。
-n 静默模式。sed默认会输出所有文本内容,使用-n参数后只显示处理过的行
-r 支持扩展正则表达式
-i 直接修改原文件,不加处理的不是原文件而是原文件的拷贝
[pattern]常见模式:
#匹配模式(地址界定)
$ 最后一行
5 只处理第5行
5,10 只处理第5行到第10行
/pattern1/ 只处理能匹配pattern1的行
/pattern1/,/pattern2/ 只处理从匹配pattern1的行到pattern2的行
first~step 指定起始行,以及步长,如 每隔一行打印一次:sed -n "1~2 p" test.txt
[sed-commands]常用命令:
a 追加 (向匹配行后面插入内容),如a文本,用文本追加匹配到的行
c 替换行 (更改匹配行的内容),如c文本,用文本替换匹配到的行(整行)
d 删除 (删除匹配的内容)
= 用来打印被匹配的行的行号
i 插入 (向匹配行前插入内容)
n 读取下一行,遇到n时会自动跳入下一行
p 打印 (打印出匹配的内容,通常与-n选项合用,默认会输出两遍内容,一遍来自本身文本,一遍来自模式空间)
r,w 读和写编辑命令,r用于将内容读入文件,w用于将匹配内容写入到文件
s 替换字符 (替换掉匹配的内容),如s/regexp/replacement/:替换由regexp所匹配到的内容为replacement,如果没有给模式那么就会把每一行碰到的第一个匹配字符串给替换掉,可以替换界定符,如/,@,#
g:全局匹配
i:忽略大小写
w:写入文本,如w file
实例:
a、向文件中添加和插入行--a
sed '3a "hello"' passwd #向第三行后面添加“hello”
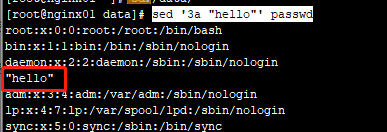
sed '/sync/a hello' passwd #向内容sync所在行后面添加hello,如果文件中有多行包括sync,则每一行后面都会添加
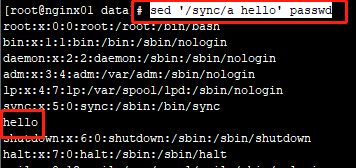
sed '2a welcome back!hello emma!' passwd
sed '$ihello' passwd #在最后一行之前插入hello
b、 替换文件中指定的行 --c
sed "1c hello" passwd #将文件的第一行替换为hello
sed "/sync/c hello" passwd #将包含123的行替换为hello
sed '$c hello' passwd #将最后一行替换为hello
c、删除文件中的行--d
sed '4d' passwd #删除第四行
sed '1~2d' passwd #从第一行开始删除,每隔2行就删掉一行,即删除奇数行
sed '1,2d' passwd #删除1~2行
sed '1,2!d' passwd #删除1~2之外的所有行
d、替换文本字符--s
sed 's/bin/emma/' passwd
e、获取网卡ip
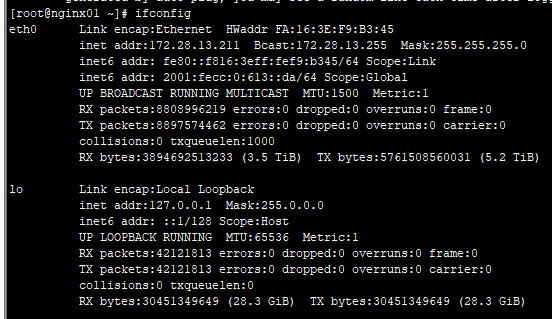
方法一:使用cut命令
ifconfig eth0|grep 'inet addr'|cut -d":" -f2|cut -d" " -f1

方法二:使用sed命令
#利用了 -e 可以将多个 sed 命令联合起来使用,删除除匹配到的行+非数字开头的将它替换为空+空格开头的就它替换为空
ifconfig eth0|sed -e '/inet addr/ !d' -e 's/[^0-9]*//' -e 's/ .*//'
#以非数字开头的将它替换为空,再将以数字开头的后面全部去除掉
ifconfig eth0|sed -e '/inet addr/ !d;s/[^0-9]*//;s/ .*//'

其他可参考
3、awk----文本分析工具
可以理解成cut命令的进阶,强大到能当成一种编程语言使用,可以用来生成报告;
工作原理:awk 是以文件的一行内容为处理单位的。awk读取一行内容,然后根据指定条件判断是否处理此行内容,若此行文本符合条件,则按照动作处理文本,否则跳过此行文本,读取下一行进行判断。
语法:
#简单理解成:awk ' 条件 {动作 }' 文件名
awk [options] “pattern awk-commands” [file]
#如:awk -f <脚本文件> [file]
#简单理解成:awk BEGIN{} ' 条件 {动作 }' END{} 文件名
awk BEGIN{} {pattern} {awk-commands} END{} [file]
awk脚本时,需要注意两个关键词BEGIN和END,命令行和脚本写法会有不同
- BEGIN{ 这里面放的是执行前的语句 }
- END {这里面放的是处理完所有的行后要执行的语句 }
- {这里面放的是处理每一行时要执行的语句}
[pattert]常见模式or 条件:
/pattern1/ 只处理能匹配pattern1的行
/pattern1/,/pattern2/ 只处理从匹配pattern1的行到pattern2的行
条件:
- 正则表达式
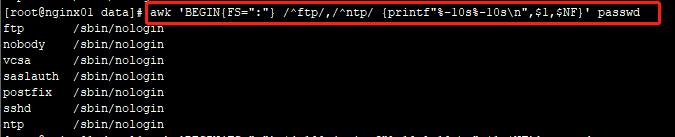
awk 'BEGIN{FS=":"} /^ftp/,/^ntp/ {printf"%-10s%-10s
",$1,$NF}' passwd
#以冒号为分隔符,取出以ftp开头的行到以ntp开头的行间的第1列和最后列字段
# /正则/ 对整行匹配
# $n~/正则/ 对某一列匹配,如$1~/root/ 对第一列匹配是否包含root
- if语句
awk 'BEGIN{FS=":"} {if($4>100) printf"%-10s%-10s
",$1,$4}' passwd
#以冒号为分隔符,取出第4列大于100的行的第1列和第4列字段
#awk 支持if语句
# if (判断){指令}
# if (判断){指令}else {指令}
# if (判断){指令}else if (){指令}

- 布尔值判断
awk 'BEGIN{FS=":"} $4>100 {printf"%-10s%-10s
",$1,$4}' passwd
#以冒号为分隔符,取出第4列大于100的行的第1列和第4列字段

变量:
内置变量:
| 变量 | 描述 |
|---|---|
| $n | 当前行的第n列,字段间由FS分隔,如$1、$2、$3代表第一个字段、第二个字段、第三个字段 |
| $0 | 完整的输入记录 |
| ARGC | 命令行参数的数目 |
| ARGIND | 命令行中当前文件的位置(从0开始算) |
| ARGV | 包含命令行参数的数组 |
| CONVFMT | 数字转换格式(默认值为%.6g)ENVIRON环境变量关联数组 |
| ERRNO | 最后一个系统错误的描述 |
| FIELDWIDTHS | 字段宽度列表(用空格键分隔) |
| FILENAME | 当前文件名 |
| FNR | 各文件分别计数的行号 |
| FS | Field Separator,字段分隔符(默认是任何空格) |
| IGNORECASE | 如果为真,则进行忽略大小写的匹配 |
| NF | Number Field,当前行的字段个数,如$NF就代表最后一个字段,$(NF-1)代表倒数第二个字段 |
| NR | Number Row,当前处理的行号,从1开始 |
| OFMT | 数字的输出格式(默认值是%.6g) |
| OFS | 输出字段的分隔符,用于打印时分隔字段,默认为空格 |
| ORS | 输出记录分隔符(默认值是一个换行符) |
| RLENGTH | 由match函数所匹配的字符串的长度 |
| RS | Row Separartor,行分隔符,用于分割每一行,默认是换行符 |
| RSTART | 由match函数所匹配的字符串的第一个位置 |
| SUBSEP | 数组下标分隔符(默认值是/034) |
运算符
| 运算符 | 描述 |
|---|---|
| = += -= *= /= %= ^= **= | 赋值 |
| ?: | C条件表达式 |
| || | 逻辑或 |
| && | 逻辑与 |
| ~ 和 !~ | 匹配正则表达式和不匹配正则表达式 |
| < <= > >= != == | 关系运算符 |
| 空格 | 连接 |
| + - | 加,减 |
| * / % | 乘,除与求余 |
| + - ! | 一元加,减和逻辑非 |
| ^ *** | 求幂 |
| ++ -- | 增加或减少,作为前缀或后缀,未赋值的话从0开始 |
| $ | 字段引用 |
| in | 数组成员 |
函数:
-
print 和 printf
awk中同时提供了print和printf两种打印输出的函数。
print函数,参数可以是变量、数值或者字符串。字符串必须用双引号引用,参数用逗号分隔。如果没有逗号,参数就串联在一起而无法区分。这里,逗号的作用与输出文件的分隔符的作用是一样的,只是后者是空格而已。
printf函数,其用法和c语言中printf基本相似,可以格式化字符串,输出复杂时,printf更加好用,代码更易懂。其中%s,%d,%f与python相似,“+”右对齐(默认),“-”左对齐
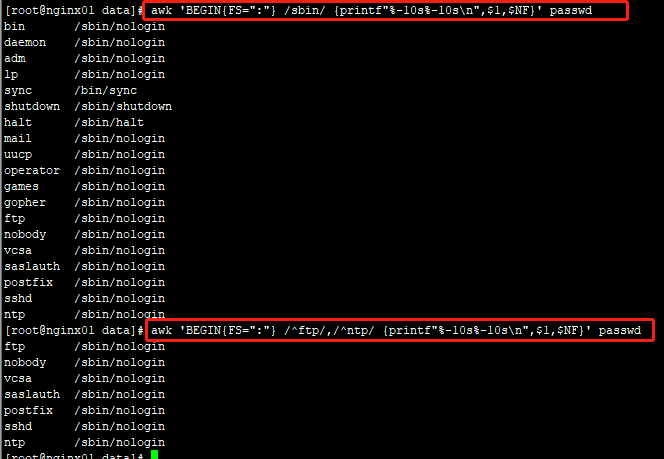
#以冒号为分隔符打印第一个和最后一个字段
#写法一
awk -F ':' '{printf"%-10s%-10s
",$1,$NF}' passwd
#写法二
awk 'BEGIN{FS=":"} {printf"%-10s%-10s
",$1,$NF}' passwd
- 其他函数
- toupper():字符转为大写。
- tolower():字符转为小写。
- length():返回字符串长度。
- substr():返回子字符串。
- substr($1,2):返回第一个字段,从第2个字符开始一直到结束。
- substr($1,2,3):返回第一个字段,从第2个字符开始开始后的3个字符。
- sin():正弦。
- cos():余弦。
- sqrt():平方根。
- rand():随机数。
实例:
1、打印运行日志线程名及调用次数

BEGIN{
printf "%-30s%-10s
","Treadname","Total"
}
{
name[$6] +=1 #AWK 数组,索引可以是数字或字符串
}
END{
for (u in name){
printf "%-30s%-10s
",u,name[u]
}
}

2、统计每位测试人员执行用例的总数

BEGIN{
printf "%12s%12s
","Tester","CaseTotal"
}
{
USERS[$4] +=1
}
END{
for (u in name){
printf "%-12s%-12s
",u,name[u]
}
}
对于USERS[$4] +=1
在awk中,对于未初始化的数组变量,在进行数值运算的时候,会赋予初值0,因此USERS[$4]=0;
awk处理第一行时: 先读取USERS["keke"]值再+1,USERS["keke"]即0+1=1;
awk处理第二行时: 先读取USERS["lemon"]值再+1,USERS["lemon"]即0+1=1;
awk处理第三行时: 先读取USERS["keke"]值再+1,USERS["keke"]即1+1=2;
.............
最后实现的效果就是对于$4是出现字符串进行计数
3、分别统计每位测试人员执行用例成功和失败的总数,执行用例CRITICAL、ERROR日志等级的总数及各项的总数
BEGIN{
printf "%-12s%-12s%-15s%-12s%-12s%-12s
","Tester","CaseTotal","SuccessTotal","FailTotal","CTotal","ETotal"
}
{
USERS[$4] +=1
if ($5=="pass"){
succ[$4]+=1
}else if ($5=="fail"){
fail[$4]+=1
}
if ($3=="CRITICAL"){
cri[$4]+=1
}else if ($3=="ERROR"){
error[$4]+=1
}
END{
for (u in name){
allname +=name[u]
allsucc +=succ[u]
allfail +=fail[u]
allcri +=cri[u]
allerr +=error[u]
printf "%-12s%-12d%-15d%-12d%-12d%-12d
",u,name[u],succ[u],fail[u],cri[u],error[u]
}
printf "%-12s%-12d%-15d%-12d%-12d%-12d
","Total",allname,allsucc,allfail,allcri,allerr
}