http://blog.csdn.net/yerenyuan_pku/article/details/72801777
商品添加的实现,包括商品的类目选择,即商品属于哪个分类?还包括图片上传,对于图片上传这个功能,我们准备搭建一个图片服务器,专门保存图片。淘淘商城系列将使用分布式文件系统FastDFS。
什么是FastDFS?
FastDFS是用c语言编写的一款开源的轻量级分布式文件系统。它对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。特别适合以文件为载体的在线服务,如相册网站、视频网站等等。
FastDFS为互联网量身定制,充分考虑了冗余备份、负载均衡、线性扩容等机制,并注重高可用、高性能等指标,使用FastDFS很容易搭建一套高性能的文件服务器集群提供文件上传、下载等服务。
对于FastDFS,我也有我个人的理解:FastDFS是用c语言编写的一款开源的分布式文件系统,hadoop也是一个分布式文件系统,hadoop是处理大数据的,什么是大数据呢?就是海量数据。海量数据你一块磁盘估计存不下,那么就需要把数据存到多个磁盘上,还得统一管理,这时就需要一个分布式文件系统来管理。FastDFS同样也是这么一个意思,图片我们有很多,但容量有上限,所以我们要把这些所有的图片存储到多台服务器上,还要进行统一管理,那么就需要一个分布式文件系统,很显然那就是FastDFS了,FastDFS适合于存取图片。
FastDFS架构
下面来看一张FastDFS的架构图,如下图所示。FastDFS架构包括Tracker server和Storage server。客户端请求Tracker server进行文件上传、下载,通过Tracker server调度最终由Storage server完成文件上传和下载。Tracker server的作用是负载均衡和调度,通过Tracker server在文件上传时可以根据一些策略找到Storage server提供文件上传服务,可以将tracker称为追踪服务器或调度服务器。Storage server作用是文件存储,客户端上传的文件最终存储在Storage服务器上,Storage server没有实现自己的文件系统而是利用操作系统的文件系统来管理文件,可以将storage称为存储服务器。 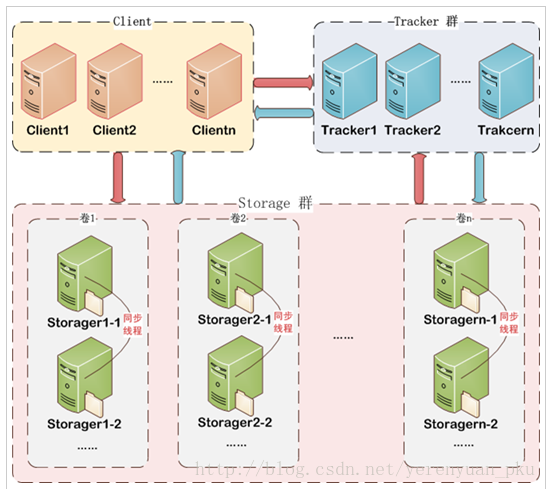
我们从上图还能看到,Client端可以有多个,也就是同时支持多个客户端对FastDFS集群服务进行访问,Tracker是跟踪器,负责协调Client与Storage之间的交互,为了实现高可用性,需要用多个Tracker来作为跟踪器。Storage是专门用来存储东西的,而且是分组进行存储的,每一组可以有多台设备,这几台设备存储的内容完全一致,这样做也是为了高可用性,当现有分组容量不够时,我们可以水平扩容,即增加分组来达到扩容的目的。另外需要注意的一点是,如果一组中的设备容量大小不一致,比如设备A容量是80G,设备B的容量是100G,那么这两台设备所在的组的容量会以小的容量为准,也就是说,当存储的东西大小超过80G时,我们将无法存储到该组中了。Client端在与Storage进行交互的时候也与Tracker cluster进行交互,说的通俗点就是Storage向Tracker cluster进行汇报登记,告诉Tracker现在自己哪些位置还空闲,剩余空间是多大。
文件上传的流程
现给出一张文件上传的时序图,如下图所示: 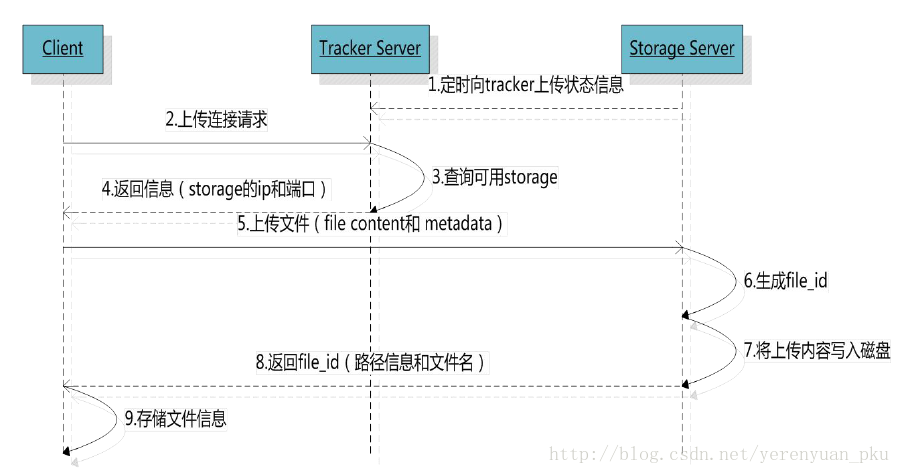
从中可以看到,Client想上传图片,它先向Tracker进行询问,Tracker查看一下登记信息之后,告诉Client哪个storage当前空闲,Tracker会把IP和端口号都返回给Client,Client在拿到IP和端口号之后,便不再需要通过Tracker,直接便向Storage进行上传图片,Storage在保存图片的同时,会向Tracker进行汇报,告诉Tracker它当前是否还留有剩余空间,以及剩余空间大小。汇报完之后,Storage将服务器上存储图片的地址返回给Client,Client可以拿着这个地址进行访问图片。说得更加细致一点,客户端上传文件后存储服务器将文件ID返回给客户端,此文件ID用于以后访问该文件的索引信息。文件索引信息包括:组名,虚拟磁盘路径,数据两级目录,文件名,如下所示:

- 组名:文件上传后所在的storage组名称,在文件上传成功后由storage服务器返回,需要客户端自行保存。
- 虚拟磁盘路径:storage配置的虚拟路径,与磁盘选项
store_path*对应。如果配置了store_path0则是M00,如果配置了store_path1则是M01,以此类推。 - 数据两级目录:storage服务器在每个虚拟磁盘路径下创建的两级目录,用于存储数据文件。
- 文件名:与文件上传时不同。是由存储服务器根据特定信息生成,文件名包含:源存储服务器IP地址、文件创建时间戳、文件大小、随机数和文件拓展名等信息。
文件下载的流程
现给出一张文件下载的时序图,如下图所示: 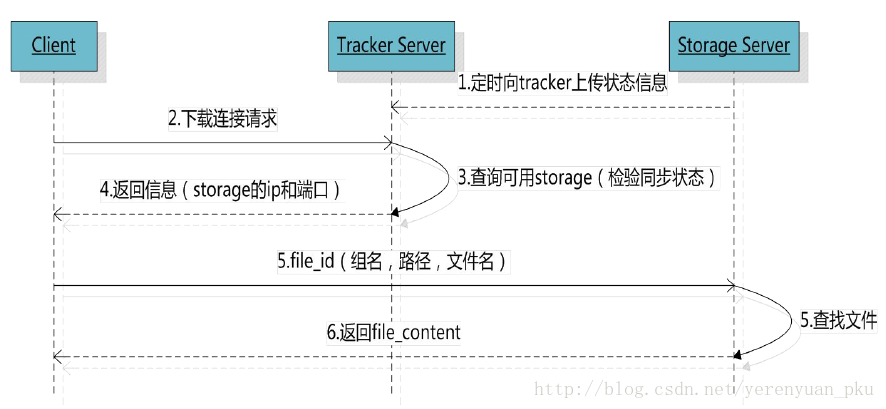
文件下载的步骤可以是:
- client询问tracker下载文件的storage,参数为文件标识(组名和文件名)。
- tracker返回一台可用的storage。
- client直接和storage通讯完成文件下载。